Figure 1:Explainer Infographic: Chapter 8: Vibe Coding.
1Chapter Introduction¶
There is a moment that every new programmer dreads. You open a blank code editor, stare at a blinking cursor, and realize that the distance between what you want the computer to do and what you know how to tell it to do feels impossibly wide. For decades, crossing that gap required years of formal training, syntax memorization, and painstaking trial and error. That gap has not disappeared — but it has been dramatically narrowed by one of the most exciting developments in modern computing: vibe coding.
The term “vibe coding” was introduced into the popular technology lexicon by Andrej Karpathy, a founding member of OpenAI and former Director of AI at Tesla, in early 2025. In a post on the social platform X (formerly Twitter), Karpathy described a new mode of programming in which the developer largely surrenders to an AI system. You describe what you want in plain English (or any natural language), accept the code the AI produces, run it, and iterate — trusting the process, riding the “vibe,” rather than manually controlling every line. The term quickly caught fire because it resonated with a generation of knowledge workers who suddenly found themselves capable of building software without knowing Python, JavaScript, or SQL in the traditional sense.
For graduate students in business analytics, vibe coding is not a gimmick. It is a paradigm shift in how analytical work gets done. It changes what skills are valuable, what kinds of problems are solvable, and how quickly insights can move from idea to implementation. This chapter will give you the conceptual foundation, practical techniques, and critical perspective you need to harness vibe coding effectively — and responsibly — in your careers as analytically empowered business professionals.
28.1 What Is Vibe Coding? A Conceptual Foundation¶
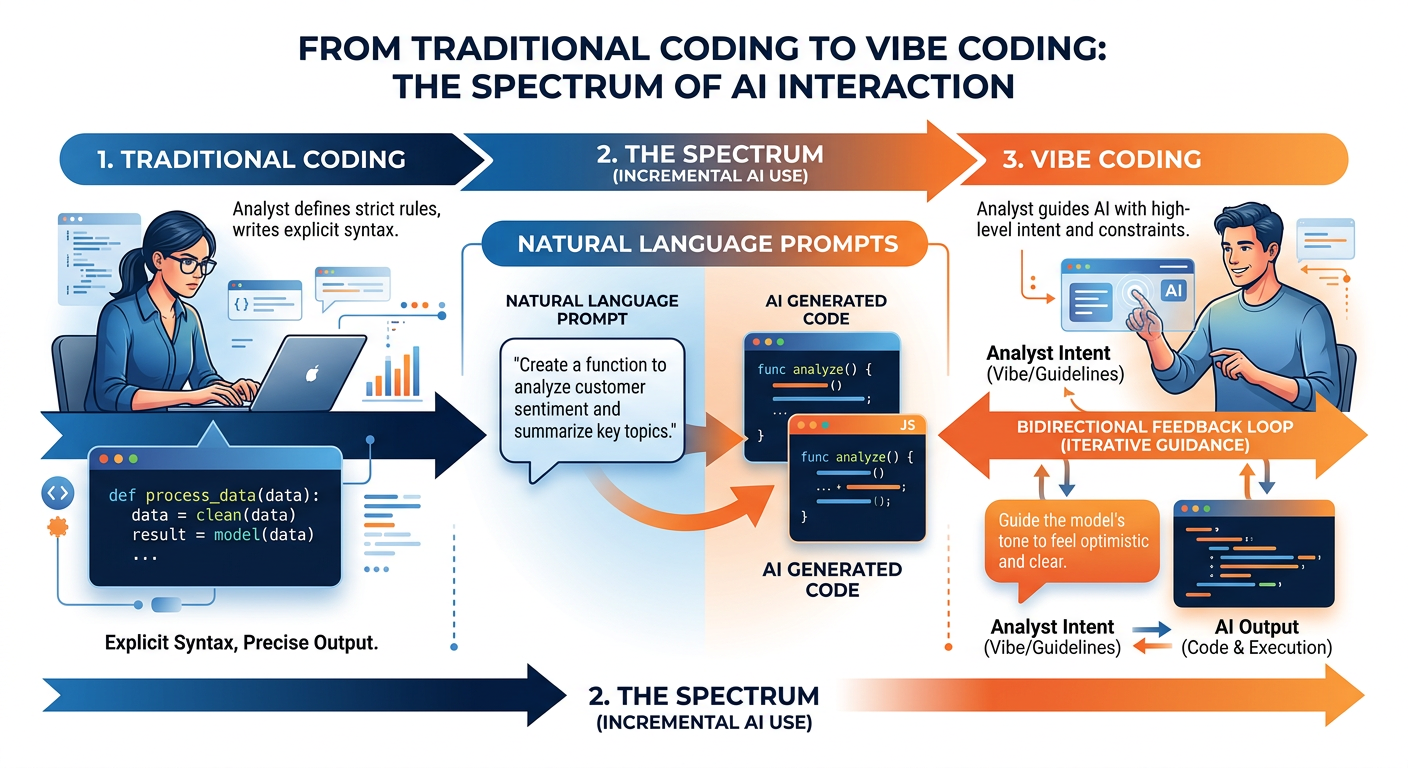
Figure 2:The Vibe Coding Spectrum: From traditional programming to AI-first development.
At its core, vibe coding is the practice of using natural language instructions to direct an AI system — typically a Large Language Model (LLM) — to write, modify, explain, or debug code on your behalf. Rather than translating your intent into precise programmatic syntax yourself, you describe your intent in plain language, and the LLM performs the translation. The resulting code can then be executed, tested, and refined through continued conversation.
It is important to understand that vibe coding is not a single tool or platform. It is a methodology — a way of working — that can be applied using many different tools, including ChatGPT, Claude, GitHub Copilot, Google Gemini, Cursor, Replit, and dozens of others. The unifying element is the use of natural language as the primary interface between the human analyst and the executing machine.
The distinction between vibe coding and traditional programming is not merely one of convenience — it reflects a fundamentally different division of cognitive labor. In traditional programming, the human carries full responsibility for syntax, logic, data structures, error handling, and optimization. In vibe coding, that burden is substantially shifted to the AI, freeing the human to focus on problem formulation, result interpretation, and business judgment.
This does not mean the human becomes passive. In fact, effective vibe coding demands a sophisticated set of skills: the ability to clearly articulate problems, evaluate generated solutions critically, identify errors (even subtle ones), and iterate productively. The human role shifts from writer to director — from operator to strategist.
38.2 The Technology Behind the Vibe: How LLMs Generate Code¶
To use vibe coding intelligently, you must understand something about why it works — and why it sometimes fails spectacularly. LLMs generate code the same way they generate any text: by predicting what tokens (words, punctuation, code characters) are most likely to follow a given sequence, given everything they have been trained on.
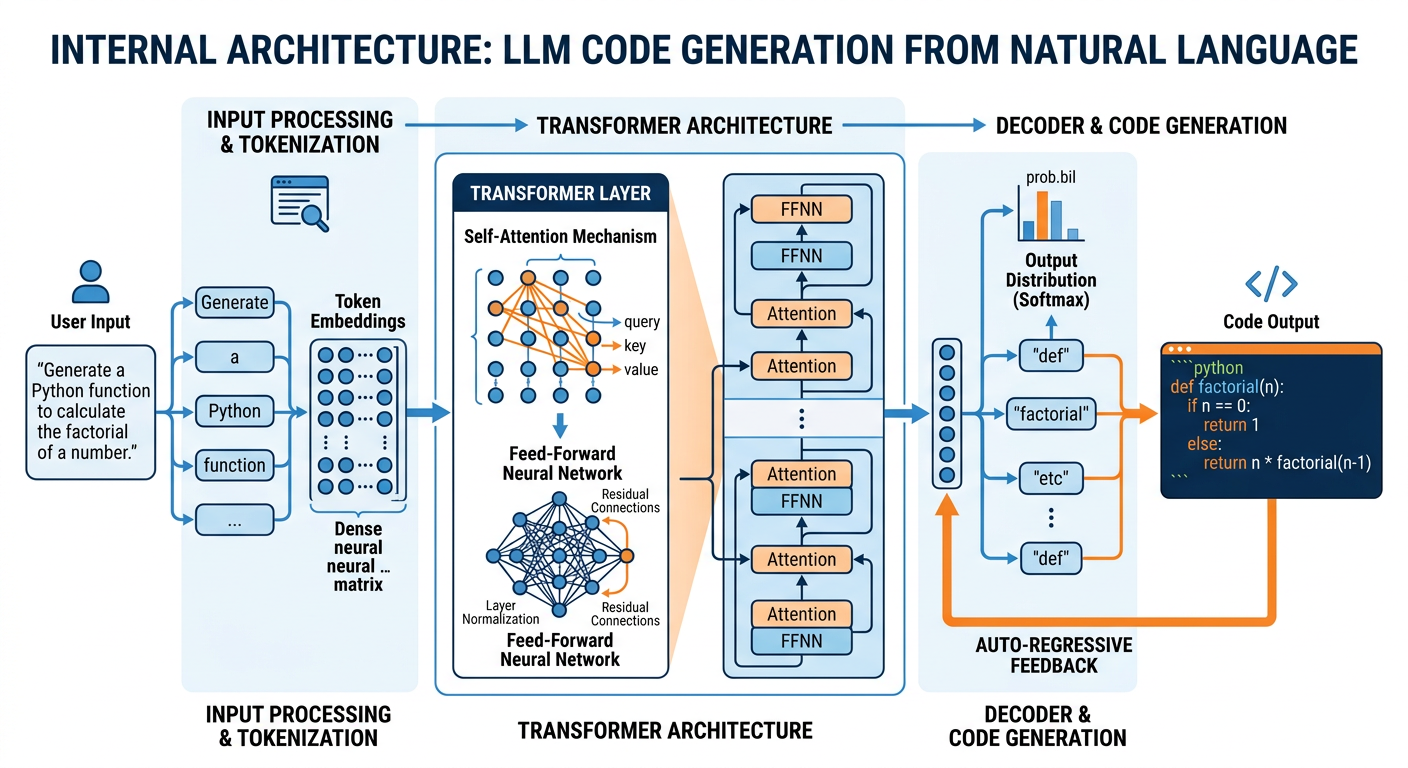
Figure 3:Inside the LLM: From natural language prompt to executable code.
Modern LLMs are trained on enormous datasets that include billions of lines of code from public repositories like GitHub, along with documentation, Stack Overflow threads, academic papers, and tutorials. Through the training process — which involves self-supervised learning on next-token prediction and reinforcement learning from human feedback (RLHF) — these models develop extraordinarily rich representations of programming patterns, idiomatic conventions, and algorithmic logic.
3.18.2.1 Why LLMs Are Surprisingly Good at Code¶
Several properties make LLMs particularly capable at code generation:
Code is structured and consistent. Programming languages follow strict syntactic rules and well-established patterns. Unlike poetry or creative fiction, code tends to be repetitive and rule-governed in ways that make it highly learnable by pattern-matching systems.
Code has abundant training data. GitHub alone hosts hundreds of millions of repositories. LLMs trained on this data have seen an extraordinary variety of programming problems and their solutions.
Code generation benefits from chain-of-thought reasoning. Modern LLMs can be prompted to “think step by step” before producing code, which substantially improves their accuracy on complex logical tasks.
Business analytics code is particularly well-represented. The specific domains most relevant to this course — data manipulation with pandas, visualization with matplotlib and seaborn, statistical analysis with scipy and statsmodels, and machine learning with scikit-learn — are among the most heavily documented and discussed programming topics on the internet. LLMs are exceptionally capable in these domains.
3.28.2.2 Why LLMs Still Make Mistakes¶
Despite their impressive capabilities, LLMs have characteristic failure modes that every vibe coder must understand:
Stale knowledge: LLMs have training cutoffs. They may not know about the latest library versions or recently introduced functions.
Context limits: Very long or complex code projects may exceed the model’s context window, causing it to lose track of earlier decisions.
Over-confidence: The model does not signal uncertainty the way a human expert might. It may produce wrong code just as fluently as correct code.
Logic errors in complex algorithms: While LLMs handle common patterns well, novel or highly complex algorithmic challenges can expose significant gaps.
Understanding these failure modes is not a reason to avoid vibe coding — it is a reason to practice critical AI literacy alongside it.
48.3 Natural Language Programming: A Brief History and the Road to Now¶
The dream of instructing computers in natural language is nearly as old as computing itself. In the 1960s, researchers like J.C.R. Licklider envisioned “man-computer symbiosis” in which humans and computers would work as cognitive partners. Early natural language interfaces for databases emerged in the 1970s and 1980s (LUNAR, NLIDB), but they were brittle, domain-specific, and difficult to scale.
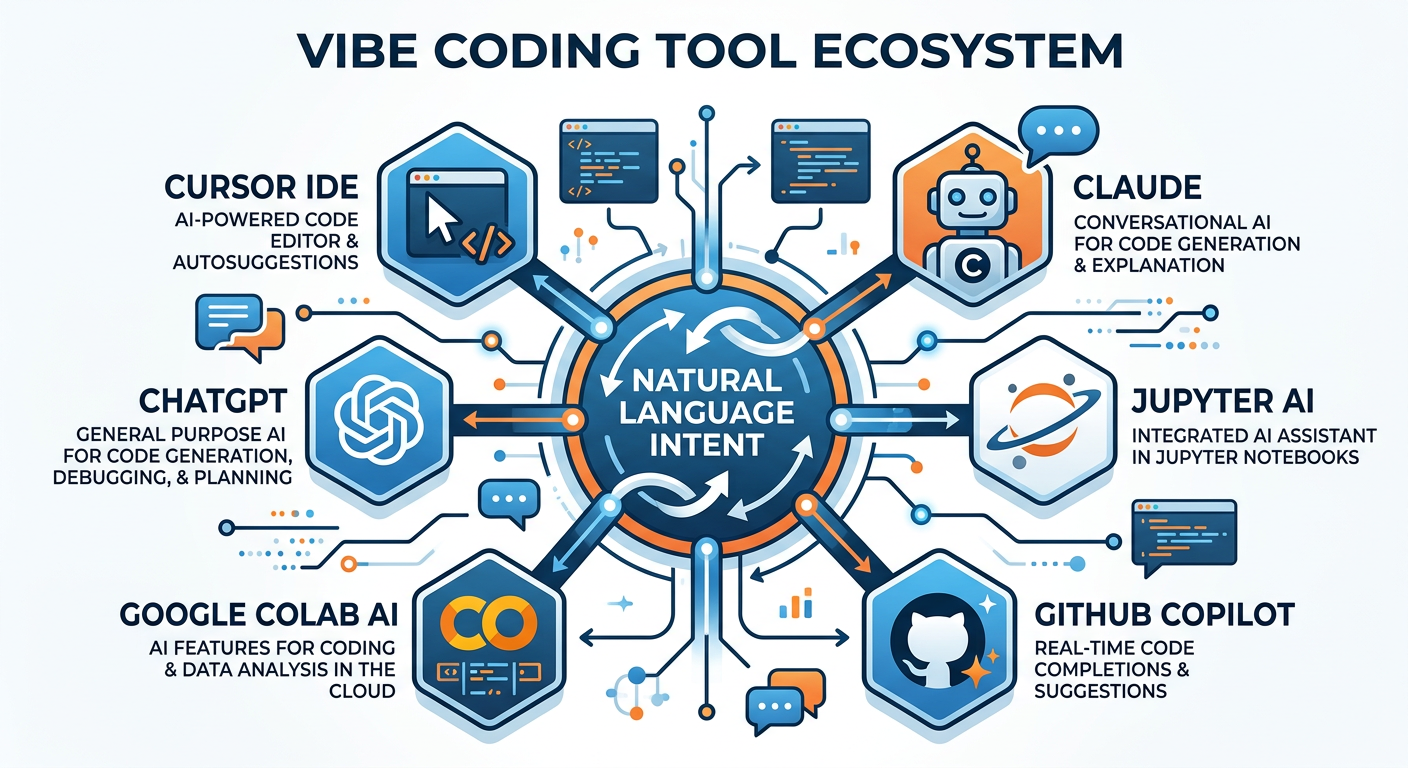
Figure 4:Historical Timeline: The evolution of natural language programming toward vibe coding.
The modern era of natural language programming began in earnest with the release of GPT-3 by OpenAI in 2020. For the first time, a general-purpose language model could generate syntactically correct and semantically meaningful code across multiple programming languages with no domain-specific fine-tuning. OpenAI’s Codex model (2021), trained specifically on code, powered GitHub Copilot — arguably the first widely deployed commercial vibe coding tool — which became available to the public in 2022 and rapidly attracted millions of developers.
The release of ChatGPT in November 2022 brought LLM-powered code generation to a mass audience outside the software development world. Accountants, marketers, biologists, and business analysts suddenly found themselves writing Python scripts — with AI assistance — for the first time. By 2024 and 2025, specialized AI coding environments like Cursor, Replit AI, Bolt.new, and v0 (by Vercel) had pushed the capability even further, enabling the creation of full-stack web applications through conversational interfaces.
The term “vibe coding” captures something important about this cultural moment: programming is no longer a gated skill accessible only to those who have spent years in computer science education. It is becoming a universal capability — like reading and writing — that knowledge workers in every domain can leverage.
58.4 The Business Analytics Context: Why Vibe Coding Matters for You¶
As a graduate student in business analytics, you occupy a particularly strategic position with respect to vibe coding. You are not a software engineer — and you don’t need to be. Your competitive advantage lies in your ability to formulate analytically meaningful questions, understand statistical reasoning, interpret results in business context, and communicate insights to stakeholders. Vibe coding extends that advantage by removing the technical bottleneck between your analytical intent and its implementation.
Consider a few concrete scenarios in which vibe coding creates immediate value for business analytics practitioners:
Scenario 1: Ad-hoc data analysis. A supply chain manager gives you a raw CSV file with 50,000 rows of inventory data and asks for a summary of SKUs that have been below reorder threshold more than three times in the past six months. Historically, answering this question might require either waiting for an IT report or spending several hours writing SQL queries. With vibe coding, you can prompt an LLM: “I have a CSV file with columns: SKU_ID, date, quantity_on_hand, reorder_threshold. Write me Python code using pandas to find all SKUs that have had quantity_on_hand below reorder_threshold more than 3 times in the past 6 months.” Working code appears in seconds.
Scenario 2: Rapid prototyping. Your team is pitching a new customer segmentation model to leadership. You have two days to build a demonstration. Using vibe coding tools, you can prototype a K-means clustering pipeline, generate visualizations, and build a simple interactive dashboard in a fraction of the time traditional development would require.
Scenario 3: Explaining existing code. You inherit a Python script from a former colleague that performs some kind of statistical transformation, but there are no comments and no documentation. You paste it into an LLM and ask: “Explain what this code does, step by step, in plain English.” The LLM produces a clear, readable explanation.
Scenario 4: Translating between tools. You have an analysis in Excel with complex formulas and need to replicate it in Python for automation. Vibe coding makes this translation straightforward, even without deep programming expertise.
68.5 Core Techniques: How to Vibe Code Effectively¶
Effective vibe coding is a skill, and like all skills, it can be developed through deliberate practice. In this section, we cover the foundational techniques that separate productive vibe coders from frustrated ones.
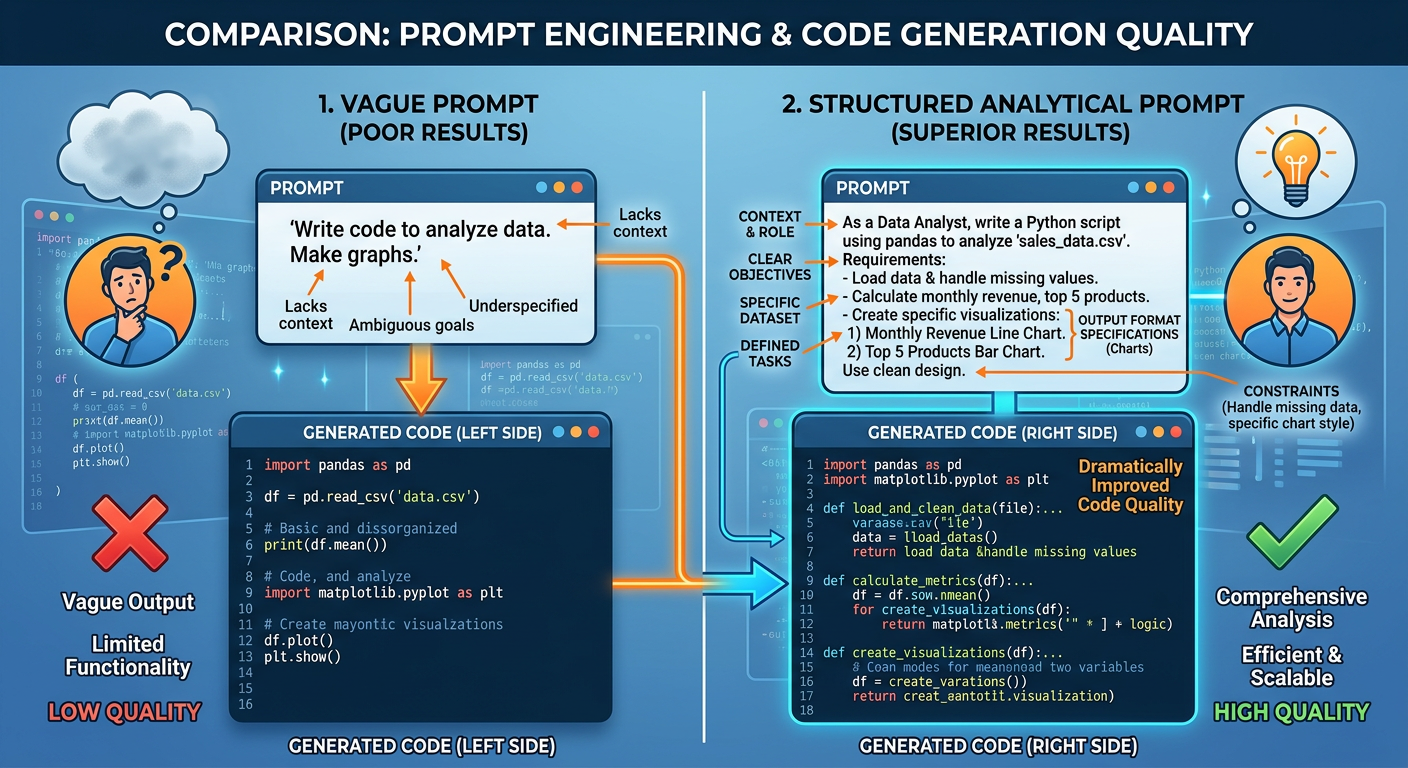
Figure 5:The Five Core Techniques of Effective Vibe Coding.
6.18.5.1 Technique 1: Context Setting¶
The single most important factor in getting useful code from an LLM is the quality of context you provide at the start of the conversation. Think of the LLM as a highly capable but information-starved consultant. The more relevant context you provide, the better the output.
Good context includes:
The programming language and version (e.g., “Python 3.11”)
The libraries you want to use (e.g., “use pandas and matplotlib”)
The structure of your data (e.g., “I have a DataFrame with columns: customer_id, purchase_date, amount, product_category”)
The desired output (e.g., “produce a bar chart showing total revenue by category”)
Any constraints (e.g., “the code should run in a Jupyter notebook” or “avoid using external API calls”)
Compare these two prompts:
Weak prompt: “Write code to analyze my sales data.”
Strong prompt: “I have a CSV file named
sales_q4.csvwith columns:transaction_id(integer),date(YYYY-MM-DD string),region(string: North, South, East, West),product_line(string),revenue(float), andunits_sold(integer). Using Python 3.11 and pandas, write code to: (1) load the CSV, (2) convert the date column to datetime, (3) calculate total revenue and total units sold grouped by region and product_line, and (4) display the results sorted by total revenue descending.”
The second prompt will reliably produce accurate, immediately useful code. The first will produce something generic that requires extensive modification.
6.28.5.2 Technique 2: Incremental Decomposition¶
Complex analytical tasks should be broken into smaller, testable sub-tasks rather than attempted in a single massive prompt. This approach mirrors good software engineering practice and makes it easier to identify where things go wrong.
Instead of: “Build me a complete customer churn prediction model with cross-validation, hyperparameter tuning, and a confusion matrix.”
Try:
“Load and explore this dataset.”
“Handle missing values and encode categorical variables.”
“Split the data into train and test sets.”
“Train a logistic regression model.”
“Evaluate the model and display a confusion matrix.”
Each step can be verified before proceeding, preventing errors from compounding.
6.38.5.3 Technique 3: Paste Errors Directly¶
When generated code produces an error, the most productive response is almost always to paste the complete error message directly back into the conversation and ask the LLM to fix it. This works remarkably well because error messages contain precise diagnostic information that the model can interpret.
Here is the error I got when running your code:
ValueError: could not convert string to float: 'N/A'
File "analysis.py", line 47, in <module>
X = df[features].astype(float)
Please fix the code to handle non-numeric values before the conversion.This direct feedback loop — generate, run, paste error, refine — is the core operational rhythm of effective vibe coding.
6.48.5.4 Technique 4: Ask for Explanations¶
You should never blindly run code that you do not understand, particularly when working with sensitive business data or when results will inform decisions. Make it a habit to ask the LLM to explain what it generated.
“Before I run this, can you explain what each section of this code does, and why you made the choices you did?”
This serves two purposes: it helps you learn, and it helps you catch logical errors that might not produce Python errors but would produce incorrect results.
6.58.5.5 Technique 5: Specify Output Formats¶
LLMs can generate code in many styles. Being explicit about your preferred format avoids unnecessary back-and-forth.
“Please write this as a reusable function with docstrings.”
“Write this as a Jupyter notebook cell, with a markdown cell before it explaining what the code does.”
“Please include inline comments explaining each major step.”
78.6 Prompt Engineering for Analytics: Advanced Strategies¶
Prompt engineering — the craft of designing effective prompts for LLMs — has become a discipline in its own right. For analytics practitioners using vibe coding, several advanced strategies are worth mastering.
Figure 6:Prompt Engineering Framework: Four strategies for better code generation.
7.18.6.1 Role Prompting¶
Assigning the LLM a specific role can substantially improve the quality and relevance of generated code:
“You are a senior data scientist specializing in retail analytics. I need you to help me...”
“Act as a Python expert who writes clean, production-ready code with error handling and docstrings.”
7.28.6.2 Few-Shot Prompting¶
Providing examples of the input-output relationship you want helps the LLM calibrate to your specific needs. This is especially useful for custom data transformations:
"I want to clean address strings. Here are some examples: Input: ‘123 main st, miami fl 33101’ → Output: ‘123 Main St, Miami, FL 33101’ Input: ‘PO BOX 4455 boca raton FL’ → Output: ‘PO Box 4455, Boca Raton, FL’ Write a Python function that applies these transformations to an address column in a pandas DataFrame."
7.38.6.3 Chain-of-Thought Prompting¶
For complex analytical tasks, asking the LLM to reason through the problem before writing code often produces better results:
“Before writing any code, think step by step about how you would approach building a customer lifetime value model from this transaction data. Then write the code based on your reasoning.”
7.48.6.4 Constraint Specification¶
Being explicit about what the code should not do is just as important as specifying what it should do:
“Do not use any external APIs. Do not use seaborn — only matplotlib. The code must run without internet access. Do not hardcode the filename — use a variable.”
88.7 Tools of the Trade: The Vibe Coding Ecosystem¶
The landscape of AI-powered coding tools has exploded in the past three years. While no single tool is best for every purpose, understanding the major categories will help you choose wisely.
Figure 7:The Vibe Coding Tool Ecosystem: Major categories and representative tools.
ChatGPT (OpenAI) — The most widely used general-purpose LLM interface. Supports code generation, explanation, debugging, and execution (with the Code Interpreter/Advanced Data Analysis tool). Excellent for data analysis workflows.
Claude (Anthropic) — Known for particularly strong reasoning, long context windows (up to 200K tokens), and careful code generation. Excellent for complex, multi-step analytical tasks.
Google Gemini — Integrated with Google Workspace, making it particularly useful for teams that work in Google Sheets, Colab, or BigQuery environments.
Best for: Ad-hoc analysis, learning, rapid prototyping, code explanation.
GitHub Copilot — The industry standard for in-editor AI assistance. Available as a plugin for VS Code, JetBrains IDEs, and others. Provides real-time code completion, whole-function generation, and chat-based assistance.
Cursor — A VS Code fork built entirely around AI assistance. Allows natural language editing of existing codebases, chat with your entire project, and autonomous multi-file changes. Rapidly becoming the preferred tool among professional developers.
Tabnine — Privacy-focused AI code completion, popular in enterprise environments with data governance requirements.
Best for: Sustained development work, larger projects, professional-grade code quality.
Google Colab — While not AI-native, Colab integrates with Gemini and supports Python execution in the browser. The standard environment for much business analytics coursework.
Replit — A browser-based IDE with built-in AI assistance. Excellent for quick projects and collaboration.
Jupyter AI — An extension for Jupyter notebooks that brings LLM chat directly into the notebook interface. Available through JupyterLab.
Best for: Teaching, collaboration, environments where local installation is not possible.
Bolt.new — Allows users to build full-stack web applications from a single natural language description. Remarkably capable for building data dashboards and simple applications.
v0 (Vercel) — Specializes in generating React-based front-end components from natural language. Excellent for building interactive analytics dashboards.
Devin (Cognition AI) — An “AI software engineer” capable of autonomous, multi-step coding tasks. Represents the frontier of agentic AI development.
Best for: Application building, full-stack development without deep programming expertise.
98.8 Vibe Coding in the Analytics Workflow: End-to-End Example¶
To make these concepts concrete, let us walk through a complete analytics workflow using vibe coding techniques. Imagine you are a business analyst at a regional retail chain, and your manager has asked you to analyze customer transaction data to identify the top revenue-generating customer segments and visualize seasonal patterns.
9.1Step 1: Data Loading and Exploration¶
You begin by describing your dataset to an LLM:
I have a CSV file called 'transactions_2024.csv' with these columns:
- customer_id: integer
- transaction_date: string in 'YYYY-MM-DD' format
- store_id: integer
- product_category: string (Electronics, Apparel, Home, Grocery, Beauty)
- transaction_amount: float
- loyalty_tier: string (Bronze, Silver, Gold, Platinum)
Write Python code using pandas to:
1. Load the CSV file
2. Convert transaction_date to datetime
3. Display basic descriptive statistics
4. Show the count of missing values in each columnThe LLM generates:
import pandas as pd
# Load the data
df = pd.read_csv('transactions_2024.csv')
# Convert date column
df['transaction_date'] = pd.to_datetime(df['transaction_date'])
# Descriptive statistics
print("=== Descriptive Statistics ===")
print(df.describe(include='all'))
# Missing values
print("\n=== Missing Values ===")
print(df.isnull().sum())
print(f"\nTotal rows: {len(df)}")
print(f"Date range: {df['transaction_date'].min()} to {df['transaction_date'].max()}")9.2Step 2: Segmentation Analysis¶
Now write code to calculate total revenue and transaction count
grouped by loyalty_tier and product_category. Sort by total
revenue descending and display the top 20 combinations.9.3Step 3: Visualization¶
Using matplotlib and seaborn, create a heatmap showing total
revenue by loyalty_tier (rows) and product_category (columns).
Use a blue color palette. Add proper title, axis labels, and
annotate each cell with the revenue value formatted as $X,XXX.9.4Step 4: Seasonal Analysis¶
Add a 'month' column extracted from transaction_date.
Create a line chart showing monthly total revenue for each
loyalty tier. Use different line colors for each tier,
include a legend, and format the y-axis as dollar amounts.This iterative, conversational workflow produces a complete analysis in a fraction of the time traditional development would require. Crucially, at each step the analyst maintains control over the analytical logic — the LLM handles only the syntactic implementation.
108.9 Critical Perspectives: The Limits and Risks of Vibe Coding¶
No technology should be adopted uncritically, and vibe coding is no exception. As a responsible analytics professional, you must understand the significant limitations and risks associated with this approach.
Figure 8:Risk Assessment Matrix for Vibe Coding in Business Analytics Environments.
10.18.9.1 Data Privacy and Security¶
The most serious operational risk in vibe coding is the inadvertent exposure of sensitive data. Many commercial LLMs are cloud-hosted, meaning that any data you paste into a prompt is transmitted to an external server. This creates serious risks when working with:
Personally identifiable information (PII): customer names, email addresses, Social Security numbers
Protected health information (PHI): medical records, insurance data
Proprietary business data: financial projections, strategic plans, trade secrets
FERPA-protected educational records
10.28.9.2 Silent Logical Errors¶
Perhaps the most insidious risk of vibe coding is code that runs without errors but produces wrong answers. A misspecified aggregation, an off-by-one error in a date filter, or an incorrect assumption about how a function handles null values can produce plausible-looking but deeply incorrect results. Because the code appears to work (no error messages), there is a natural tendency to trust it.
This risk is mitigated through:
Testing with known inputs and verifying outputs manually
Asking the LLM to add data validation checks
Applying domain knowledge to sanity-check results
Peer review of generated code before use in production
10.38.9.3 Skill Atrophy and Over-Dependence¶
There is a legitimate concern — widely debated among technology educators — that heavy reliance on vibe coding could atrophy the fundamental programming and analytical skills that underpin genuine expertise. If you cannot read and interpret the code that the AI generates for you, you are entirely dependent on the AI’s reliability for your professional output.
10.48.9.4 Intellectual Property Considerations¶
LLMs are trained on publicly available code, some of which is licensed under copyleft licenses (e.g., GPL). The legal status of AI-generated code with respect to intellectual property is an active area of legal development. For professional and commercial contexts, consult your organization’s legal guidance on AI-generated code.
118.10 The Future of Vibe Coding: Agentic AI and Beyond¶
The vibe coding practices available in 2025 are likely to seem primitive compared to what will be possible within the next few years. The frontier of AI-assisted development is moving rapidly toward agentic systems — AI that can not only generate code but autonomously execute tasks, browse the web, interact with APIs, and iteratively improve its own output without human intervention at each step.
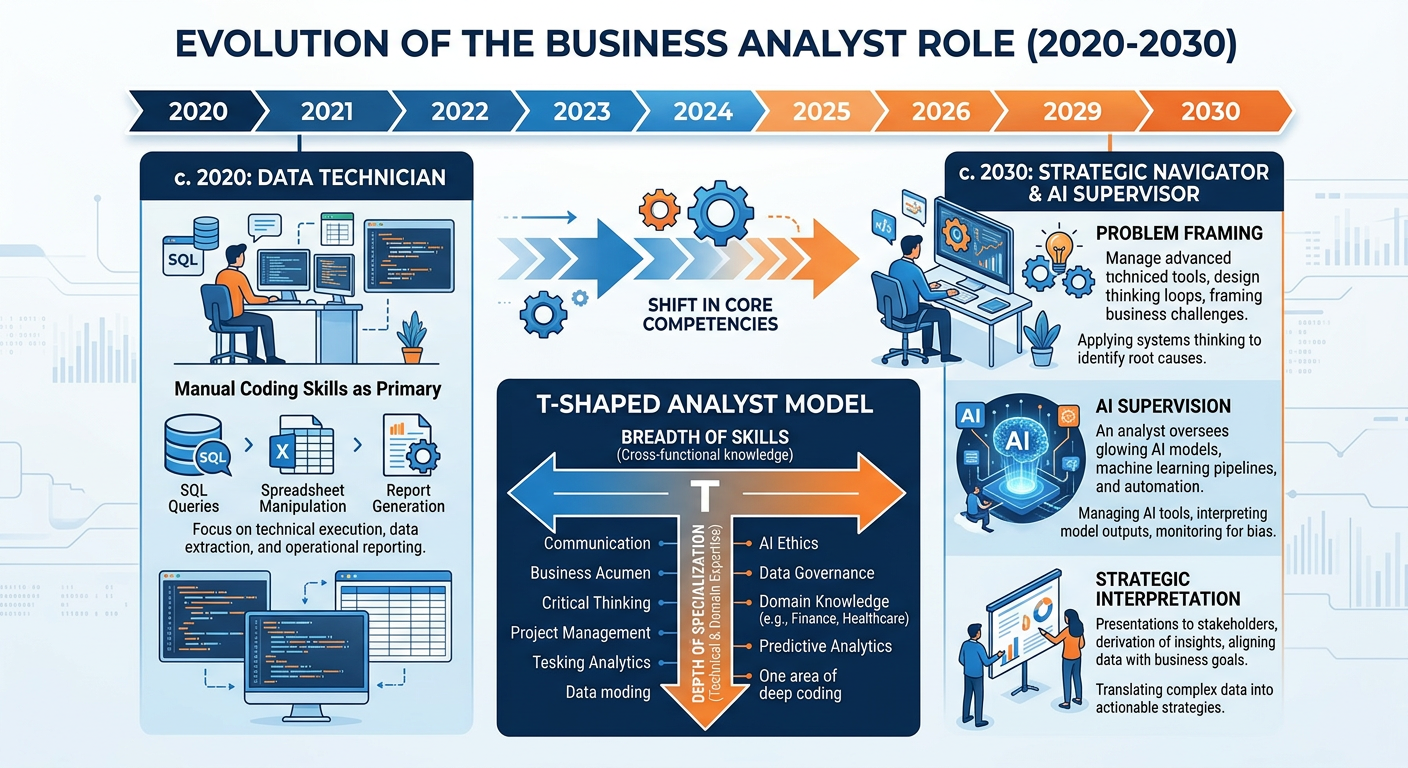
Figure 9:The Evolution Toward Agentic AI Development: Where vibe coding is heading.
Consider what is already possible at the time of writing (2025):
OpenAI’s o3 and GPT-4o can reason deeply about code before generating it, substantially reducing errors on complex tasks
Anthropic’s Claude can maintain context across extremely long interactions, enabling work on large, complex codebases
Cursor’s “Composer” mode allows the AI to edit multiple files simultaneously in response to a high-level instruction
Devin can autonomously browse documentation, install dependencies, write tests, and debug code over extended sessions
For business analytics, the implications are significant. Within the near-term future, it is plausible that an analyst will be able to describe a complete analytical project — “analyze our customer churn data, identify the three most important predictors, build a predictive model, validate it, and produce a PowerPoint-ready summary” — and receive a working, validated solution with minimal human intervention. The analyst’s primary contribution will be problem formulation, business context, and critical evaluation.
This is not a vision of analysts being replaced by AI. It is a vision of analysts being amplified — capable of doing in hours what previously required weeks, and capable of tackling problems whose complexity previously demanded entire teams.
128.11 Building a Vibe Coding Practice: Skills and Habits for the AI Era¶
Given everything we have discussed, how should you, as a business analytics graduate student, actively develop your vibe coding capabilities?
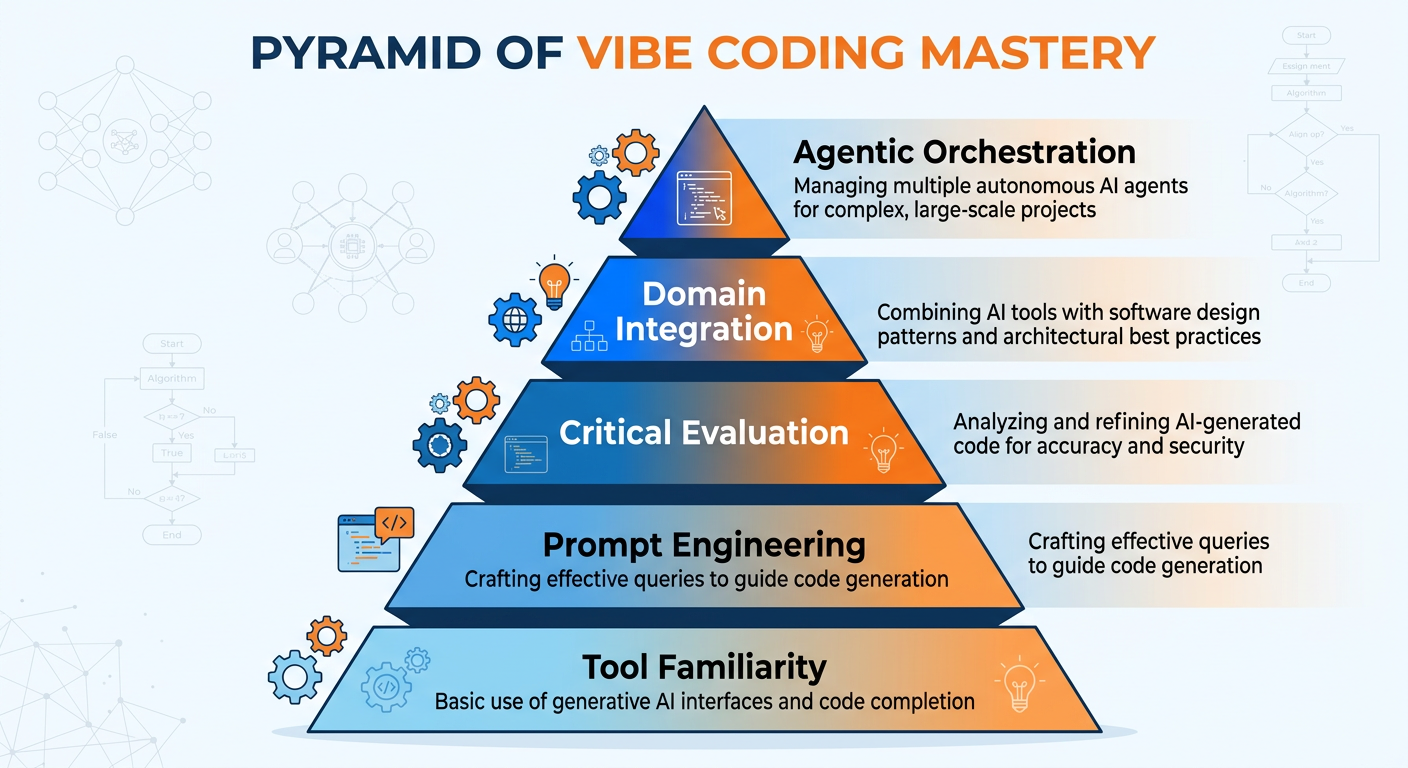
Figure 10:The Vibe Coding Competency Pyramid: Building from foundational knowledge to critical AI evaluation.
12.18.11.1 Layer 1: Foundational Analytics Knowledge¶
Vibe coding does not eliminate the need for foundational knowledge — it makes it more important. You need to know enough about statistics, data structures, and business logic to evaluate whether the code the AI produces is logically sound. You cannot catch a mistake in a logistic regression implementation if you do not understand what logistic regression is supposed to do. You cannot identify a flawed aggregation if you do not understand what the business question requires.
Invest deliberately in your foundational knowledge. Read documentation. Understand the mathematics behind the models you apply. Know the difference between mean and median and when each is appropriate. This foundational layer is what transforms you from a vibe coder who gets lucky into one who gets it right.
12.28.11.2 Layer 2: Prompt Engineering Skills¶
Prompt engineering is a learnable craft. The best way to develop it is through deliberate experimentation: write a prompt, evaluate the output, identify what was missing or miscommunicated, revise the prompt, and repeat. Keep a personal library of prompts that work well for your most common analytical tasks. Over time, you will develop an intuition for how to communicate your intent to LLMs efficiently.
Some specific habits that accelerate prompt engineering skill development:
Compare outputs across models. The same prompt often produces noticeably different code from ChatGPT, Claude, and Gemini. Comparing outputs teaches you what each model does well and what information each one needs.
Practice the “zero-shot to few-shot” progression. Start with a minimal prompt, observe where the output falls short, and iteratively add context until you understand what information makes the critical difference.
Document your best prompts. Maintain a prompt journal or template library. Your future self will thank you.
12.38.11.3 Layer 3: Critical AI Evaluation¶
The apex of the competency pyramid is the ability to critically evaluate AI-generated code and output. This means developing the habit of asking, for every piece of generated code:
Does this code do what I intended? (Semantic correctness)
Does it handle edge cases and missing data appropriately? (Robustness)
Is the logic sound given what I know about the domain? (Validity)
Are the results consistent with reasonable expectations? (Sanity checking)
Is there any data security risk in how this code handles sensitive information? (Privacy)
Critical evaluation is not about distrust — it is about professional responsibility. When you present an analysis to a business stakeholder, you own the results. The AI is a tool; you are the professional.
138.12 Organizational Implications: Vibe Coding in the Enterprise¶
Vibe coding is not just a personal productivity tool — it is beginning to reshape how organizations structure analytical work, staff analytics teams, and think about the required skills of knowledge workers at all levels.
13.18.12.1 Democratization of Analytics¶
One of the most significant organizational implications of vibe coding is the democratization of analytical capability. When a marketing manager can prompt an LLM to generate a Python script that segments customers by purchase behavior, the traditional bottleneck of waiting for a data science team request to be prioritized and fulfilled is dramatically reduced. This shift has enormous implications for organizational agility — the speed at which business questions can be answered with data.
However, democratization brings risks alongside opportunities. Analytical governance — ensuring that analyses are methodologically sound, that data is handled appropriately, and that results are interpreted correctly — becomes more challenging when analytical work is distributed across a wider population of practitioners with varying levels of statistical sophistication.
13.28.12.2 The Evolving Role of the Data Scientist¶
Vibe coding does not eliminate the need for data scientists and data engineers — it changes what those roles focus on. Routine analytical coding tasks (writing boilerplate ETL scripts, generating standard visualizations, running common statistical tests) can increasingly be handled by business analysts using vibe coding tools. This frees data scientists to focus on higher-value work: designing novel methodologies, ensuring model validity and fairness, building robust production systems, and advancing the organization’s analytical maturity.
13.38.12.3 AI Use Policies and Governance¶
Forward-thinking organizations are developing explicit AI use policies that address vibe coding in the workplace. Key governance considerations include:
Which AI tools are approved for use with company data
What categories of data may and may not be shared with external AI systems
How AI-generated code should be reviewed and validated before production use
Intellectual property and attribution guidelines for AI-assisted work
Training requirements for employees using AI coding tools
As a business analytics professional, you may be asked to contribute to developing or implementing these policies. Your technical understanding of how vibe coding tools work will be a significant asset in those conversations.
14Discussion Question: Case Study¶
14.1Case Study: GitHub Copilot at Accenture¶
In 2023 and 2024, Accenture — one of the world’s largest professional services firms with over 700,000 employees — undertook one of the most ambitious enterprise deployments of AI coding assistance in history. The firm announced plans to deploy GitHub Copilot to 50,000 developers and to train an additional 30,000 employees in AI-assisted development practices. Accenture positioned this initiative as central to its strategy of delivering client projects faster and at higher quality, while simultaneously retraining its workforce for the AI era.
The deployment was not without complications. Accenture reported that productivity gains varied substantially across different types of projects and developer experience levels. Junior developers tended to show the largest percentage productivity gains on routine coding tasks — but also exhibited the highest rates of uncritically accepting incorrect AI-generated code. Senior developers were more likely to critically evaluate and refine generated code, resulting in higher-quality outputs but smaller percentage-point productivity gains. The firm invested heavily in training programs specifically designed to build “AI critical evaluation” skills alongside the technical adoption of Copilot.
Accenture also grappled with governance questions. Consulting engagements involve access to highly sensitive client data — financial records, strategic plans, customer data. Determining which data could be shared with cloud-hosted AI tools and which required air-gapped, on-premises solutions required extensive policy development and client communication.
By mid-2024, Accenture reported that AI-assisted development had reduced time-to-delivery on certain standardized analytical projects by 30–40%, and that developer satisfaction scores had increased. However, the firm also noted emerging concerns about skill development in junior analysts who had been onboarded primarily in an AI-assisted environment and who showed measurably weaker foundational programming skills than cohorts from prior years.
Discussion Question:
Based on the Accenture case study, critically analyze the tradeoffs involved in enterprise-wide deployment of vibe coding tools. Your response should address the following dimensions:
Productivity vs. Quality: Accenture found that junior developers showed the largest productivity gains but also the highest rates of accepting incorrect code. How should organizations structure training programs and code review processes to capture the productivity benefits of vibe coding while maintaining output quality? What role should foundational programming education play in the onboarding of new analysts in an AI-first era?
Skill Development Paradox: The case highlights an emerging concern that heavy AI assistance during early career development may inhibit the formation of foundational skills. Drawing on the “pilot analogy” discussed in this chapter, construct an argument for how organizations should balance AI assistance with deliberate skill-building. Where do you draw the line between helpful augmentation and harmful dependency?
Governance and Data Privacy: Accenture’s situation illustrates the complexity of deploying vibe coding tools in environments with sensitive client data. Propose a tiered data governance framework for a mid-sized financial services analytics team that specifies which categories of work can use public cloud LLM tools, which require enterprise-tier solutions, and which must be performed without AI assistance. Justify each tier.
Strategic Implications: How does the Accenture experience inform your own anticipated use of vibe coding tools in your career? What personal development commitments would you make to ensure you remain a high-value analytics professional in an environment where AI can handle increasing portions of routine analytical coding?
14.2📝 Discussion Guidelines¶
Primary Response: Your initial post must address all parts of the prompt with depth and critical thinking. It must include at least one citation (scholarly or credible industry source) to support your argument.
Peer Responses: You must respond thoughtfully to at least two of your peers. Your responses must go beyond simple agreement (e.g., “I agree with your point”) and add substantial value to the conversation by offering an alternative perspective, sharing related research, or asking a challenging follow-up question.
15Chapter Quiz¶
Instructions: Select the best answer for each question. Each question is worth 10 points.
1. The term “vibe coding” was popularized by which of the following individuals?
A) Sam Altman
B) Andrej Karpathy
C) Satya Nadella
D) Yann LeCun
2. Which of the following BEST describes the primary shift in the human role when moving from traditional programming to vibe coding?
A) From manager to programmer
B) From writer to director
C) From analyst to developer
D) From operator to tester
3. A business analyst pastes customer credit card numbers into ChatGPT to ask for help cleaning the data format. Which of the following BEST characterizes this action?
A) Acceptable if the analyst deletes the conversation afterward
B) A violation of data privacy principles and potentially illegal under various regulations
C) Acceptable because ChatGPT does not store conversation data
D) Acceptable if the analyst uses the free tier of ChatGPT
4. In the context of LLMs, “hallucination” refers to which of the following?
A) The model generating images alongside code
B) The model refusing to answer sensitive questions
C) The model confidently generating incorrect, nonexistent, or fabricated information
D) The model running code internally before producing output
5. Which prompt engineering technique involves providing the LLM with specific input-output examples to guide its response?
A) Zero-shot prompting
B) Role prompting
C) Few-shot prompting
D) Chain-of-thought prompting
6. According to the chapter, which of the following is the MOST critical skill at the apex of the vibe coding competency pyramid?
A) Knowledge of Python syntax
B) Ability to type prompts quickly
C) Critical AI evaluation of generated code
D) Familiarity with multiple AI tool platforms
7. An analyst receives Python code from an LLM that runs without errors but consistently produces revenue totals that are approximately 15% higher than expected. This scenario BEST illustrates which vibe coding risk?
A) Data leakage
B) Silent logical errors
C) Hallucination of library functions
D) Intellectual property violation
8. Which of the following vibe coding tools is BEST described as a VS Code fork built entirely around AI assistance, allowing natural language editing of existing codebases?
A) GitHub Copilot
B) Replit
C) Cursor
D) Jupyter AI
9. The incremental decomposition technique in vibe coding is analogous to which established practice in traditional software engineering?
A) Agile sprint planning
B) Modular programming and unit testing
C) Waterfall project management
D) Continuous deployment pipelines
10. Based on the discussion of organizational implications, which of the following BEST describes how vibe coding is likely to change the role of data scientists in enterprise organizations?
A) Data scientists will be entirely replaced by business analysts using AI tools
B) Data scientists will focus exclusively on model deployment and DevOps
C) Data scientists will shift focus toward novel methodology design, model validity, and advancing analytical maturity
D) Data scientists will primarily become prompt engineers who manage LLM interfaces
16Hands-On Activity: Building Your First Vibe-Coded Analytics Pipeline¶
16.1Overview¶
Title: From Natural Language to Insight: A Complete Vibe-Coded Analytics Workflow
Objective: In this activity, you will use a conversational AI tool of your choice (ChatGPT, Claude, Google Gemini, GitHub Copilot, or any equivalent LLM-powered assistant) to build a complete data analytics pipeline entirely through natural language prompting. You will practice the core vibe coding techniques introduced in this chapter, critically evaluate the generated code, document your prompting process, and reflect on the experience.
Tools: Any LLM-powered tool (ChatGPT recommended for beginners due to its built-in code execution capability via Advanced Data Analysis; Cursor or GitHub Copilot recommended for students with a local Python environment)
Time Estimate: 90–120 minutes
Deliverable: A completed Jupyter notebook (or equivalent) containing the generated code, your annotations, and a written reflection
16.2Dataset¶
You will use the Online Retail II dataset, a publicly available dataset from the UCI Machine Learning Repository. This dataset contains all transactions occurring between 01/12/2009 and 09/12/2011 for a UK-based online retail company. It includes the following columns:
| Column | Description |
|---|---|
| InvoiceNo | Invoice number (prefix ‘C’ indicates cancellation) |
| StockCode | Product/item code |
| Description | Product name |
| Quantity | Quantity per transaction |
| InvoiceDate | Invoice date and time |
| UnitPrice | Unit price in sterling |
| CustomerID | Customer identifier |
| Country | Country of customer |
Download: Search for “Online Retail II UCI” or use any comparable publicly available retail transaction dataset with similar structure.
16.3Part A: Environment Setup and Data Loading (20 minutes)¶
Step 1: Open your chosen AI tool. Begin a new conversation and establish context by sending the following as your opening message (adapt as needed for your specific tool):
“I am a graduate student in business analytics working on a data analysis project. I will be working with a retail transactions CSV dataset with columns: InvoiceNo, StockCode, Description, Quantity, InvoiceDate, UnitPrice, CustomerID, and Country. I want to work in Python using pandas, matplotlib, and seaborn. Please help me build a complete analytics pipeline step by step. I will describe each step and you will write the code. Let’s start.”
Step 2: Ask the LLM to generate code for loading and initially exploring the dataset:
“Write Python code to: (1) import necessary libraries, (2) load the CSV file (assume it’s named ‘online_retail.csv’ and is in the current directory), (3) display the first 5 rows, (4) show the shape of the dataset, (5) display column data types, and (6) count missing values per column.”
Step 3: Run the generated code. If you encounter any errors, paste the complete error message back to the LLM and ask it to fix the code.
Activity Checkpoint: In your notebook, add a markdown cell that answers these questions:
How well did the first prompt perform? Did you need to iterate?
What did you learn about your dataset from the initial exploration?
16.4Part B: Data Cleaning (20 minutes)¶
Step 4: Based on what you observed in Part A, prompt the LLM to handle the data quality issues in the dataset. You may discover that the Online Retail II dataset contains:
Cancelled transactions (InvoiceNo starting with ‘C’)
Missing CustomerIDs
Negative quantities
Rows with missing descriptions
Craft a prompt that addresses these issues. A strong prompt might look like:
“Now I need to clean the data. Please write code to: (1) remove rows where InvoiceNo starts with ‘C’ (cancellations), (2) remove rows with missing CustomerID, (3) remove rows where Quantity is less than or equal to zero, (4) create a new column called ‘TotalPrice’ calculated as Quantity multiplied by UnitPrice, and (5) convert InvoiceDate to datetime format. Show the shape of the cleaned dataset at the end.”
Step 5: Ask the LLM to explain each cleaning step it took:
“Before I run this, can you explain why each cleaning step is analytically important and what could go wrong in the analysis if we skipped each step?”
Activity Checkpoint: In your notebook, document one cleaning decision where you disagreed with or modified the LLM’s approach, and explain your reasoning.
16.5Part C: Exploratory Data Analysis and Visualization (30 minutes)¶
Step 6: Revenue by Country Analysis. Prompt the LLM to generate a bar chart showing the top 10 countries by total revenue (excluding the United Kingdom, which dominates the dataset):
“Write code to calculate total revenue (sum of TotalPrice) by Country, exclude the United Kingdom, show the top 10 countries, and create a horizontal bar chart with the country names on the y-axis and total revenue on the x-axis. Use a blue color palette, add value labels to each bar, and include a proper title and axis labels.”
Step 7: Monthly Revenue Trend. Prompt for a time series visualization:
“Extract the month and year from InvoiceDate and create a new ‘YearMonth’ column formatted as ‘YYYY-MM’. Calculate total monthly revenue and plot it as a line chart with months on the x-axis. Rotate x-axis labels 45 degrees for readability. Mark the peak revenue month with an orange dot.”
Step 8: Customer Purchase Frequency Distribution. Prompt for a distribution analysis:
“Calculate the number of unique invoices per CustomerID (purchase frequency). Create a histogram showing the distribution of purchase frequency, but limit the x-axis to customers with 50 or fewer purchases (to exclude extreme outliers). Add a vertical line showing the mean and another showing the median, labeled appropriately.”
Activity Checkpoint: For each visualization, add a markdown cell in your notebook with a 2–3 sentence business interpretation of what the chart reveals.
16.6Part D: Customer Segmentation Using RFM Analysis (20 minutes)¶
RFM (Recency, Frequency, Monetary) analysis is a classic customer segmentation technique used in retail analytics. In this step, you will use vibe coding to implement it.
Step 9: Prompt the LLM to implement RFM scoring:
“Implement RFM analysis on this dataset. Use the maximum InvoiceDate in the dataset as the reference date. Define: Recency as the number of days since the customer’s last purchase, Frequency as the total number of unique invoices per customer, and Monetary as the total amount spent per customer. Calculate these three metrics for each CustomerID. Then assign RFM scores from 1 to 4 for each metric using quartiles (for Recency, lower days = higher score; for Frequency and Monetary, higher values = higher scores). Create a new column called ‘RFM_Segment’ by concatenating the three scores as strings (e.g., ‘444’ for the best customers).”
Step 10: Ask the LLM to extend the analysis:
“Now create a scatter plot with Recency on the x-axis and Monetary on the y-axis, with point size proportional to Frequency (scaled appropriately). Color the points by RFM_Segment. Add a title and axis labels. Also print a summary table showing the count of customers and average Monetary value for the top 5 most common RFM segments.”
16.7Part E: Critical Reflection (20 minutes)¶
Step 11: Ask the LLM to review its own code. Send this prompt:
“Please review all the code you have generated in this conversation. Identify any potential weaknesses, assumptions, or limitations in the analysis. What would a senior data scientist likely critique about this approach?”
Review the LLM’s self-critique carefully.
Step 12: In your notebook, write a structured reflection (minimum 400 words) addressing the following:
Prompting Effectiveness: Which of your prompts worked well on the first try, and which required iteration? What patterns do you notice about what makes a prompt effective for data analytics tasks?
Code Quality Assessment: Review the final code in your notebook. Are there places where the generated code is inefficient, unclear, or potentially fragile? What would you change if you were deploying this code in a production environment?
Analytical Integrity: Did the LLM make any analytical choices that you found questionable or that required correction? How did you identify those issues, and what does that tell you about the skills a vibe coder needs to bring to the table?
Learning Experience: What did you learn about Python, pandas, or analytics techniques from reading and working with the generated code? Did vibe coding accelerate your understanding or obscure it in any way?
Professional Application: Identify a real analytical problem you have encountered (in a job, internship, class project, or personal context) that vibe coding could have addressed. How would you approach that problem differently now?
16.8Submission Guidelines¶
Submit the following to the course learning management system:
Your completed Jupyter notebook (.ipynb format) containing all code cells, output, and your markdown commentary and reflections
A prompt log (can be a text file or additional notebook section) documenting each major prompt you used and noting which ones required iteration and why
A one-page executive summary written as if you were presenting the retail analysis findings to a non-technical business audience — no code, no technical jargon, just insights and recommendations
Grading Rubric:
| Component | Points |
|---|---|
| Completeness of all five parts | 25 |
| Quality of prompt construction and documentation | 20 |
| Accuracy and interpretability of visualizations | 20 |
| Depth and honesty of critical reflection | 25 |
| Professional quality of executive summary | 10 |
| Total | 100 |
17Chapter Summary¶
This chapter has introduced vibe coding as one of the most consequential methodological shifts in the history of business analytics. We began with a conceptual definition, establishing vibe coding as a mode of development in which natural language prompts direct LLMs to generate executable code, shifting the human role from writer to director. We explored the technology behind LLMs and why they are both remarkably capable and characteristically fallible for code generation tasks.
We traced the historical arc of natural language programming from 1960s research laboratories to the present moment, establishing the context in which vibe coding has emerged. We situated vibe coding within the specific context of business analytics, identifying concrete scenarios in which it creates immediate professional value. We covered five core techniques — context setting, incremental decomposition, error pasting, requesting explanations, and specifying output formats — and extended these into advanced prompt engineering strategies including role prompting, few-shot prompting, chain-of-thought prompting, and constraint specification.
We surveyed the contemporary vibe coding tool ecosystem, from conversational AI assistants to IDE integrations to agentic platforms. We walked through a complete end-to-end analytics workflow to make the methodology concrete. We confronted the real risks — data privacy, silent logical errors, skill atrophy, and intellectual property — with the seriousness they deserve. We looked forward to the agentic AI horizon and its implications for the analytics profession. And we articulated a three-layer competency model — foundational knowledge, prompt engineering skills, and critical AI evaluation — that provides a development roadmap for the AI-era analyst.
The overarching message of this chapter is one of both opportunity and responsibility. Vibe coding genuinely democratizes analytical capability, accelerates delivery, and extends what is possible for the individual practitioner. But it does not replace judgment, domain expertise, or professional accountability. The analysts who will thrive in the AI era are not those who use AI most freely, but those who use it most wisely — combining the speed of AI generation with the integrity of human expertise.
18Key Terms¶
Vibe Coding — A mode of software development in which natural language prompts direct an LLM to generate, modify, explain, or debug code, shifting human focus from syntactic writing to strategic direction and critical evaluation.
Large Language Model (LLM) — A deep learning system trained on massive text corpora, capable of generating contextually appropriate text including source code in response to natural language prompts.
Prompt Engineering — The practice of designing and optimizing natural language inputs to LLMs to elicit desired outputs effectively and efficiently.
Hallucination — The tendency of LLMs to generate confident but incorrect, nonexistent, or fabricated information, including references to nonexistent functions or incorrect algorithmic logic.
Few-Shot Prompting — A prompt engineering technique in which specific input-output examples are provided to guide the LLM’s response.
Chain-of-Thought Prompting — A technique that instructs the LLM to reason through a problem step by step before producing a final answer, improving accuracy on complex tasks.
RFM Analysis — A customer segmentation technique that scores customers on Recency (how recently they purchased), Frequency (how often they purchase), and Monetary value (how much they spend).
Agentic AI — AI systems capable of autonomous, multi-step task execution, going beyond single-turn question-and-answer to plan, execute, and iterate on complex workflows independently.
Context Window — The maximum amount of text (measured in tokens) that an LLM can process in a single interaction, limiting the length and complexity of sustained vibe coding sessions.
Silent Logical Error — A code defect that does not produce a runtime error but causes the program to produce incorrect results, representing a particularly dangerous failure mode in analytical code.
19Further Reading and Resources¶
Karpathy, A. (2025). “Vibe Coding.” Post on X (formerly Twitter). — The originating articulation of the vibe coding concept by one of AI’s leading researchers.
Brown, T., et al. (2020). “Language Models are Few-Shot Learners.” Advances in Neural Information Processing Systems, 33. — The foundational GPT-3 paper that established the large language model paradigm underlying modern vibe coding tools.
Wei, J., et al. (2022). “Chain-of-Thought Prompting Elicits Reasoning in Large Language Models.” arXiv preprint arXiv:2201.11903. — Seminal research on the chain-of-thought prompting technique.
White, J., et al. (2023). “A Prompt Pattern Catalog to Enhance Prompt Engineering with ChatGPT.” arXiv preprint arXiv:2302.11382. — A comprehensive catalog of prompt engineering patterns, many of which are directly applicable to analytical coding tasks.
Chen, M., et al. (2021). “Evaluating Large Language Models Trained on Code.” arXiv preprint arXiv:2107.03374. — The Codex paper from OpenAI that introduced the model underlying GitHub Copilot, with detailed evaluation of code generation performance.
OpenAI. (2024). ChatGPT Advanced Data Analysis Documentation. — Official documentation for the code execution capabilities of ChatGPT, directly relevant to vibe coding for analytics.
GitHub. (2024). GitHub Copilot Documentation. — Comprehensive documentation for the most widely deployed enterprise vibe coding tool.
Chapter 8 | ISM 6405 Advanced Business Analytics | Dr. Ernesto Lee | Florida Atlantic University