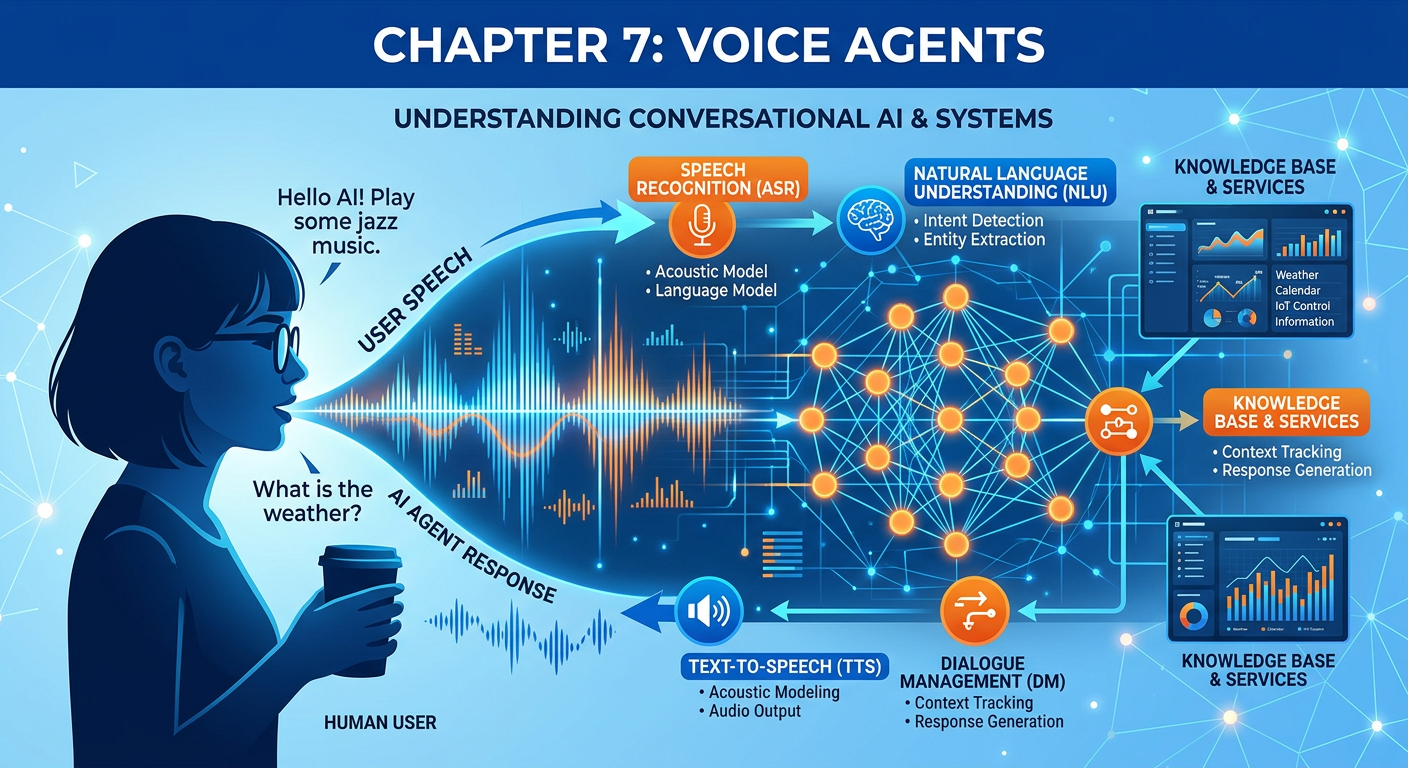
Figure 1:Explainer Infographic: Chapter 7: Voice Agents.
17.1 Introduction: The Conversational Turn in Business Analytics¶
There is a quiet revolution happening in how organizations interact with data. For decades, business analytics required analysts to write queries, build dashboards, navigate complex software interfaces, and translate findings into presentations for decision-makers. The fundamental assumption was that data required technical intermediaries — people who could bridge the gap between raw information and human understanding. That assumption is being challenged with remarkable speed.
Voice agents and conversational AI systems are redefining what it means to “access” data. A supply chain executive can now ask her smartphone, “What were our top three supplier delays last quarter, and how did they compare to industry benchmarks?” and receive a spoken answer synthesized from live enterprise data within seconds. A retail store manager can query inventory levels by speaking naturally into a headset while walking the floor. A financial analyst can dictate exploratory hypotheses to an AI agent that simultaneously queries databases, runs statistical models, and narrates results back in plain language.
This chapter explores the architecture, capabilities, business applications, and ethical dimensions of voice agents in the context of advanced business analytics. We will examine how conversational AI systems work under the hood, how organizations are deploying them to create competitive advantages, and how analytics professionals must adapt their skills to thrive in a world where the primary interface to data may no longer be a keyboard.
By the end of this chapter, you will understand the technical foundations of voice-based AI systems, be able to design conversational analytics workflows, evaluate platforms and tools, and critically assess the opportunities and risks that voice agents introduce into enterprise environments.
27.2 Conceptual Foundations: What Is a Voice Agent?¶
Before we can appreciate the power of voice agents in business analytics, we need to establish clear conceptual boundaries. The term “voice agent” is used loosely in popular discourse, often conflated with simpler technologies like voice assistants or interactive voice response (IVR) systems. In the context of advanced business analytics, these distinctions matter enormously.
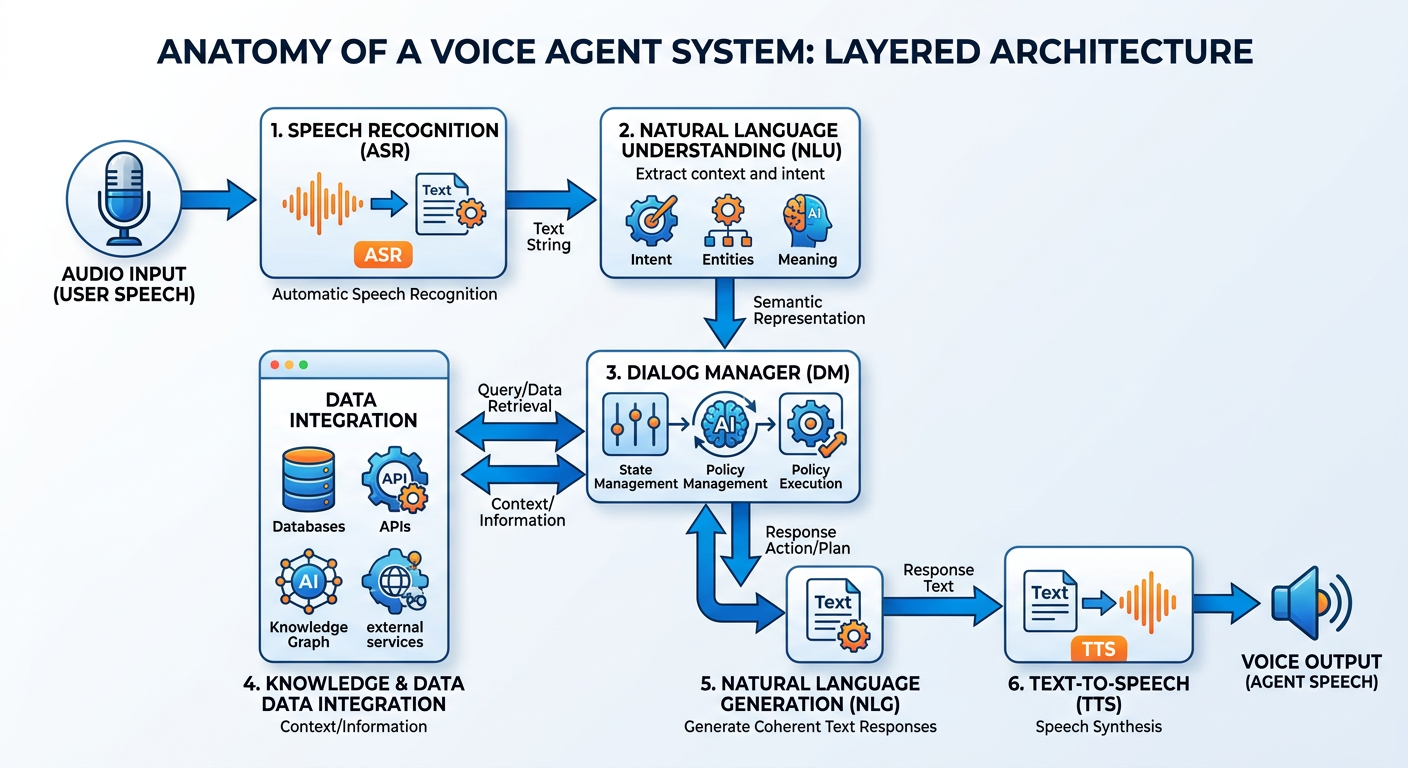
Figure 2:The Voice AI Taxonomy: From Simple IVR Systems to Autonomous Conversational Agents.
2.17.2.1 A Taxonomy of Voice-Based Systems¶
At the simplest end of the spectrum, we have Interactive Voice Response (IVR) systems — the automated phone menus that instruct you to “press 1 for billing, press 2 for technical support.” These systems follow rigid decision trees with no real language understanding. They match spoken or pressed inputs to pre-defined branches in a flowchart. While IVRs remain widely used in customer service, they represent the opposite of intelligent conversation.
Voice Assistants — systems like Amazon Alexa, Apple Siri, and Google Assistant in their early consumer forms — added a layer of natural language understanding. Users could speak in relatively natural sentences rather than pressing numbers. However, these systems were fundamentally intent-matching engines: they mapped spoken utterances to a catalog of predefined skills or actions. Ask Alexa to play music or check the weather, and it performs admirably. Ask it to analyze the correlation between marketing spend and customer acquisition cost across regional segments, and it fails immediately. The intelligence was pattern-matching, not reasoning.
Voice Agents represent a qualitative leap. Powered by large language models (LLMs) and sophisticated natural language processing (NLP) pipelines, voice agents can engage in multi-turn conversations, maintain context across exchanges, reason about ambiguous requests, call external tools and APIs, and generate genuinely novel responses rather than retrieving pre-written answers. In a business analytics context, a voice agent can understand that when a manager says “show me the same breakdown but for Q3,” the word “same” refers to an entire analytical framework discussed three conversational turns earlier.
Autonomous AI Agents push further still, operating with minimal human oversight across extended tasks. An autonomous analytics agent might spend hours querying data, building models, testing hypotheses, and generating reports — all initiated by a single high-level instruction from a human. We will touch on this frontier later in the chapter, though it represents the cutting edge of current research and deployment.
2.27.2.2 Why Voice Interfaces Matter for Business Analytics¶
The business case for voice interfaces in analytics is grounded in three fundamental human realities.
First, speech is the most natural human communication modality. Humans develop spoken language before written language, and we process spoken information with remarkable efficiency. The cognitive overhead of navigating graphical user interfaces, writing SQL queries, or constructing analytical pipelines creates a significant barrier between decision-makers and data insights. Voice removes much of this friction.
Second, the democratization of data access is an unfinished project. Despite decades of investment in business intelligence tools, dashboards, and self-service analytics platforms, most organizational data remains accessible only to trained analysts. Surveys consistently show that a majority of business decisions are still made based on intuition, anecdote, or incomplete information rather than rigorous data analysis. Voice agents that allow any employee to ask data questions in plain language represent a genuine path toward universal data literacy.
Third, many business contexts are physically incompatible with screen-based interfaces. A surgeon reviewing patient analytics during a procedure, a warehouse worker checking inventory while operating equipment, a field service technician diagnosing equipment performance remotely — these professionals need hands-free, eyes-free access to information. Voice is not just convenient in these contexts; it is the only viable interface.
37.3 The Architecture of Conversational AI Systems¶
Understanding how voice agents actually work is essential for analytics professionals who must design, deploy, and troubleshoot these systems. The architecture of a modern conversational AI system is a pipeline of specialized components, each performing a distinct function.
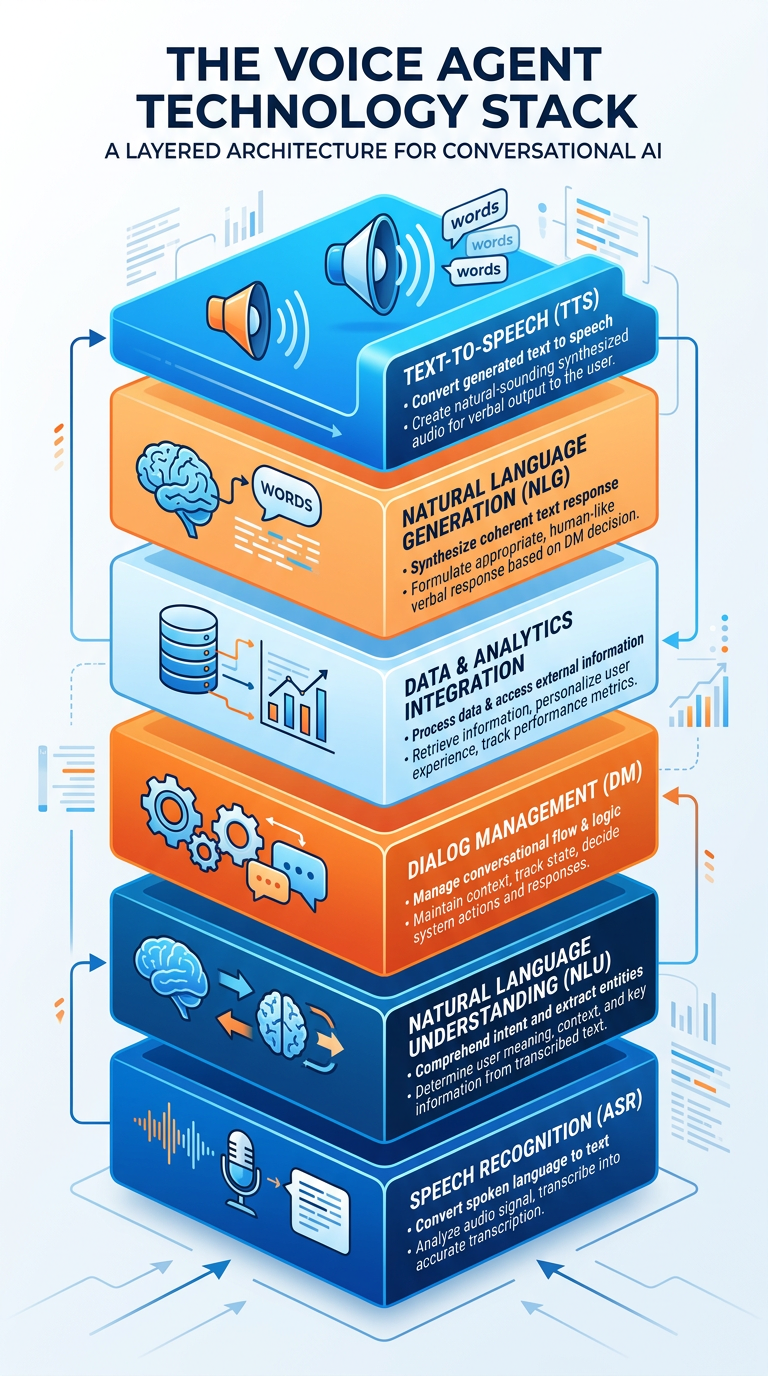
Figure 3:The Conversational AI Pipeline: From Spoken Words to Analytical Insights.
3.17.3.1 Automatic Speech Recognition (ASR)¶
The first challenge in any voice system is converting acoustic signals — sound waves captured by a microphone — into text that software can process. This is the domain of Automatic Speech Recognition (ASR), also called speech-to-text (STT) technology.
Modern ASR systems use deep neural networks, typically transformer-based architectures, trained on massive corpora of labeled audio data. Systems like OpenAI’s Whisper, Google’s Speech-to-Text API, and Amazon Transcribe can achieve word error rates (WER) below 5% in clean audio conditions for standard English, which is approaching human-level performance. However, performance degrades significantly in noisy environments, with strong accents, with technical vocabulary, or with very fast speech.
For business analytics applications, ASR faces particular challenges around domain-specific terminology. Phrases like “year-over-year EBITDA variance,” “cohort retention analysis,” or specific product names and codes may not appear frequently enough in general training data to be reliably transcribed. Leading enterprise ASR platforms now allow organizations to provide custom vocabulary lists and domain adaptation fine-tuning to address this gap.
3.27.3.2 Natural Language Understanding (NLU)¶
Once speech has been converted to text, the system must understand what the user actually means. Natural Language Understanding (NLU) encompasses several interrelated tasks:
Intent Recognition identifies the broad category of what the user wants to accomplish. In an analytics context, common intents might include query_data, visualize_trend, compare_segments, forecast_metric, or explain_anomaly.
Entity Extraction identifies specific pieces of information embedded in the utterance. In the sentence “What were our Northeast region sales last October compared to October of the prior year?”, the entities include: metric (sales), geographic dimension (Northeast region), time period (October, prior year).
Slot Filling ensures that all required parameters for a given intent have been captured. If a user says “show me the sales data,” the system recognizes this is a query_data intent but is missing critical entities: which product? which time period? which metric? The system must then ask clarifying questions to fill these slots.
Coreference Resolution handles the pronoun and reference tracking that makes multi-turn conversation coherent. When a user says “now filter that by region” after previously discussing revenue data, the system must resolve “that” back to the revenue query.
Modern NLU systems powered by large language models handle all of these tasks with impressive fluency, though they still make systematic errors that analytics professionals must learn to anticipate and mitigate.
3.37.3.3 Dialogue Management¶
Dialogue management is the component that controls the flow of conversation over multiple turns. It tracks the conversation state — what has been discussed, what analytical objects are currently in context, what clarifications have been requested — and determines what the system should do next at each point in the conversation.
There are two major paradigms for dialogue management. Finite-state approaches model conversation as movement through a predefined graph of states. They are reliable and predictable but brittle in the face of unexpected user inputs. Neural/LLM-based approaches use generative language models to manage conversation state implicitly, allowing much more flexible and natural dialogue — but potentially at the cost of consistency and predictability.
For business analytics applications, the choice of dialogue management approach has significant consequences. A procurement analytics use case where users follow predictable query patterns might benefit from the reliability of a structured approach, while an exploratory data discovery use case might require the flexibility of an LLM-based system.
3.47.3.4 Tool Calling and Backend Integration¶
This is where the real analytical power lives. Modern voice agents can be equipped with tools — external functions they can invoke to interact with the world. In an analytics context, these tools might include:
Database query tools: Functions that translate natural language requests into SQL or other query languages and execute them against data warehouses
Visualization tools: Functions that generate charts and graphs based on analytical results
Statistical analysis tools: Functions that run regression models, calculate statistical significance, detect anomalies, or perform forecasting
External data APIs: Connections to market data, economic indicators, or industry benchmarks
Document retrieval tools: Functions that search internal reports, research documents, or policy files
The mechanism by which LLMs select and use tools is called function calling (in OpenAI’s terminology) or tool use. The LLM reasons about which tool is appropriate for a given user request, generates the required parameters, calls the tool, receives the result, and incorporates that result into its response. This creates a powerful architecture in which the language model serves as an intelligent orchestrator of a broader analytical ecosystem.
import openai
import json
# Define a tool that queries sales data
tools = [
{
"type": "function",
"function": {
"name": "query_sales_data",
"description": "Query sales data from the data warehouse. Returns aggregated sales metrics.",
"parameters": {
"type": "object",
"properties": {
"metric": {
"type": "string",
"description": "The sales metric to retrieve, e.g., 'revenue', 'units_sold', 'gross_margin'"
},
"time_period": {
"type": "string",
"description": "The time period, e.g., 'Q1 2024', 'last 30 days', 'YTD'"
},
"dimension": {
"type": "string",
"description": "Optional grouping dimension, e.g., 'region', 'product_category', 'sales_rep'"
}
},
"required": ["metric", "time_period"]
}
}
}
]
# The voice agent uses this tool definition to understand
# when and how to call the sales data function
# The actual function would connect to your data warehouseExample: Simple Tool Definition for a Voice Analytics Agent (Python/OpenAI)
3.57.3.5 Natural Language Generation and Text-to-Speech¶
The final stage of the pipeline converts the agent’s response back into spoken language. Natural Language Generation (NLG) creates grammatically correct, contextually appropriate text responses, while Text-to-Speech (TTS) synthesis converts that text into audio.
Modern TTS systems have advanced dramatically from the robotic-sounding synthesizers of earlier decades. Systems like ElevenLabs, Amazon Polly Neural, Google WaveNet, and OpenAI’s TTS APIs produce remarkably natural-sounding speech with appropriate prosody, pacing, and emphasis. In analytics contexts, TTS systems must handle challenging elements like numbers, abbreviations, and technical terms, and quality varies significantly across platforms for these specific use cases.
47.4 Large Language Models as the Cognitive Core¶
The transformative leap in voice agent capability that has occurred since approximately 2022 is directly attributable to the integration of large language models (LLMs) as the cognitive core of conversational systems. Understanding what LLMs bring to voice analytics — and what their limitations are — is essential for every business analytics professional.
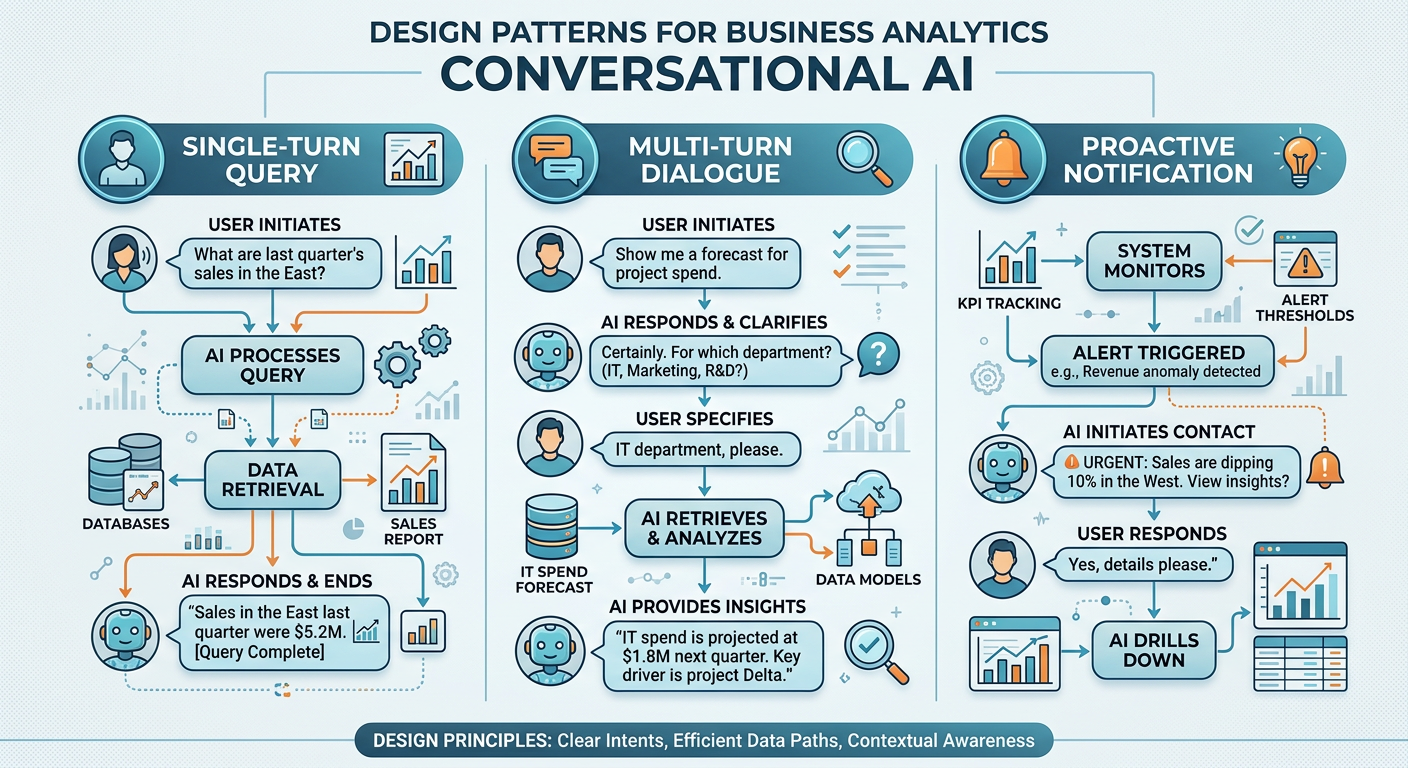
Figure 4:The LLM as Cognitive Core: Orchestrating the Voice Analytics Ecosystem.
LLMs like GPT-4o/o3 (OpenAI), Claude Sonnet 4.5 (Anthropic), Gemini 2.0 Flash (Google), and their successors are trained on vast corpora of text and develop extraordinarily broad linguistic and conceptual knowledge. When integrated into voice agents, they provide several capabilities that earlier systems lacked entirely:
Contextual reasoning across long conversations: LLMs can track complex analytical narratives across dozens of conversational turns, understanding references to earlier queries, remembering user preferences expressed in passing, and building on previous insights.
Instruction following for complex analytical tasks: A user can give multi-part, conditional instructions (“Show me product performance by region, but exclude any region that had fewer than 100 transactions, and highlight anything more than two standard deviations from the mean”) and the LLM can decompose this into appropriate tool calls and reasoning steps.
Explanation and interpretation: Beyond retrieving data, LLMs can explain what they find in accessible language, suggest why a pattern might exist, recommend further analyses, and flag potential data quality issues.
Handling ambiguity gracefully: Rather than crashing on ambiguous inputs, LLMs can make reasonable assumptions, state those assumptions explicitly, and invite correction — much as a skilled human analyst would.
However, LLMs also introduce important limitations and risks in analytical contexts. They can hallucinate — generate plausible-sounding but factually incorrect information. They may have knowledge cutoffs that make them unaware of recent events. They can exhibit systematic biases inherited from training data. And they may be confidently wrong in ways that are difficult to detect without domain expertise. These limitations demand careful system design with appropriate guardrails and verification mechanisms.
57.5 Voice Interfaces for Data: Design Principles and Patterns¶
Designing effective voice interfaces for data analytics is a discipline that blends principles from conversational UX design, data visualization theory, and human factors engineering. It is fundamentally different from designing screen-based interfaces, and many organizations make the mistake of simply trying to verbalize their existing dashboards rather than rethinking the interaction paradigm from first principles.
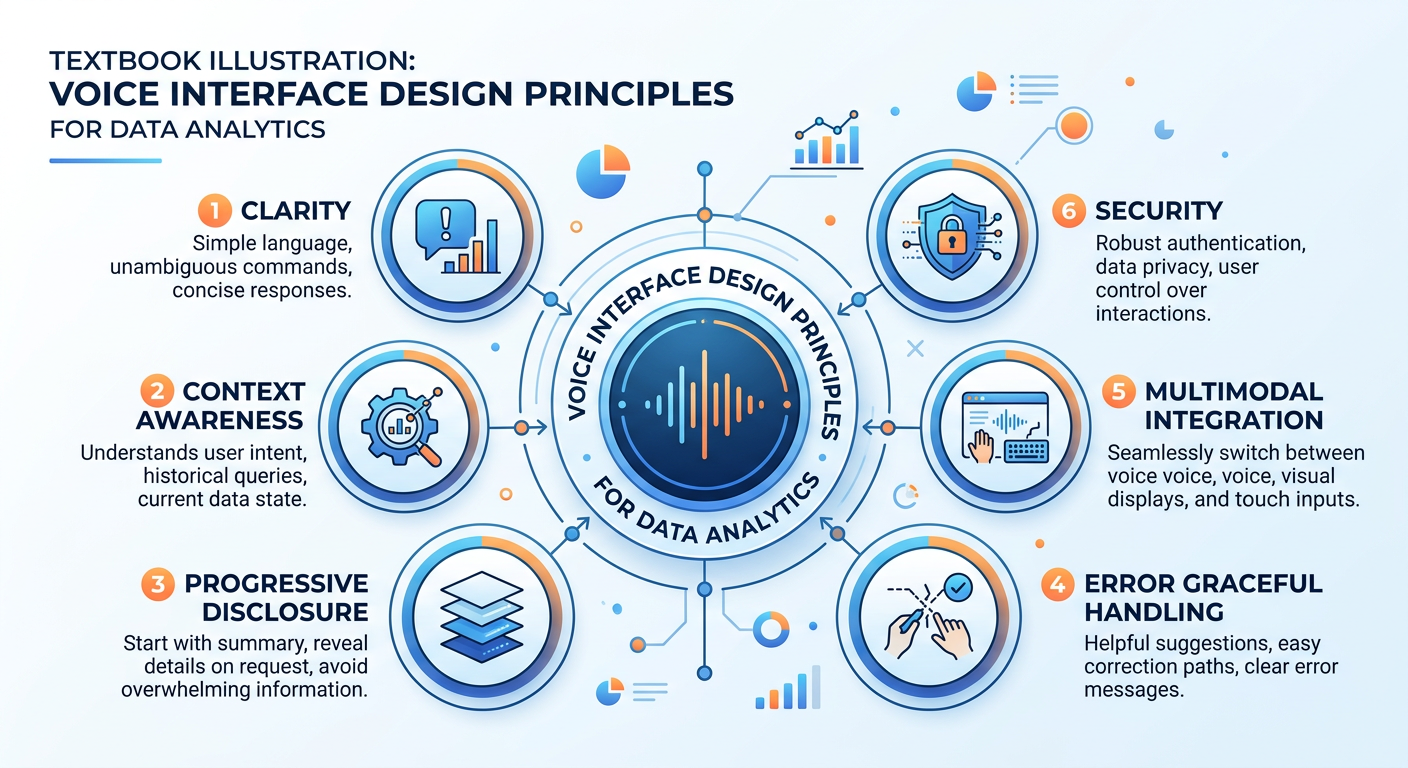
Figure 5:Voice-First vs. Screen-First Analytics Design: Rethinking the Information Architecture.
5.17.5.1 The Progressive Disclosure Pattern¶
Human working memory is limited, and spoken information is ephemeral — unlike text on a screen, you cannot scroll back to re-read what you missed. Effective voice analytics interfaces use progressive disclosure, presenting high-level insights first and offering to go deeper only when the user requests it.
Rather than reciting a 15-row data table, a well-designed voice agent might say: “Overall, Northeast revenue is up 12% year-over-year. The biggest driver is the commercial accounts segment, which is up 31%. Would you like details on any specific region or segment?” This approach respects cognitive bandwidth while still surfacing the full depth of information available.
5.27.5.2 Proactive vs. Reactive Agents¶
Not all value in voice analytics comes from reactive query-response interactions. Proactive agents monitor data continuously and initiate conversations when notable patterns or anomalies emerge. Imagine starting your workday with an agent that says: “Good morning. I noticed that your customer churn rate spiked 8% in the Southeast region overnight. This is statistically significant compared to the last 90 days of baseline. Would you like me to investigate possible causes?”
Designing proactive agents requires careful thinking about alert thresholds, notification timing, personalization, and — critically — preventing alert fatigue. The most sophisticated proactive systems use adaptive algorithms that learn each user’s tolerance for alerts and adjust their notification behavior accordingly.
5.37.5.3 Multimodal Integration¶
The most powerful voice analytics deployments do not treat voice as a standalone interface but as one component of a multimodal system. A voice agent might respond to a spoken query by simultaneously generating a visual chart on a nearby screen, sending a summary to a messaging platform, and filing a record in an audit log — all while narrating the key insights verbally. This multimodal orchestration maximizes the communicative power of each channel.
The design principle here is to use voice for what it does best (narrative explanation, rapid querying, hands-free interaction) while using visual channels for what they do best (complex comparisons, spatial data, detailed numerical tables). Voice and vision are complements, not substitutes.
When voice is the primary interface:
Hands-free operational environments (warehouses, field service, manufacturing floors)
Eyes-free contexts (driving, exercising, performing manual tasks)
Rapid ad-hoc queries where opening an app or logging into a dashboard is too slow
Accessibility accommodations for users with visual impairments or motor limitations
Executive briefings where natural conversation is more efficient than dashboard navigation
When voice and screen work together:
Data exploration sessions combining spoken queries with dynamically updating visualizations
Presentation contexts where voice narrates findings while slides or dashboards display supporting visuals
Complex comparative analyses requiring both spoken explanation and visual detail
Training and onboarding scenarios with voice coaching alongside screen-based exercises
When voice adds to a screen-primary workflow:
Dictating analytical hypotheses to be logged and pursued by an AI agent
Voice-commanded navigation within complex analytical software
Accessibility features added to existing BI platform interfaces
Rapid data lookups during screen-based work without context switching
67.6 Enterprise Platforms and Tools¶
The market for voice analytics platforms is evolving rapidly, and the landscape looks significantly different today than it did even two years ago. This section provides an overview of major platform categories and evaluation criteria, recognizing that specific product rankings will continue to shift.
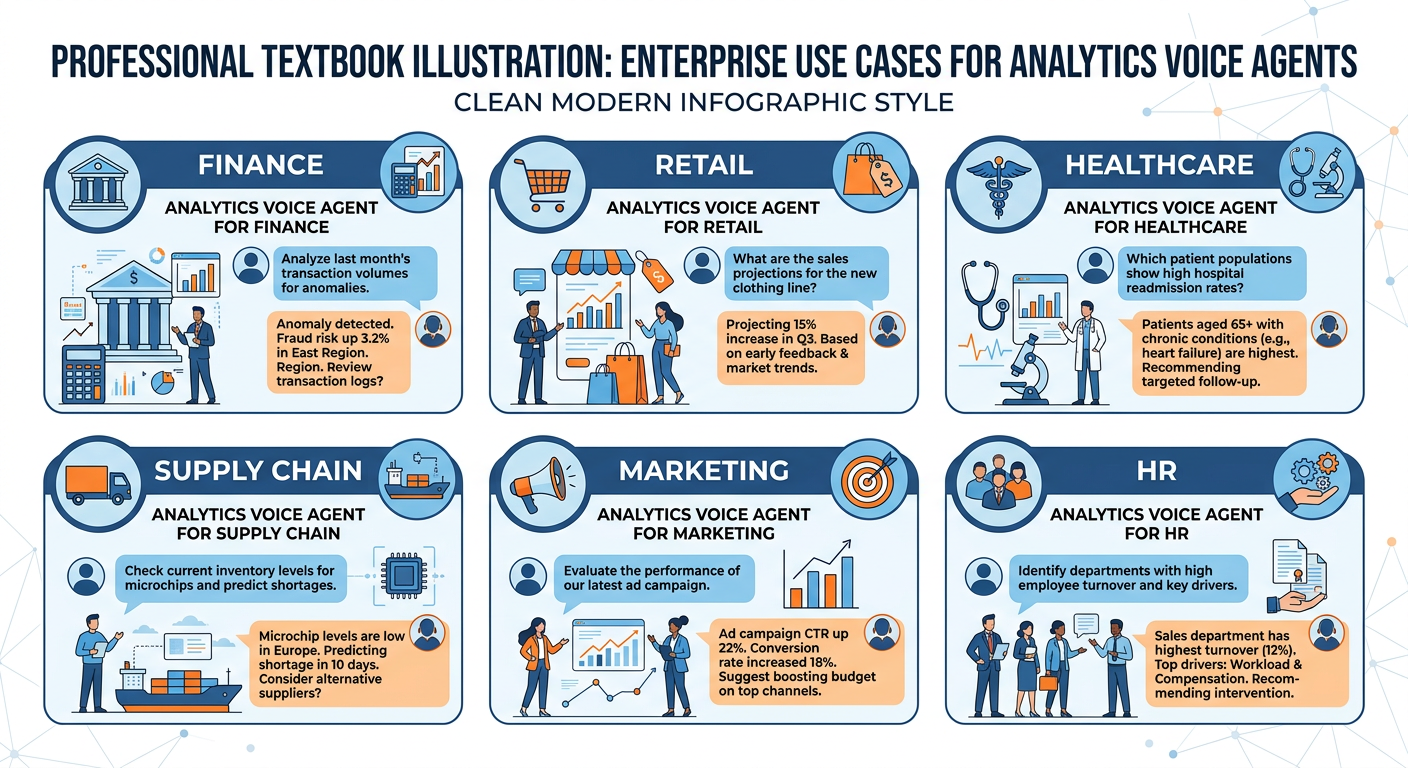
Figure 6:The Enterprise Voice Analytics Platform Landscape: A Market Taxonomy.
6.17.6.1 Cloud Hyperscaler Platforms¶
The three major cloud providers — Amazon Web Services, Google Cloud, and Microsoft Azure — each offer comprehensive conversational AI platform services that can be configured for analytics applications.
Amazon Lex (part of AWS) provides NLU capabilities with tight integration to other AWS services including Lambda for backend logic, Amazon Connect for voice telephony, and Redshift for data warehousing. Organizations deeply invested in the AWS ecosystem often find Lex a natural starting point, though its out-of-the-box analytical capabilities require significant custom development.
Google Dialogflow CX and the newer Vertex AI Agent Builder from Google Cloud offer sophisticated conversational flow design tools with strong NLU performance, particularly for enterprise contexts. Google’s ownership of both the cloud platform and underlying LLM technology (Gemini) creates tight integration possibilities.
Microsoft Azure AI offers Conversational Language Understanding, Azure Bot Service, and increasingly tight integration with Copilot and the OpenAI partnership. Organizations using Microsoft 365, Power BI, and the broader Microsoft ecosystem will find compelling integration pathways, including the Microsoft Fabric + Copilot combination for voice-enabled analytics.
6.27.6.2 Specialized Analytics Voice Platforms¶
**A ** growing ecosystem of companies specifically targets voice-enabled analytics. ThoughtSpot pioneered natural language querying for business intelligence and has continued evolving its NLP capabilities toward voice interaction. Tableau Pulse and similar features in major BI platforms represent incumbents’ responses to the conversational analytics trend. Newer entrants like Speak AI, Cognigy, and various LLM-powered analytics startups are building purpose-built voice analytics solutions.
6.37.6.3 Build-Your-Own with LLM APIs¶
For organizations with development resources and custom requirements, building voice agents using foundation model APIs has become increasingly accessible. The combination of OpenAI’s Whisper (ASR), GPT-4o or o3 (reasoning and NLU), and TTS APIs, combined with database connectors and orchestration frameworks like LangChain or LlamaIndex, allows sophisticated custom agents to be built in weeks rather than months.
This approach offers maximum flexibility and the ability to keep sensitive data within organizational boundaries, but requires ongoing engineering investment and carries more implementation risk than commercial platforms.
Evaluating Voice Analytics Platforms: A Decision Framework
When selecting a voice analytics platform, consider these dimensions:
1. Language Model Quality: How well does the underlying NLU model understand domain-specific language? Test with actual business queries from your environment, not just general examples.
2. Data Integration Depth: How easily does the platform connect to your existing data sources? Look for pre-built connectors to your specific databases, data warehouses, and BI tools.
3. Security and Data Governance: Where is audio processed? Where is data transmitted? Does the platform support role-based access control, data masking, and audit logging?
4. Customization and Training: Can you add custom vocabulary, intents, and domain knowledge? What does the model improvement process look like?
5. Multimodal Capabilities: Does the platform support generating visualizations or pushing responses to screens alongside voice output?
6. Latency: What is the end-to-end response time? For conversational analytics, latencies above 3-4 seconds feel unnatural and frustrating.
7. Total Cost of Ownership: Consider API call costs, developer time, training data creation, and ongoing maintenance — not just licensing fees.
77.7 Real-World Business Applications¶
Voice agents are creating measurable value across industries. This section examines concrete deployment patterns that are generating returns today, illustrating both the promise and the practical constraints of these technologies.
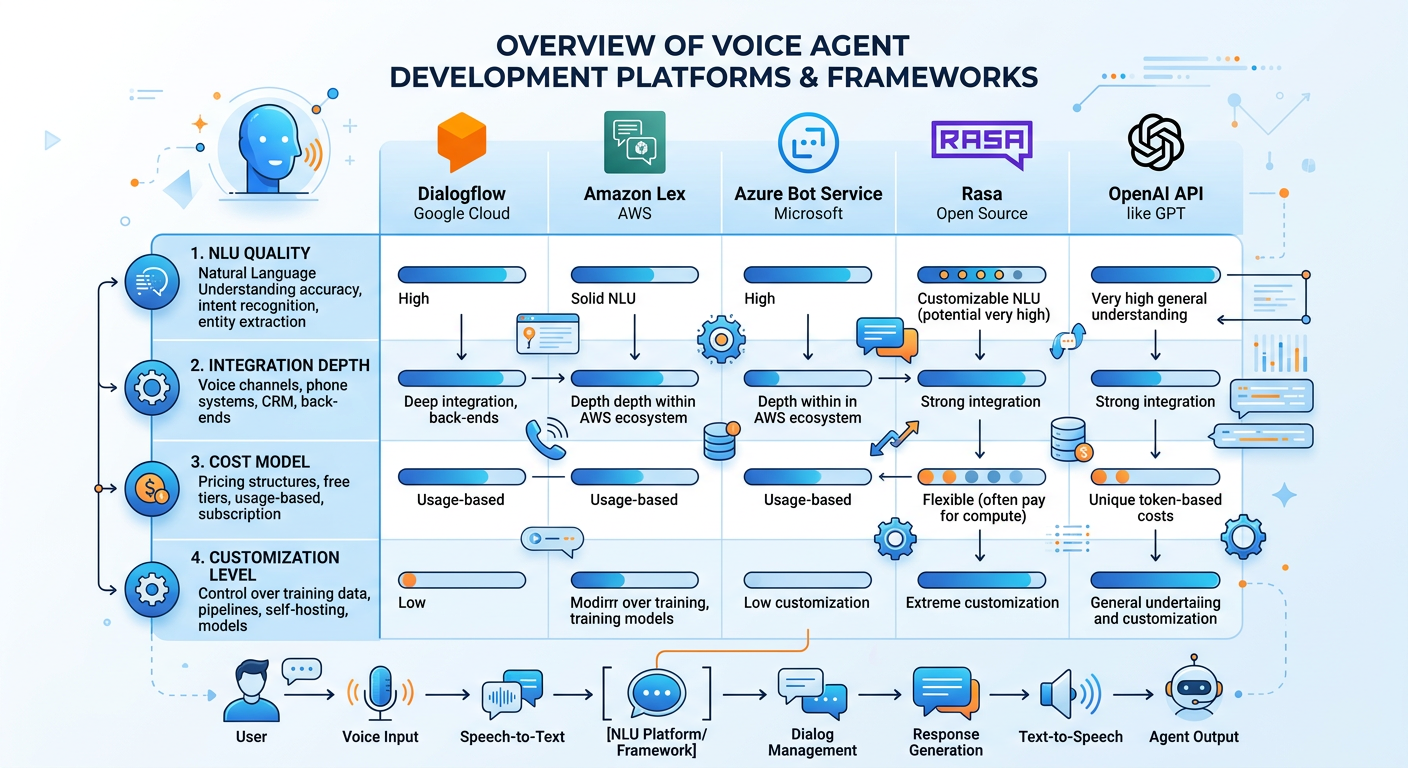
Figure 7:Voice Analytics in Action: Industry Use Cases Across Six Sectors.
7.17.7.1 Retail and Consumer Goods¶
Major retailers are deploying voice agents for both customer-facing and internal analytics applications. Internally, store managers use voice-enabled interfaces to check daily performance metrics, query inventory levels, and request staffing recommendations — all while actively moving through store operations. Associates can ask inventory systems whether a specific SKU is available, where it is located in the stockroom, and when the next shipment arrives, without leaving the sales floor to find a terminal.
Walmart, Target, and several European grocery chains have piloted voice-enabled workforce analytics tools that give frontline managers real-time access to sales pace, labor efficiency metrics, and shrinkage data through earpiece-based systems. Early results suggest meaningful improvements in manager responsiveness to performance trends.
7.27.7.2 Financial Services¶
Voice analytics is transforming how financial professionals interact with market data and portfolio analytics. Bloomberg has integrated conversational AI into its Terminal interface, allowing users to query financial data through natural language. Trading firms are experimenting with voice-activated risk monitoring systems that brief traders on position exposures and market anomalies during pre-market preparation.
In retail banking, conversational AI systems are providing both customer-facing financial guidance and internal analytics tools for branch managers and relationship managers. A regional bank manager might ask her analytics agent for a portfolio health summary, flag customers at churn risk, and receive recommendations for intervention — all before her first morning meeting.
7.37.7.3 Healthcare and Life Sciences¶
Healthcare presents perhaps the most compelling case for voice interfaces due to the critical importance of hands-free operation and the severe consequences of information access delays. Physicians using voice-enabled clinical analytics systems can query patient history, retrieve lab trends, and access diagnostic decision support without interrupting examination workflows.
Pharmaceutical companies are deploying voice analytics agents for clinical trial monitoring, allowing medical officers to query enrollment rates, adverse event frequencies, and protocol deviations through natural language. Genentech, among others, has invested in voice-enabled safety monitoring platforms that allow physicians and researchers to track safety signals across large patient populations conversationally.
7.47.7.4 Manufacturing and Supply Chain¶
In industrial environments where physical interaction with computer interfaces is impractical or unsafe, voice agents offer transformative capabilities. Quality control technicians on manufacturing lines can dictate defect observations that are immediately logged, classified, and integrated into statistical process control systems. Maintenance engineers can query equipment performance histories, receive diagnostic recommendations, and log repair outcomes through voice while working directly on machinery.
Supply chain professionals use voice analytics agents to monitor logistics performance, identify bottlenecks, and receive proactive alerts about delivery risks — particularly valuable in the complex, rapidly-changing environments that have characterized global supply chains since the disruptions of the early 2020s.
87.8 Organizational and Change Management Considerations¶
Technology rarely fails for purely technical reasons; it fails because organizations do not successfully change the human behaviors and processes that surround the technology. Voice analytics deployments are particularly susceptible to adoption challenges because they require users to fundamentally change how they interact with data.
Figure 8:The Voice Analytics Adoption Curve: Managing Organizational Change.
Many professionals have spent careers developing expertise in navigating specific BI tools, writing SQL queries, or building Excel models. Voice analytics agents can feel threatening to these identities and skill investments. Change management programs must address these psychological dimensions directly, not just the technical training elements.
The pilot-expand-scale model has emerged as a best practice. Organizations identify a high-value, relatively contained use case — perhaps a single analytics team or business unit — and deploy a voice agent in that context first. They measure adoption, satisfaction, and business outcomes rigorously. They use those findings to refine both the technology and the training approach before expanding to broader populations.
Executive sponsorship is consistently cited in deployment case studies as a critical success factor. When senior leaders visibly use voice analytics tools in meetings, when they cite agent-generated insights in decision-making, and when they publicly champion the technology, adoption accelerates throughout the organization. The opposite — senior leaders requiring subordinates to use voice tools while continuing to rely on traditional interfaces themselves — reliably undermines adoption.
97.9 Ethics, Privacy, and Security in Voice Analytics¶
The deployment of voice-based systems in enterprise environments introduces a distinctive set of ethical, privacy, and security challenges that analytics professionals must understand and address proactively. These are not merely compliance checklist items; they are fundamental questions about the appropriate boundaries of technology in human-centered organizations.
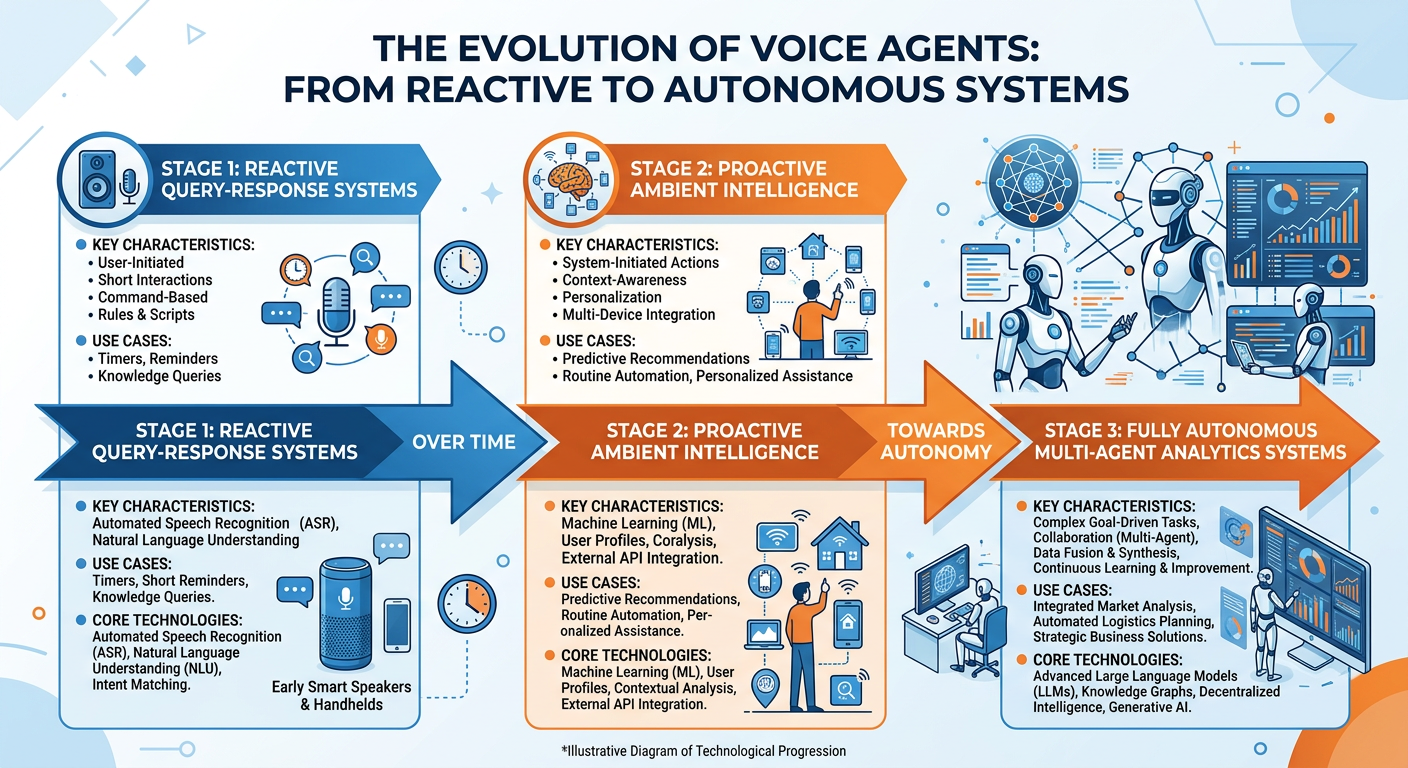
Figure 9:The Four Pillars of Ethical Voice Analytics Deployment.
9.17.9.1 Privacy and Surveillance Concerns¶
Voice-enabled systems require microphones to be active and processing audio in the workplace. This creates legitimate concerns about workplace surveillance that organizations must address transparently. Employees deserve clear answers to questions such as: Is our voice data retained after processing? Who can access voice query logs? Are conversations with analytics agents reviewable by management?
The legal landscape varies significantly across jurisdictions. In the European Union, GDPR requirements around audio data processing are strict. Several U.S. states have enacted specific biometric data privacy laws (Illinois’ BIPA being the most prominent) that may have implications for voice systems. Organizations must conduct privacy impact assessments and ensure their voice analytics deployments comply with applicable regulations in every jurisdiction where they operate.
Beyond legal compliance, organizations should consider whether the existence of voice query logs — which reveal what questions employees are asking about business data — might create chilling effects on legitimate analytical exploration. An analyst who knows that querying sensitive financial data triggers a log entry that managers can review may ask fewer of the exploratory questions that generate genuine insight.
9.27.9.2 Security Architecture¶
Voice systems introduce unique attack surfaces that traditional cybersecurity frameworks may not adequately address. Voice spoofing — using recorded or synthetic audio to impersonate authorized users — is a growing threat, particularly as deepfake audio technology improves. Organizations relying on voice biometrics for authentication must implement liveness detection and other anti-spoofing measures.
Prompt injection attacks represent a concern specific to LLM-based voice agents. A malicious actor might attempt to embed instructions in spoken input that manipulate the agent’s behavior — for example, instructing an analytics agent through a cleverly constructed query to reveal data it should not share, bypass access controls, or take unauthorized actions. Defense-in-depth strategies, including input sanitization, output monitoring, and strict tool permission scoping, are essential.
Access control is a critical design consideration. Voice analytics agents must implement the same role-based access controls that govern direct data access. An agent that allows any authorized user to ask any question about any data regardless of their actual data access permissions is a massive security vulnerability.
9.37.9.3 Bias and Fairness in Voice Systems¶
ASR systems have documented performance disparities across demographic groups. Multiple peer-reviewed studies, including influential research from Stanford and MIT, have demonstrated that major commercial ASR systems produce significantly higher word error rates for speakers with African American Vernacular English patterns, for non-native English speakers, for older speakers, and for speakers with certain disabilities. These disparities mean that voice analytics systems may literally be less functional for portions of the workforce, creating inequitable access to data-driven insights.
Organizations deploying voice analytics have an ethical obligation to measure ASR performance across the demographic diversity of their workforce and to address disparities through system selection, custom model training, or supplementary interface options. A voice agent that works excellently for a native English-speaking executive but poorly for a frontline worker with a non-standard accent reinforces existing organizational inequities rather than democratizing data access as intended.
9.47.9.4 Transparency and Explainability¶
Users interacting with voice analytics agents deserve to understand the basis for the information they receive. When a voice agent states that “customer satisfaction is down 7% this quarter,” users should be able to ask: What data source underlies that figure? What time period? What measurement methodology? How confident should I be in this number?
Well-designed voice agents proactively surface data provenance, confidence levels, and methodological caveats. They distinguish clearly between facts retrieved from authoritative data sources and inferences or interpretations generated by the language model. They acknowledge uncertainty rather than projecting false confidence. These design choices reflect a commitment to epistemic transparency that is central to ethical data practice.
107.10 The Future of Voice Agents in Business Analytics¶
The voice analytics landscape of 2025 is impressive, but the trajectory of development suggests capabilities that will be transformative in ways that are currently difficult to fully anticipate. Several emerging developments deserve particular attention from analytics professionals planning for the medium-term future.
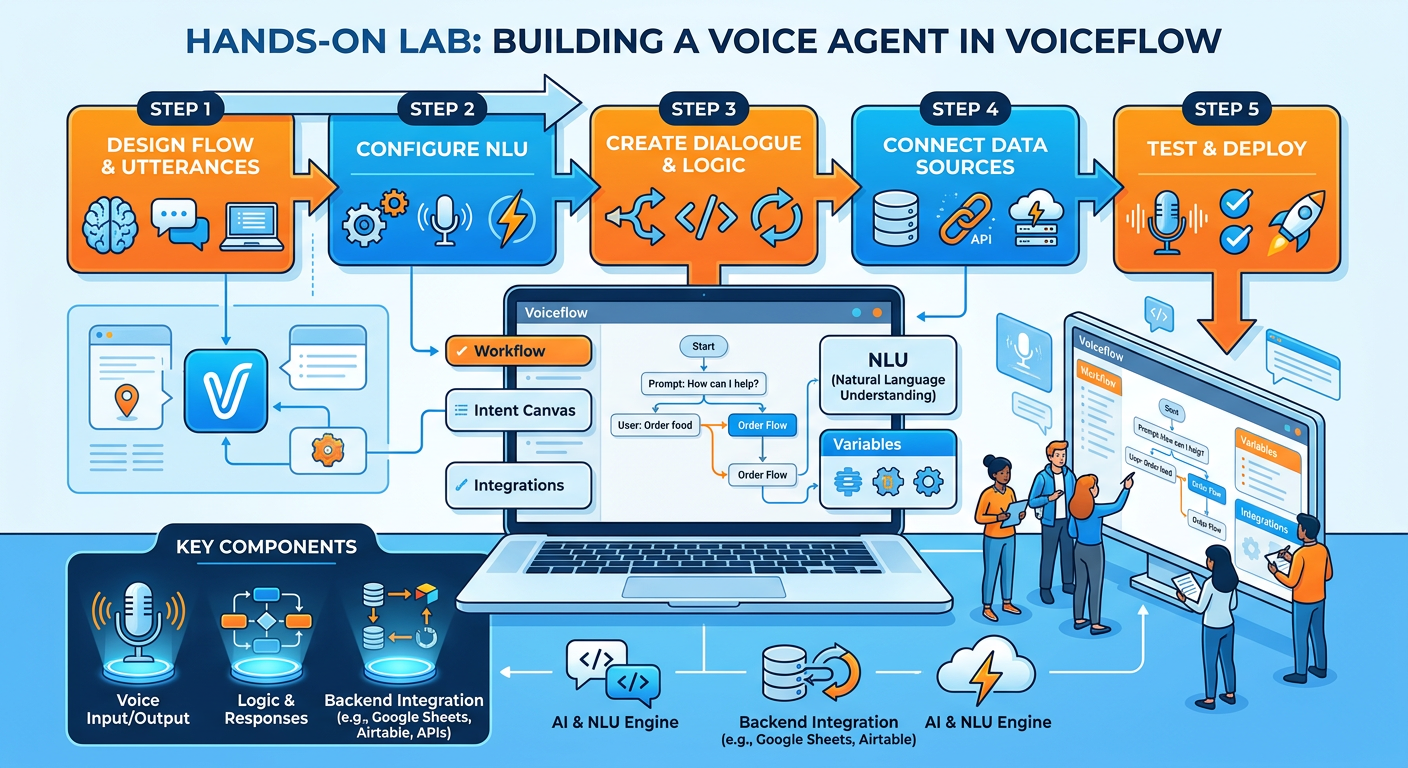
Figure 10:The Voice AI Evolution Timeline: From IVR to Autonomous Analytics Agents.
Real-time multimodal reasoning — the ability to simultaneously process voice, images, video, and text in a unified model — is rapidly maturing. Systems like GPT-4o, o3-mini, and Gemini 2.0 Flash demonstrate the ability to reason across modalities with low latency, with sub-300ms voice response times now achievable in production deployments. For analytics, this means voice agents that can look at a dashboard on your screen while you ask questions about it, or that can process a photograph of a physical environment (a store shelf, a manufacturing line, a logistics dock) while you ask analytical questions about what they observe.
Persistent memory and personalization will dramatically increase the value of voice analytics agents over time. Future agents will build detailed models of individual users — their analytical preferences, their domain expertise, their common query patterns, their cognitive style — and adapt their communication style, level of detail, and proactive alert patterns accordingly. The agent that has worked with a supply chain analyst for two years will provide fundamentally different, more valuable interactions than the same agent on its first day.
Agentic workflows — in which voice-initiated instructions launch extended autonomous analytical processes — will transform the relationship between analysts and their tools. An analyst might say: “I want to understand what’s driving the margin compression in our European business. Explore the data, generate hypotheses, test them statistically, and have a report ready for my 2pm review.” The agent then spends hours executing a sophisticated multi-step analytical workflow autonomously, returning results for human review and interpretation.
These developments underscore a point that is important for every student in this course to internalize: the analytics professional of the near future is not rendered obsolete by voice AI agents — she is amplified by them. The human skills of problem framing, critical interpretation, ethical judgment, stakeholder communication, and creative hypothesis generation become more valuable, not less, as routine data access and manipulation are automated. The competitive advantage will belong to professionals who master the art of working effectively with AI agents, not to those who resist the transition.
117.11 Discussion Question: Case Study Analysis¶
11.1The Alexa for Business Analytics Experiment at Nationwide Insurance¶
In 2019, Nationwide Insurance became one of the first major financial services companies to publicly discuss its deployment of voice-enabled analytics tools for enterprise use. The company integrated Amazon Alexa for Business into its analytics workflows, enabling employees to query select business metrics through voice commands. Initial pilot results showed promising adoption rates among some user groups, particularly senior executives who appreciated the hands-free, conversational access to summary metrics. However, the initiative faced significant headwinds: concerns about data security given the routing of queries through Amazon’s cloud infrastructure, inconsistent ASR performance across the diverse workforce, and resistance from analytics teams who felt their expertise was being bypassed.
By the early 2020s, as LLM-based conversational AI emerged, Nationwide — like many early voice analytics adopters — faced a decision about how to evolve its approach. The early infrastructure, built on intent-matching voice assistant technology, was architecturally different from the new generation of LLM-powered agents. Migrating to the newer paradigm would require significant reinvestment, but remaining on the old infrastructure meant falling further behind the capability curve.
Discussion Questions:
What organizational and technical factors should have been addressed in Nationwide’s initial deployment design to improve security and adoption outcomes? Be specific about both the data governance architecture and the change management approach.
Nationwide’s early system relied on intent-matching rather than LLM-based reasoning. Concretely describe three types of business analytics questions that their early system likely could not answer but that a modern LLM-powered voice analytics agent could handle effectively. What does this capability gap suggest about the strategic value of staying current with the technology generation curve?
The resistance from analytics teams who felt their expertise was being “bypassed” is a common organizational dynamic in analytics AI deployments. How would you design an organizational strategy that addresses this resistance while still capturing the efficiency benefits of voice analytics? Consider role evolution, incentive structures, and communication strategies in your response.
Drawing on the ethical framework discussed in Section 7.9, identify the three most significant ethical risks in Nationwide’s deployment and propose specific technical and policy controls that could mitigate each risk. How do these risks change when the system is upgraded to an LLM-powered architecture?
If you were advising Nationwide’s Chief Data Officer today on the decision to migrate from their legacy voice assistant infrastructure to a modern LLM-powered voice analytics agent, what evaluation framework would you use? What questions would you want answered before recommending a build-vs.-buy decision?
11.2📝 Discussion Guidelines¶
Primary Response: Your initial post must address all parts of the prompt with depth and critical thinking. It must include at least one citation (scholarly or credible industry source) to support your argument.
Peer Responses: You must respond thoughtfully to at least two of your peers. Your responses must go beyond simple agreement (e.g., “I agree with your point”) and add substantial value to the conversation by offering an alternative perspective, sharing related research, or asking a challenging follow-up question.
127.12 Quiz: Chapter 7 Assessment¶
Instructions: Answer all 10 questions. Questions 1–7 are multiple choice; questions 8–10 are short answer.
Question 1. Which of the following best describes the key functional difference between a traditional voice assistant (such as first-generation Alexa) and a modern LLM-powered voice analytics agent?
A) Voice assistants use text-to-speech synthesis while voice agents use neural speech synthesis
B) Voice assistants match utterances to predefined intent catalogs while voice agents can reason about novel requests, maintain extended context, and call analytical tools dynamically
C) Voice assistants operate in real-time while voice agents process queries in batch mode
D) Voice assistants are cloud-based while voice agents run entirely on-premises
Question 2. A logistics manager asks her voice analytics agent: “Show me the delayed shipments” and the agent responds asking for clarification on the time period and carrier. This is an example of which NLU capability?
A) Intent Classification
B) Coreference Resolution
C) Slot Filling
D) Entity Disambiguation
Question 3. The architectural pattern in which a voice agent dynamically retrieves information from external data sources at query time rather than relying solely on its training data is called:
A) Transfer Learning
B) Retrieval-Augmented Generation (RAG)
C) Fine-tuning
D) Reinforcement Learning from Human Feedback (RLHF)
Question 4. Which of the following represents the MOST significant security vulnerability specific to LLM-based voice analytics agents that would NOT typically be a concern for traditional IVR systems?
A) Unauthorized physical access to server hardware
B) Network packet interception during API calls
C) Prompt injection attacks through manipulated voice inputs
D) Brute-force password attacks on user accounts
Question 5. Research on ASR system performance has documented that word error rates are systematically higher for which of the following groups?
A) Native English speakers under age 35
B) Speakers using technical business vocabulary
C) Speakers with African American Vernacular English patterns and non-native English speakers
D) Users in quiet office environments
Question 6. In the context of voice analytics design, the principle of “progressive disclosure” refers to:
A) Revealing the AI system’s identity to users before they begin a conversation
B) Presenting high-level insights first and offering deeper detail only when requested, to respect cognitive bandwidth limitations of spoken communication
C) Gradually expanding the data access permissions of a voice agent as it demonstrates reliable behavior
D) Disclosing to regulatory bodies the existence of voice analytics systems
Question 7. An organization wants to deploy a voice analytics agent that can respond to queries with both spoken answers AND dynamically generated visualizations on a nearby screen. This interaction design approach is best described as:
A) Redundant interface design
B) Multimodal analytics orchestration
C) Dual-channel IVR deployment
D) Parallel processing architecture
Question 8. (Short Answer) Explain the concept of “tool calling” in LLM-powered voice agents. Why is this capability central to the usefulness of voice analytics agents, and what are two specific examples of tools that would be valuable in an enterprise analytics context?
Question 9. (Short Answer) A healthcare organization wants to deploy a voice analytics agent for its clinical operations team. Identify three specific ethical or privacy risks associated with this deployment and describe a mitigation strategy for each risk. Your answer should reference both technical controls and policy measures.
Question 10. (Short Answer) Describe the difference between reactive and proactive voice analytics agents. Give a concrete business example of each type, explaining what data the agent monitors, what triggers its action, and what business value it delivers. Under what circumstances might a proactive agent create organizational problems, and how would you design against those problems?
137.13 Hands-On Activity: Building Your First Voice Analytics Agent¶
13.1Activity Overview¶
Title: Building a Voice-Enabled Business Data Query Agent with Python and OpenAI
Estimated Time: 90–120 minutes
Skill Level: Intermediate (basic Python familiarity helpful but not required)
Tools Required: Python 3.9+, OpenAI API key (free tier or pay-per-use), a microphone, speakers or headphones, internet access. Alternatively, students without API access can use the Google Colab cloud environment.
Learning Objectives: By completing this activity, you will be able to construct a functional voice analytics pipeline, understand how LLMs interpret natural language queries and call tools, and experience firsthand both the power and the limitations of voice-based data interfaces.
13.2Background¶
In this activity, you will build a working prototype of a voice analytics agent that can answer questions about a sample business dataset using spoken language. The agent will listen to your voice, transcribe it, send the query to an LLM with access to a data querying tool, and speak the response back to you. While this is a prototype rather than a production system, it demonstrates all the fundamental architectural components discussed in this chapter.
13.3Part 1: Setting Up Your Environment¶
Step 1: Install required packages
Open your terminal or command prompt and install the necessary Python libraries:
pip install openai sounddevice soundfile numpy pandas scipy pyttsx3Terminal: Install Required Libraries
If you are using Google Colab, run:
!pip install openai sounddevice soundfile numpy pandas pyttsx3Google Colab: Install Libraries
Step 2: Set up your OpenAI API key
Create a file called .env in your project directory with the following content, replacing the placeholder with your actual API key:
OPENAI_API_KEY=your_api_key_here.env file
Alternatively, set it as an environment variable in your terminal:
export OPENAI_API_KEY=your_api_key_hereSet Environment Variable (Mac/Linux)
13.4Part 2: Preparing the Sample Business Dataset¶
We will use a simulated retail business dataset. Create a file called business_data.py with the following content:
import pandas as pd
# Sample retail sales data
def get_sales_data():
data = {
'region': ['Northeast', 'Southeast', 'Midwest', 'West', 'Southwest',
'Northeast', 'Southeast', 'Midwest', 'West', 'Southwest',
'Northeast', 'Southeast', 'Midwest', 'West', 'Southwest',
'Northeast', 'Southeast', 'Midwest', 'West', 'Southwest'],
'quarter': ['Q1', 'Q1', 'Q1', 'Q1', 'Q1',
'Q2', 'Q2', 'Q2', 'Q2', 'Q2',
'Q3', 'Q3', 'Q3', 'Q3', 'Q3',
'Q4', 'Q4', 'Q4', 'Q4', 'Q4'],
'revenue': [1250000, 980000, 1100000, 1450000, 870000,
1320000, 1020000, 1080000, 1510000, 910000,
1180000, 1150000, 1200000, 1620000, 890000,
1490000, 1280000, 1350000, 1780000, 1020000],
'units_sold': [4200, 3800, 4100, 5200, 3100,
4500, 4000, 3900, 5400, 3300,
3900, 4200, 4400, 5700, 3200,
5100, 4600, 4900, 6100, 3700],
'customer_satisfaction': [4.2, 3.9, 4.1, 4.5, 3.8,
4.3, 4.0, 3.8, 4.4, 3.9,
4.1, 4.3, 4.2, 4.6, 4.0,
4.4, 4.2, 4.3, 4.7, 4.1],
'returns_rate': [0.05, 0.07, 0.06, 0.04, 0.08,
0.04, 0.06, 0.07, 0.04, 0.07,
0.06, 0.05, 0.05, 0.03, 0.08,
0.04, 0.05, 0.04, 0.03, 0.06]
}
return pd.DataFrame(data)
# Function to query the dataset
def query_business_data(metric: str, dimension: str = None,
filter_by: str = None, filter_value: str = None):
"""
Query the business dataset and return results as a formatted string.
Args:
metric: The metric to analyze (revenue, units_sold,
customer_satisfaction, returns_rate)
dimension: Grouping dimension (region, quarter)
filter_by: Column to filter on (region, quarter)
filter_value: Value to filter for
"""
df = get_sales_data()
# Apply filter if specified
if filter_by and filter_value:
df = df[df[filter_by].str.lower() == filter_value.lower()]
if df.empty:
return f"No data found for {filter_by} = {filter_value}"
# Validate metric
valid_metrics = ['revenue', 'units_sold',
'customer_satisfaction', 'returns_rate']
if metric.lower() not in valid_metrics:
return f"Unknown metric '{metric}'. Available: {valid_metrics}"
metric = metric.lower()
# Group by dimension if specified
if dimension:
dimension = dimension.lower()
if dimension not in ['region', 'quarter']:
return f"Unknown dimension '{dimension}'. Use 'region' or 'quarter'."
grouped = df.groupby(dimension)[metric].agg(['mean', 'sum', 'min', 'max'])
result_lines = [f"{metric.upper()} by {dimension.upper()}:"]
for idx, row in grouped.iterrows():
if metric == 'revenue':
result_lines.append(
f" {idx}: Total ${row['sum']:,.0f} | "
f"Avg ${row['mean']:,.0f} | "
f"Range ${row['min']:,.0f} - ${row['max']:,.0f}"
)
elif metric == 'units_sold':
result_lines.append(
f" {idx}: Total {row['sum']:,.0f} units | "
f"Avg {row['mean']:,.0f}"
)
else:
result_lines.append(
f" {idx}: Avg {row['mean']:.3f} | "
f"Range {row['min']:.3f} - {row['max']:.3f}"
)
return "\n".join(result_lines)
else:
# Overall summary
total = df[metric].sum()
avg = df[metric].mean()
if metric == 'revenue':
return (f"Total {metric}: ${total:,.0f} | "
f"Average per period: ${avg:,.0f}")
elif metric == 'units_sold':
return (f"Total {metric}: {total:,.0f} units | "
f"Average: {avg:,.0f}")
else:
return f"Average {metric}: {avg:.3f}"business_data.py — Sample Business Dataset
13.5Part 3: Building the Voice Analytics Agent¶
Create the main agent file, voice_analytics_agent.py:
import os
import json
import tempfile
import sounddevice as sd
import soundfile as sf
import numpy as np
from openai import OpenAI
from business_data import query_business_data
import pyttsx3
# Initialize clients
client = OpenAI(api_key=os.environ.get("OPENAI_API_KEY"))
tts_engine = pyttsx3.init()
# Configure TTS voice properties
tts_engine.setProperty('rate', 175) # Speed of speech
tts_engine.setProperty('volume', 0.9) # Volume (0.0 to 1.0)
# ----- TOOL DEFINITIONS -----
tools = [
{
"type": "function",
"function": {
"name": "query_business_data",
"description": (
"Query the retail business analytics database. "
"Returns sales metrics including revenue, units sold, "
"customer satisfaction, and returns rate. "
"Can filter by region or quarter and group results by dimension."
),
"parameters": {
"type": "object",
"properties": {
"metric": {
"type": "string",
"description": (
"The business metric to analyze. "
"Options: 'revenue', 'units_sold', "
"'customer_satisfaction', 'returns_rate'"
)
},
"dimension": {
"type": "string",
"description": (
"Optional: Group results by this dimension. "
"Options: 'region', 'quarter'"
)
},
"filter_by": {
"type": "string",
"description": (
"Optional: Filter data by this column. "
"Options: 'region', 'quarter'"
)
},
"filter_value": {
"type": "string",
"description": (
"Optional: The value to filter for, "
"e.g., 'Northeast', 'Q1', 'West'"
)
}
},
"required": ["metric"]
}
}
}
]
# ----- SYSTEM PROMPT -----
SYSTEM_PROMPT = """You are a helpful voice analytics agent for a retail company.
You have access to sales data covering five regions (Northeast, Southeast, Midwest,
West, Southwest) across four quarters (Q1-Q4).
Available metrics:
- revenue: Total sales revenue in dollars
- units_sold: Number of units sold
- customer_satisfaction: Average satisfaction score (1-5 scale)
- returns_rate: Proportion of items returned (0-1 scale)
When answering questions:
1. Always use the query_business_data tool to retrieve actual data
2. Present numbers clearly and conversationally (speak dollar amounts as
"1.2 million" not "1200000")
3. Highlight the most interesting insights, not just raw numbers
4. Keep responses concise — this is a voice interface, so aim for 2-4 sentences
5. If you don't have data to answer a question, say so clearly
6. Proactively suggest related insights when relevant"""
# ----- AUDIO RECORDING -----
def record_audio(duration=5, sample_rate=16000):
"""Record audio from microphone for specified duration."""
print(f"\n🎤 Recording for {duration} seconds... Speak now!")
audio_data = sd.rec(
int(duration * sample_rate),
samplerate=sample_rate,
channels=1,
dtype=np.float32
)
sd.wait()
print("✅ Recording complete.")
return audio_data, sample_rate
def save_audio_temp(audio_data, sample_rate):
"""Save audio data to a temporary WAV file."""
temp_file = tempfile.NamedTemporaryFile(suffix='.wav', delete=False)
sf.write(temp_file.name, audio_data, sample_rate)
return temp_file.name
# ----- SPEECH RECOGNITION -----
def transcribe_audio(audio_file_path):
"""Transcribe audio using OpenAI Whisper."""
with open(audio_file_path, 'rb') as audio_file:
transcript = client.audio.transcriptions.create(
model="whisper-1",
file=audio_file,
language="en"
)
return transcript.text
# ----- TEXT TO SPEECH -----
def speak(text):
"""Convert text to speech using pyttsx3 (local, no API cost)."""
print(f"\n🔊 Agent: {text}")
tts_engine.say(text)
tts_engine.runAndWait()
# ----- TOOL EXECUTION -----
def execute_tool(tool_name, tool_args):
"""Execute the requested tool and return results."""
if tool_name == "query_business_data":
result = query_business_data(**tool_args)
return result
return f"Unknown tool: {tool_name}"
# ----- AGENT REASONING LOOP -----
def process_query(user_query, conversation_history):
"""
Process a user query through the LLM with tool calling.
Returns the agent's final text response.
"""
# Add user message to history
conversation_history.append({
"role": "user",
"content": user_query
})
# First LLM call — may request tool use
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "system", "content": SYSTEM_PROMPT}]
+ conversation_history,
tools=tools,
tool_choice="auto"
)
assistant_message = response.choices[0].message
# Check if tool calls were requested
if assistant_message.tool_calls:
# Add assistant's tool-calling message to history
conversation_history.append(assistant_message)
# Execute each requested tool
for tool_call in assistant_message.tool_calls:
tool_name = tool_call.function.name
tool_args = json.loads(tool_call.function.arguments)
print(f"\n🔧 Calling tool: {tool_name} with args: {tool_args}")
tool_result = execute_tool(tool_name, tool_args)
print(f"📊 Tool result: {tool_result}")
# Add tool result to history
conversation_history.append({
"role": "tool",
"tool_call_id": tool_call.id,
"content": tool_result
})
# Second LLM call — generate final response with tool results
final_response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "system", "content": SYSTEM_PROMPT}]
+ conversation_history
)
final_text = final_response.choices[0].message.content
conversation_history.append({
"role": "assistant",
"content": final_text
})
return final_text, conversation_history
else:
# No tool call — direct response
direct_text = assistant_message.content
conversation_history.append({
"role": "assistant",
"content": direct_text
})
return direct_text, conversation_history
# ----- MAIN CONVERSATION LOOP -----
def run_voice_agent():
"""Main loop for the voice analytics agent."""
conversation_history = []
print("\n" + "="*60)
print(" VOICE ANALYTICS AGENT — RETAIL BUSINESS DATA")
print("="*60)
print("Commands: Type 'voice' for voice input, 'quit' to exit")
print("Or type your question directly for text input")
print("="*60)
# Welcome message
welcome = ("Welcome to your retail analytics assistant! "
"I can answer questions about revenue, units sold, "
"customer satisfaction, and returns rates "
"across our five regions and four quarters. "
"What would you like to know?")
speak(welcome)
while True:
print("\n> ", end="")
user_input = input().strip()
if user_input.lower() == 'quit':
speak("Goodbye! Your analytics session has ended.")
break
elif user_input.lower() == 'voice':
# Voice input mode
audio_data, sample_rate = record_audio(duration=6)
audio_path = save_audio_temp(audio_data, sample_rate)
print("🔄 Transcribing your question...")
user_query = transcribe_audio(audio_path)
os.unlink(audio_path) # Clean up temp file
if not user_query.strip():
speak("I didn't catch that. Please try again.")
continue
print(f"📝 You said: {user_query}")
elif user_input:
# Text input mode
user_query = user_input
else:
continue
# Process the query
print("🤔 Processing your query...")
response_text, conversation_history = process_query(
user_query, conversation_history
)
# Speak the response
speak(response_text)
if __name__ == "__main__":
run_voice_agent()voice_analytics_agent.py — The Core Voice Analytics Agent
13.6Part 4: Running Your Voice Agent¶
Step 1: Open your terminal in the project directory and run:
python voice_analytics_agent.pyRun the Voice Analytics Agent
Step 2: When the agent speaks its welcome message, try the following queries (you can type them or use voice mode by typing voice):
“What was our total revenue?”
“Show me revenue broken down by region.”
“Which region had the highest customer satisfaction?”
“How did the West region perform in Q4?”
“What region has the worst returns rate?”
“Compare units sold across all quarters.”
13.7Part 5: Reflection and Extension Exercises¶
After running your agent through several queries, complete the following reflection tasks in your lab notebook or course discussion board:
Reflection Exercise 1: Limitation Mapping
Intentionally try to “break” your agent with queries it cannot handle. Document at least three specific types of queries that fail or produce poor responses, and for each one, explain what component of the pipeline (ASR, NLU, tool design, LLM reasoning, TTS) is responsible for the failure.
Reflection Exercise 2: Conversation Context Test
Have a multi-turn conversation with your agent where later queries depend on context from earlier ones. For example: ask about revenue by region, then ask “which of those had the highest growth?” Observe how well the agent maintains context. What happens when you ask for something that requires comparing across more than two conversational turns?
Reflection Exercise 3: Ethical Audit
Looking at the agent you just built, conduct a brief ethical audit using the framework from Section 7.9. Specifically address: What data privacy risks exist in this architecture? What happens if the API key is exposed? What groups of users might experience worse performance, and why?
Extension Challenge (Optional — For Additional Credit)
Extend your agent by adding a second tool: a calculate_growth_rate function that accepts two periods and a metric and returns the percentage change. Update the tool definition in the tools list, implement the function in business_data.py, and add it to the execute_tool dispatcher. Test it with queries like “What was the revenue growth from Q1 to Q4 in the Northeast region?”
13.8Activity Debrief¶
This hands-on activity has walked you through every layer of the conversational AI pipeline described in Section 7.3 — from audio capture through speech recognition, through LLM reasoning and tool calling, to speech synthesis. You have experienced firsthand how these components chain together, and you have identified real failure modes that mirror challenges faced in enterprise deployments.
Notice that even in this simple prototype, you encountered the fundamental design tensions of voice analytics: the trade-off between response speed and response quality, the challenge of scoping tool capabilities appropriately, and the importance of conversation state management. These tensions scale directly to enterprise deployments, where the same architectural decisions must be made under more complex business constraints and with higher stakes for errors.
147.14 Chapter Summary¶
Voice agents represent one of the most consequential shifts in how organizations interact with data since the invention of the graphical user interface. This chapter has traced the arc from simple IVR systems through modern LLM-powered voice analytics agents, examining the technical architecture that makes these systems work, the design principles that make them useful, the ethical considerations that must govern their deployment, and the organizational changes required for successful adoption.
The key technical insight is that modern voice agents are not merely voice-activated search engines — they are reasoning systems capable of multi-turn contextual dialogue, dynamic tool use, and genuine analytical problem-solving. The emergence of large language models as the cognitive core of these systems is the enabling leap that distinguishes the current generation from its predecessors.
The key design insight is that voice is a fundamentally different communication modality from text or graphics, and effective voice analytics interfaces must be designed from the ground up to respect the cognitive characteristics of spoken communication — progressive disclosure, concision, narrative structure, and proactive intelligence.
The key ethical insight is that voice systems introduce distinctive risks around privacy, security, bias, and transparency that demand proactive design choices and ongoing organizational vigilance. The democratization of data access promised by voice analytics can only be realized equitably if these systems work for all members of an organization’s workforce, not just the most advantaged.
For analytics professionals, the rise of voice agents is not a threat to be managed but an opportunity to be seized. The professionals who will thrive in this emerging landscape are those who combine deep analytical expertise with fluency in conversational AI design, ethical judgment in AI deployment, and the ability to serve as effective bridges between the expanding capabilities of AI systems and the complex, human-centered needs of business organizations.
15Key Terms¶
Automatic Speech Recognition (ASR): Technology that converts spoken audio into text transcriptions, typically using deep neural network models trained on labeled audio data.
Conversational AI: Artificial intelligence systems designed to engage in natural language dialogue with humans, encompassing both text-based and voice-based interfaces.
Dialogue Management: The component of a conversational AI system that tracks conversation state, determines appropriate system actions at each conversational turn, and manages multi-turn interaction flow.
Function Calling / Tool Use: The capability of large language models to identify when an external function should be invoked,generate appropriate parameters, and incorporate the function’s return value into the model’s response.
Intent Recognition: A natural language understanding task that classifies the high-level purpose or goal expressed in a user’s utterance into one of a set of predefined categories.
Interactive Voice Response (IVR): An automated telephony system that interacts with callers through pre-recorded messages and fixed decision trees, without genuine natural language understanding.
Large Language Model (LLM): A deep learning model trained on massive text corpora that develops broad linguistic and conceptual knowledge, capable of generating coherent, contextually appropriate text and reasoning across complex tasks.
Multimodal Analytics: An interaction paradigm that combines multiple communication channels — voice, visual display, text — in a coordinated system, using each channel for the types of information it communicates most effectively.
Natural Language Generation (NLG): The computational process of producing grammatically correct, contextually appropriate natural language text from structured data or internal representations.
Natural Language Understanding (NLU): The branch of natural language processing focused on extracting meaning from human language input, encompassing intent recognition, entity extraction, slot filling, and coreference resolution.
Proactive Agent: A voice analytics agent that monitors data continuously and initiates conversations when notable patterns, anomalies, or threshold violations are detected, rather than waiting for user queries.
Progressive Disclosure: A voice interface design principle in which high-level insights are presented first and detailed information is offered only upon user request, respecting the cognitive and temporal constraints of spoken communication.
Prompt Injection: A security attack in which malicious instructions are embedded in user inputs with the intent of manipulating an LLM-powered system’s behavior outside its intended scope.
Retrieval-Augmented Generation (RAG): An architectural pattern in which a language model dynamically retrieves relevant information from external sources at query time and incorporates that retrieved context into its generated response, reducing hallucination and enabling access to current information.
Slot Filling: An NLU process in which a conversational system identifies missing required parameters for a recognized intent and asks clarifying questions to complete the information needed to fulfill the user’s request.
Text-to-Speech (TTS): Technology that converts written text into synthesized spoken audio, used as the output stage of voice agent pipelines.
Voice Agent: An AI-powered conversational system that accepts natural language speech input, processes it through NLU and reasoning components, executes analytical actions through tool use, and returns synthesized speech output, capable of multi-turn dialogue and complex task completion.
Word Error Rate (WER): A standard metric for evaluating ASR system accuracy, calculated as the proportion of words in a transcript that are incorrect relative to the reference transcription.
16Further Reading and Resources¶
Academic and Technical References
Jurafsky, D., & Martin, J. H. (2024). Speech and Language Processing (3rd ed. draft). Stanford University. Available at: web
.stanford .edu / ~jurafsky /slp3/ — The definitive academic textbook on NLP and dialogue systems, freely available online and regularly updated to reflect current developments. Brown, T., et al. (2020). Language models are few-shot learners. Advances in Neural Information Processing Systems, 33, 1877–1901. — The foundational GPT-3 paper that initiated the current era of large language model capabilities.
Hoy, M. B. (2018). Alexa, Siri, Cortana, and more: An introduction to voice assistants. Medical Reference Services Quarterly, 37(1), 81–88. — An accessible overview of voice assistant technology and applications in professional contexts.
Koenecke, A., Nam, A., Lake, E., Nudell, J., Quartey, M., Mengesha, Z., ... & Goel, S. (2020). Racial disparities in automated speech recognition. Proceedings of the National Academy of Sciences, 117(14), 7684–7689. — The landmark study documenting systematic ASR performance disparities across demographic groups.
Industry Reports and Practitioner Resources
Gartner (2024). Magic Quadrant for Conversational AI Platforms. Gartner Research. — Annual industry analysis of enterprise conversational AI vendors, useful for platform evaluation.
McKinsey Global Institute (2023). The Economic Potential of Generative AI: The Next Productivity Frontier. McKinsey & Company. — Comprehensive analysis of generative AI’s business impact, with relevant sections on conversational interfaces.
MIT Sloan Management Review (2024). AI and the Future of Work. MIT Sloan School of Management. — Ongoing series examining how AI tools including voice agents are reshaping professional roles and organizational structures.
Online Tools and Platform Documentation
OpenAI API Documentation (platform
.openai .com /docs) — Comprehensive documentation for Whisper, GPT-4o, and TTS APIs used in this chapter’s hands-on activity. LangChain Documentation (python
.langchain .com) — Framework for building LLM-powered applications including voice agents, with extensive tutorials on tool calling and agent architectures. Google Dialogflow CX Documentation (cloud
.google .com /dialogflow /cx /docs) — Enterprise conversational AI platform documentation with business analytics integration patterns.
Chapter 7 Author Note: The field of voice analytics is evolving with extraordinary speed. The specific platforms, model names, and capability benchmarks cited in this chapter reflect the state of the field as of mid-2025. Students and practitioners are encouraged to treat the conceptual frameworks, design principles, and ethical considerations as durable guides while remaining attentive to how specific technical implementations continue to evolve. The fundamentals of how humans communicate, how organizations make decisions, and what makes AI deployment ethical and effective change far more slowly than the technology itself — and mastery of those fundamentals is the most durable investment any analytics professional can make.
End of Chapter 7
Next Chapter Preview: Chapter 8 explores Autonomous AI Agents and Multi-Agent Systems, examining how networks of specialized AI agents can collaborate on complex analytical workflows, manage long-horizon tasks, and transform the architecture of enterprise analytics operations.