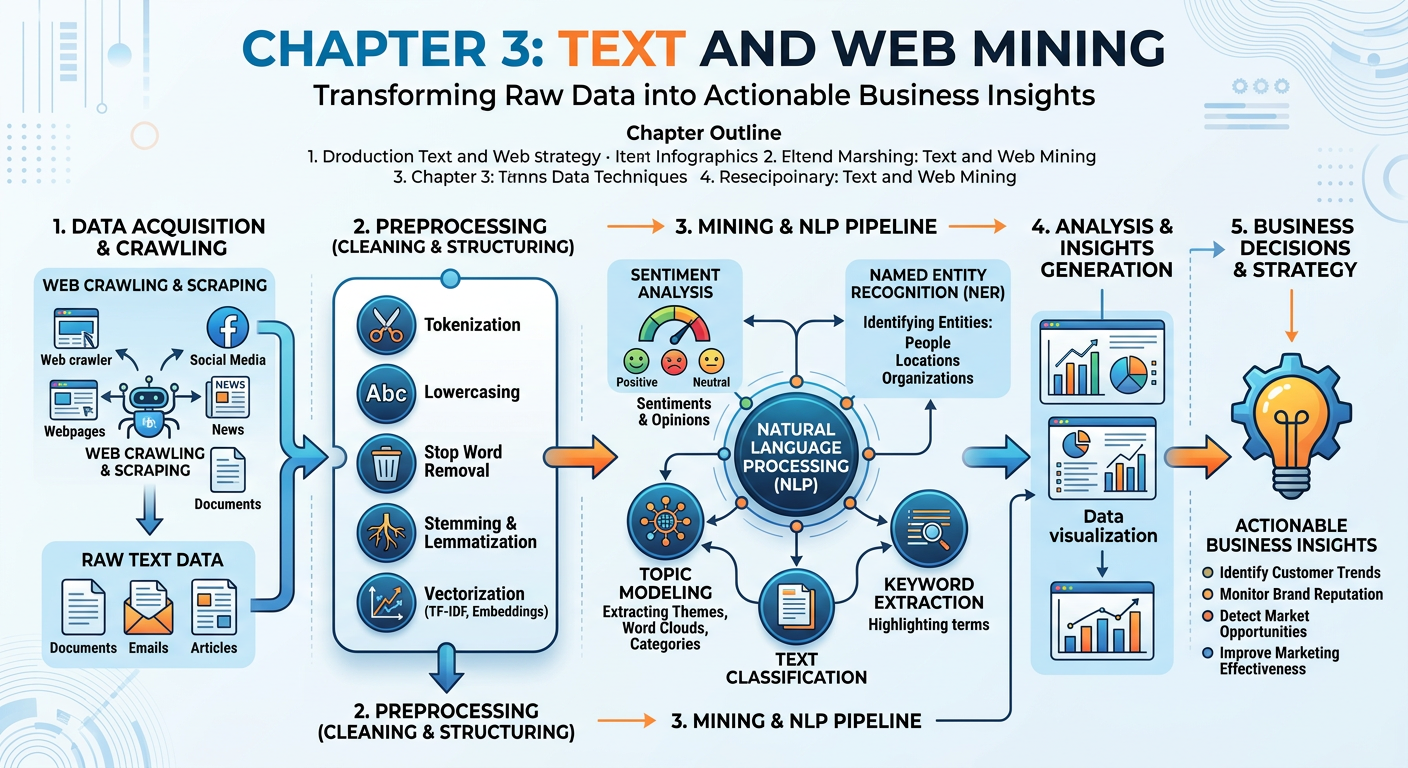
Figure 1:Explainer Infographic: Chapter 3: Text and Web Mining.
1Introduction: The Unstructured Data Revolution¶
Every minute of every day, the digital world generates an astonishing volume of language. Tweets critiquing a new product launch. Customer reviews comparing hotel experiences. News articles shifting investor sentiment. Legal contracts encoded in PDFs. Earnings call transcripts laced with carefully chosen words. Forum threads where patients describe medication side effects in their own, unfiltered voices. By conservative estimates, more than 80 percent of the data created in organizations today is unstructured — and the dominant form of unstructured data is text.
For decades, this richness was largely inaccessible to traditional analytics. Structured databases thrived on numbers and categories; the subtlety of language — sarcasm, context, domain jargon, cultural nuance — resisted the rigid schemas of spreadsheets and SQL tables. But three converging forces have changed this story dramatically: the explosion of web-native text, the maturation of Natural Language Processing (NLP) as a discipline, and the emergence of large language models (LLMs) that bring near-human reading comprehension to machines. Together, these forces place text and web mining at the very center of modern business analytics.
This chapter equips you with a practical and conceptual foundation for working with text data in business contexts. We will explore the NLP pipeline — the series of computational steps that transform raw language into structured insight. We will examine web scraping as a data acquisition strategy, complete with its technical mechanics and its legal and ethical landscape. We will dive deeply into sentiment analysis, the flagship application of business text mining, and survey other high-value use cases including topic modeling, named entity recognition, and document classification. Throughout, we will keep our eyes on real business problems: How does a retail chain monitor brand health across ten thousand social media posts per day? How does a hedge fund extract signals from earnings call transcripts? How does a healthcare organization detect patient safety concerns from clinical notes? And in the hands-on activity, you will use Google AI Studio to run your own NLP experiments with a state-of-the-art generative AI model.
Welcome to the chapter where language becomes data, and data becomes competitive advantage.
23.1 Foundations of Natural Language Processing¶
2.13.1.1 What Is NLP and Why Does It Matter in Business?¶
NLP is not a single algorithm or technique — it is an entire discipline spanning linguistics, statistics, and deep learning. At the shallow end of the technical spectrum, you have rule-based systems and frequency counts. At the deep end, you have transformer architectures with billions of parameters — models like BERT, GPT-4o, Claude Sonnet 4.5, and Google’s Gemini 2.0 — that have been trained on essentially the entire readable internet and can perform extraordinary language tasks. Most real-world business applications sit somewhere in the middle: combining classical preprocessing pipelines with modern pre-trained models to achieve accuracy, speed, and interpretability at acceptable cost.
The business case for NLP is compelling. Consider a telecommunications company managing a call center that handles fifty thousand customer interactions per day. Human agents transcribe notes, but reading every note to detect systemic service failures is impossible. An NLP pipeline can process those notes overnight, surface recurring complaint themes, flag high-frustration interactions, and route insights to product and operations teams by morning. That is not a futuristic scenario — it is current practice at firms like Verizon, T-Mobile, and Comcast.
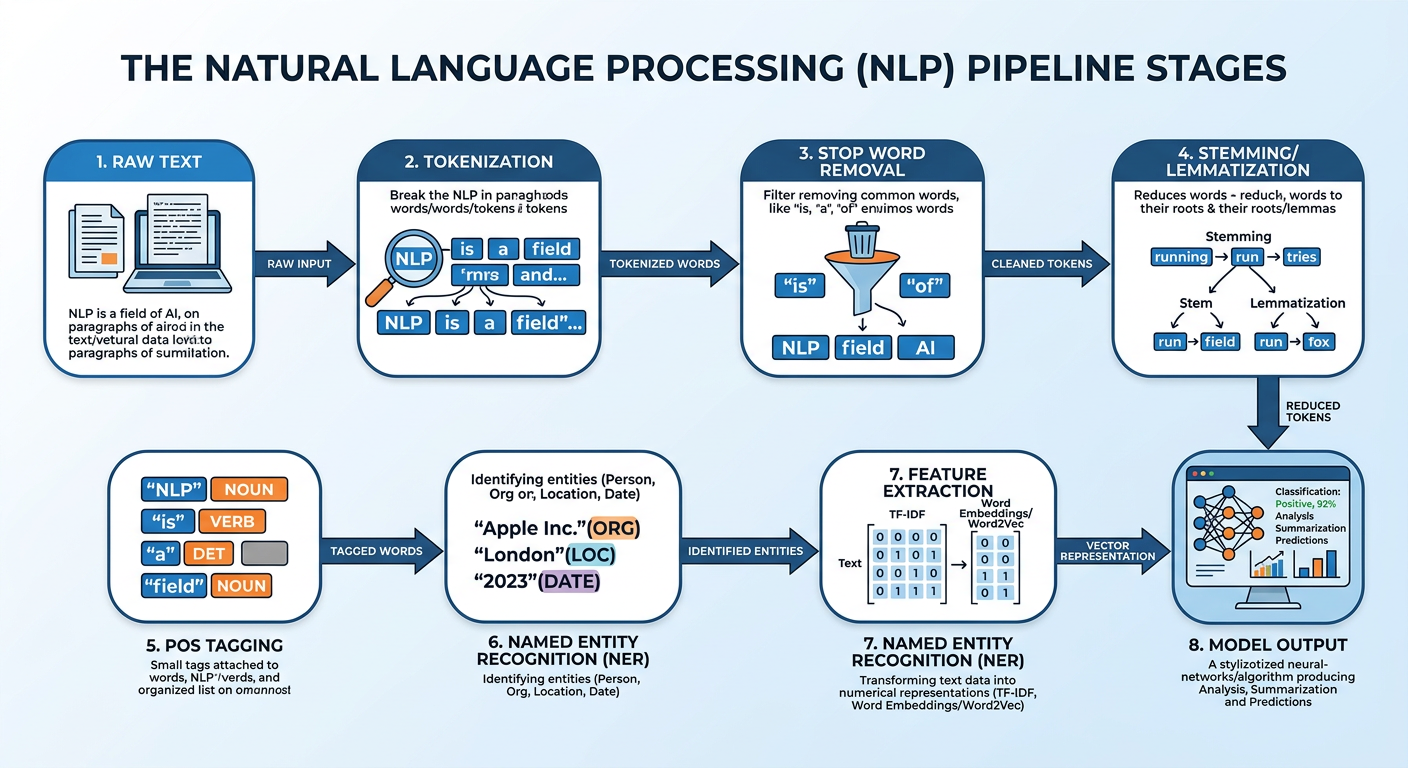
Figure 2:The Classic NLP Processing Pipeline: from raw text to machine-readable features.
2.23.1.2 The NLP Processing Pipeline¶
Before any machine learning model can learn from text, the text must be transformed into a numerical representation. This transformation happens through a series of preprocessing steps collectively called the NLP pipeline. While modern large language models have internalized much of this pipeline in their tokenizers, understanding each step is essential for building transparent, auditable, and business-appropriate text analytics systems.
Tokenization is the process of splitting a stream of text into individual units called tokens. Tokens are most commonly words, but they can also be subwords, characters, or sentences depending on the application. For example, the sentence “Customer service was terrible!” becomes the token list ["Customer", "service", "was", "terrible", "!"]. Subword tokenization — used by modern transformer models — would further split “terrible” into ["terr", "ible"] to handle rare words more robustly.
# Example using NLTK
import nltk
nltk.download('punkt')
from nltk.tokenize import word_tokenize
text = "Customer service was absolutely terrible!"
tokens = word_tokenize(text)
print(tokens)
# Output: ['Customer', 'service', 'was', 'absolutely', 'terrible', '!']Stop words are high-frequency words that carry little semantic content on their own — “the,” “is,” “at,” “which,” “on.” Removing them reduces dimensionality and focuses the analysis on content-bearing terms. However, context matters: in sentiment analysis, words like “not,” “never,” and “barely” are stop words in generic lists but are critically important for meaning. Always review your stop word list for domain fit.
from nltk.corpus import stopwords
stop_words = set(stopwords.words('english'))
filtered = [w for w in tokens if w.lower() not in stop_words]
print(filtered)
# Output: ['Customer', 'service', 'absolutely', 'terrible', '!']Stemming reduces words to their base form by stripping suffixes using heuristic rules: “running,” “runs,” “runner” → “run.” It is fast but imprecise. Lemmatization uses vocabulary and morphological analysis to return the dictionary base form: “better” → “good.” Lemmatization is slower but produces linguistically valid roots, making it preferable for tasks where word meaning must be preserved accurately.
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
words = ["running", "better", "studies", "organizational"]
lemmas = [lemmatizer.lemmatize(w) for w in words]
print(lemmas)
# Output: ['running', 'better', 'study', 'organizational']Part-of-Speech (POS) tagging assigns grammatical labels to each token: noun, verb, adjective, adverb, preposition, etc. This is valuable for extracting subject-verb-object relationships, identifying product-related adjectives in reviews, or building grammar-aware features. For example, knowing that “smooth” is an adjective modifying “checkout” is more informative than knowing “smooth” appears somewhere near “checkout.”
import nltk
text = "The checkout process was incredibly smooth."
tokens = nltk.word_tokenize(text)
pos_tags = nltk.pos_tag(tokens)
print(pos_tags)
# Output: [('The', 'DT'), ('checkout', 'NN'), ('process', 'NN'),
# ('was', 'VBD'), ('incredibly', 'RB'), ('smooth', 'JJ')]Once text is preprocessed, it must be converted to numbers. Classical approaches include:
Bag of Words (BoW): Each document becomes a vector counting word frequencies.
TF-IDF: Term Frequency–Inverse Document Frequency weights words by how distinctive they are to a document relative to the corpus.
Word Embeddings: Dense vector representations (Word2Vec, GloVe, FastText) that encode semantic relationships geometrically.
Contextual Embeddings: Transformer-based representations (BERT, Gemini) that encode word meaning in context.
Modern enterprise NLP predominantly uses contextual embeddings for their superior performance across virtually all tasks.
2.33.1.3 Text Representation: From Sparse Vectors to Embeddings¶
The leap from sparse bag-of-words representations to dense word embeddings was one of the most transformative moments in NLP history. In a bag-of-words model, a vocabulary of fifty thousand words creates a fifty-thousand-dimensional vector for each document, mostly filled with zeros. This is computationally expensive and ignores the relationships between words — “king” and “queen” are no closer to each other than “king” and “refrigerator.”
Word2Vec, introduced by Google researchers in 2013, solved this elegantly. By training a shallow neural network to predict surrounding words in context, Word2Vec produces compact, three-hundred-dimensional vectors where semantic relationships are encoded geometrically. The famous example: vector("king") - vector("man") + vector("woman") ≈ vector("queen"). For business analytics, this means that product reviews mentioning “durable,” “long-lasting,” and “built to last” can be recognized as expressing the same quality attribute, even if they share no words.
The next revolution came with contextual embeddings. In Word2Vec, “bank” always has the same vector regardless of whether it appears in “river bank” or “bank account.” BERT (Bidirectional Encoder Representations from Transformers), introduced by Google in 2018, generates different embeddings for the same word depending on its surrounding context, capturing the actual meaning intended. This was the breakthrough that brought near-human comprehension to machine text understanding.
33.2 Web Scraping: Acquiring Text Data at Scale¶
3.13.2.1 The Web as a Data Source¶
The World Wide Web is the single largest corpus of human-generated text ever assembled. For business analytics, it represents an extraordinary competitive intelligence resource: product reviews on Amazon and Yelp, job postings that reveal competitor hiring strategy, news articles tracking industry trends, social media posts capturing real-time consumer sentiment, government databases publishing regulatory filings, and academic repositories hosting research relevant to R&D decisions.
Web scraping — the automated extraction of data from websites — is the primary mechanism for harvesting this resource. The data acquired through scraping feeds directly into the NLP pipelines we discussed in the previous section. Understanding how scraping works, when it is appropriate, and how to do it responsibly is an essential competency for the modern business analyst.
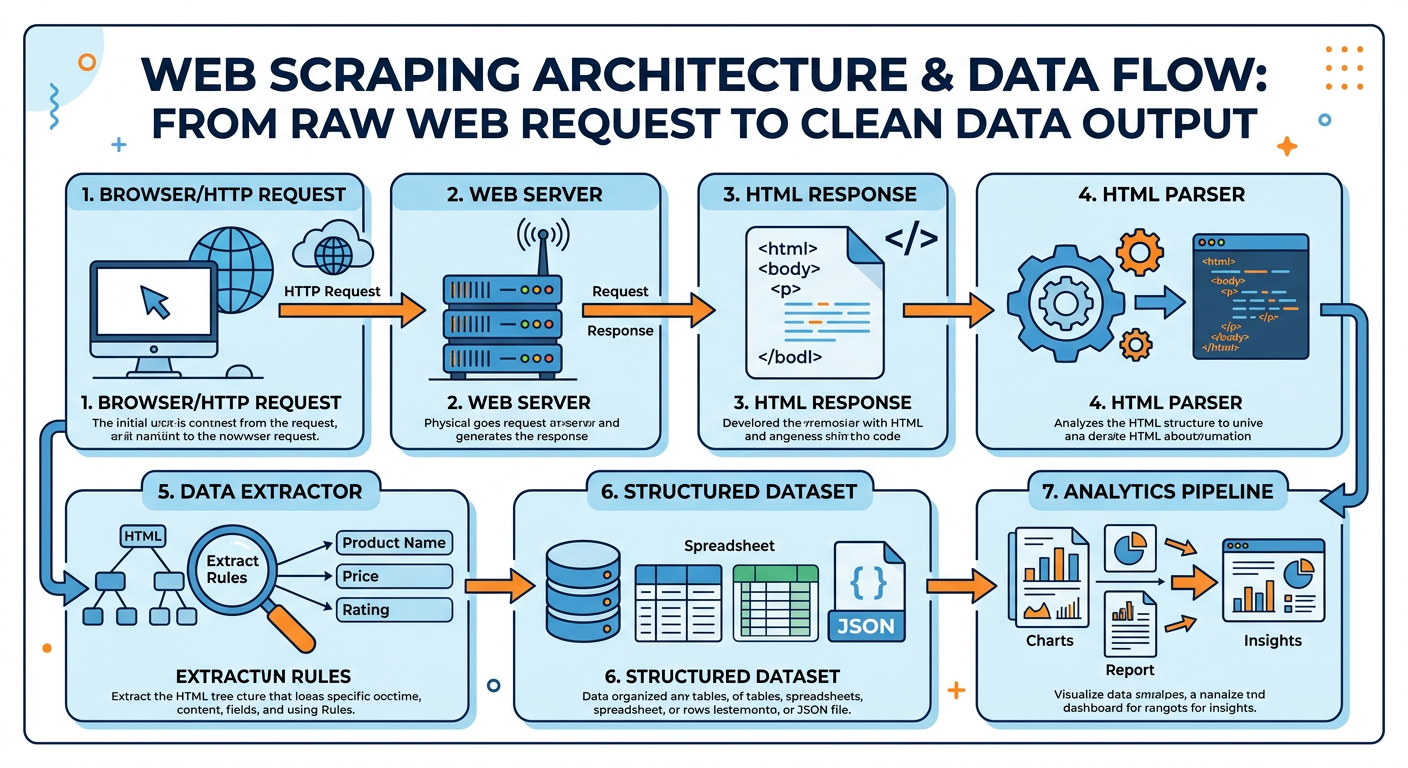
Figure 3:Web Scraping Architecture: from HTTP request to structured business data.
3.23.2.2 How Web Scraping Works: The Technical Mechanics¶
At its core, a web scraper performs three operations that any human browsing the web also performs — just much faster and more systematically:
Request: Send an HTTP GET request to a target URL, mimicking what a browser does when you type an address.
Parse: Receive the HTML response and parse its Document Object Model (DOM) structure to identify the elements containing the desired data.
Extract: Pull the target content from those elements and store it in a structured format (CSV, JSON, database).
The two dominant Python libraries for web scraping are Requests + BeautifulSoup for static pages, and Selenium or Playwright for dynamic JavaScript-rendered pages.
# Basic web scraping with Requests and BeautifulSoup
import requests
from bs4 import BeautifulSoup
import pandas as pd
url = "https://books.toscrape.com/"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
books = []
for article in soup.find_all('article', class_='product_pod'):
title = article.find('h3').find('a')['title']
price = article.find('p', class_='price_color').text.strip()
rating = article.find('p', class_='star-rating')['class'][1]
books.append({'title': title, 'price': price, 'rating': rating})
df = pd.DataFrame(books)
print(df.head())This example scrapes a public sandbox website designed for scraping practice. In a real business scenario, the same pattern applies — identify the HTML structure, write selectors to target the relevant elements, and loop across pages or categories.
For modern web applications built with React, Angular, or Vue.js, the initial HTML response contains almost no content — it is populated dynamically by JavaScript after page load. In these cases, Selenium or Playwright can control a real browser programmatically, wait for JavaScript to execute, and then extract the fully rendered DOM.
# Dynamic page scraping with Playwright
from playwright.sync_api import sync_playwright
import pandas as pd
with sync_playwright() as p:
browser = p.chromium.launch(headless=True)
page = browser.new_page()
page.goto("https://example-spa.com/reviews")
page.wait_for_selector(".review-card") # Wait for JS to render
reviews = page.query_selector_all(".review-card")
data = [{'text': r.inner_text()} for r in reviews]
browser.close()
df = pd.DataFrame(data)3.33.2.3 APIs vs. Scraping: Choosing the Right Approach¶
Before writing a scraper, the responsible analyst always asks: Does this source offer an official API? Many major platforms — Twitter/X, Reddit, LinkedIn, Google, Yelp, YouTube — offer Application Programming Interfaces (APIs) that provide structured data access through authenticated, rate-limited endpoints. APIs are preferable to scraping for several reasons:
Reliability: APIs return clean, structured JSON/XML, eliminating parsing complexity.
Legality: API use is explicitly authorized; scraping may not be.
Stability: Websites change their HTML structure frequently, breaking scrapers. APIs maintain backward compatibility.
Rate Control: APIs impose transparent rate limits, reducing the risk of overloading servers.
However, APIs are often restricted, expensive at scale, or simply unavailable for the data you need. In those cases, scraping may be the only option — subject to legal and ethical constraints.
3.43.2.4 Handling Real-World Scraping Challenges¶
Production scrapers face a gauntlet of challenges beyond simple HTML parsing. Modern websites actively defend against automated access using CAPTCHAs, rate limiting, IP blocking, and dynamic content rendering. Below are the most common challenges and standard mitigation strategies.
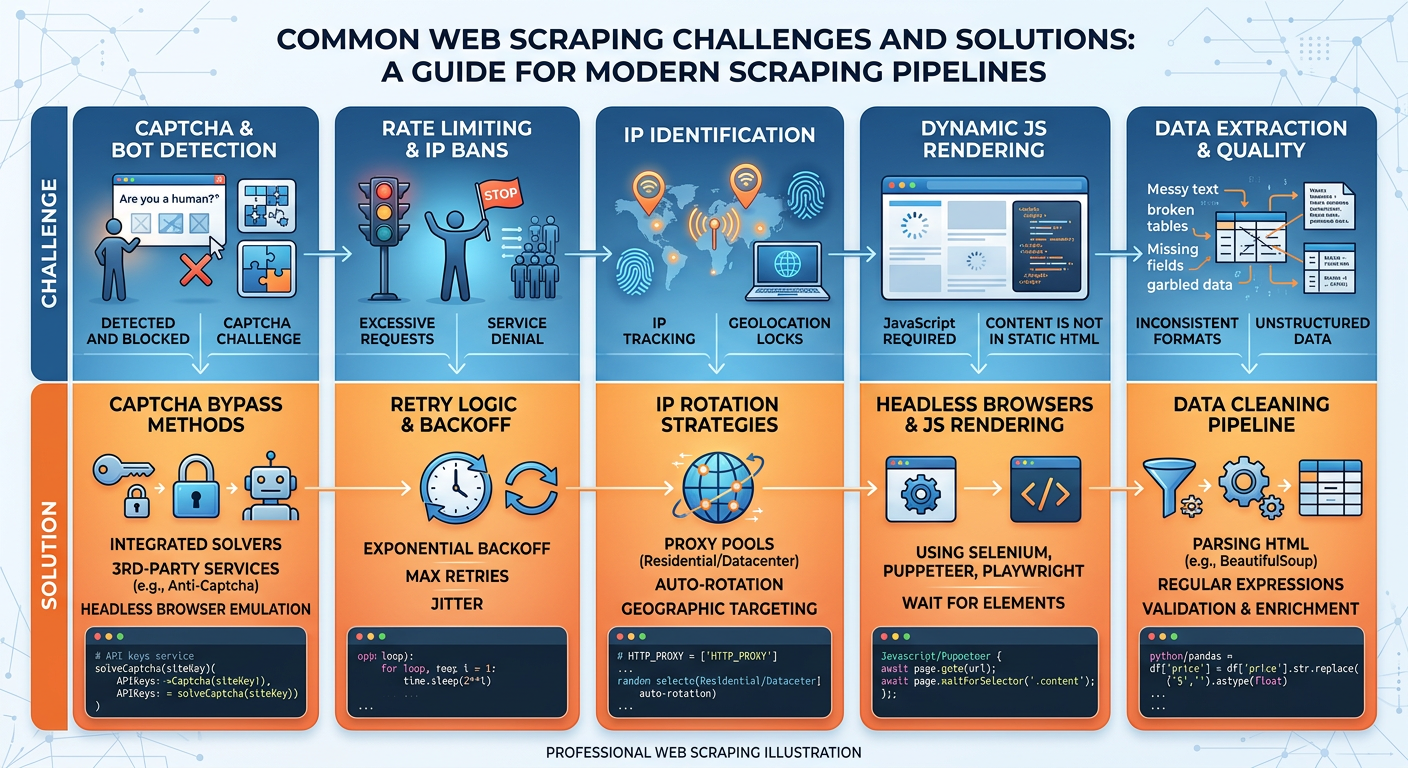
Figure 4:Web Scraping Challenges and Mitigation Strategies in Production Environments.
Rate Limiting and Politeness: Sending hundreds of requests per second to a web server can overwhelm it — a behavior that resembles a denial-of-service attack. Ethical scrapers implement delays between requests (time.sleep(random.uniform(1, 3))), respect Crawl-delay directives in robots.txt, and schedule scraping jobs during off-peak hours.
IP Blocking: Sites track request frequency per IP address and block sources that exceed thresholds. Mitigations include rotating through proxy IP pools, using residential proxies that appear as human users, and spreading scraping across extended time windows.
Dynamic Content: As discussed, JavaScript-heavy pages require browser automation. Playwright is currently the industry standard for this, offering more reliability than Selenium and better headless browser support.
Data Quality: Raw scraped text is messy — HTML entities like &, Unicode artifacts, extra whitespace, embedded JavaScript fragments, and navigation boilerplate. A robust cleaning pipeline (regex, BeautifulSoup get_text(), ftfy for Unicode repair) is as important as the scraper itself.
43.3 Sentiment Analysis: Listening to What People Really Mean¶
4.13.3.1 Introduction to Sentiment Analysis¶
Sentiment analysis is arguably the single most commercially deployed NLP capability in the world today. It underpins product review aggregation on Amazon, brand monitoring dashboards at Brandwatch and Sprinklr, customer satisfaction scoring in contact centers, and real-time financial market sentiment feeds used by algorithmic traders. The intuition is simple: human language is saturated with evaluative content, and making that content quantifiable unlocks enormous analytical value.
Consider a simple example. An airline wants to understand how passengers feel about their new boarding process. They collect tweets mentioning their brand during the first month of the rollout. Sentiment analysis applied to those tweets might reveal that 68% are positive (“finally, boarding by zones is so much faster!”), 22% are negative (“why is zone 4 always last? this is discriminatory”), and 10% are neutral. The negative cluster, when further analyzed with topic modeling, groups into three themes: zone assignment fairness, carry-on space availability, and gate agent communication. Within forty-eight hours, operations leadership has actionable, statistically grounded feedback that previously would have taken weeks to surface through surveys.
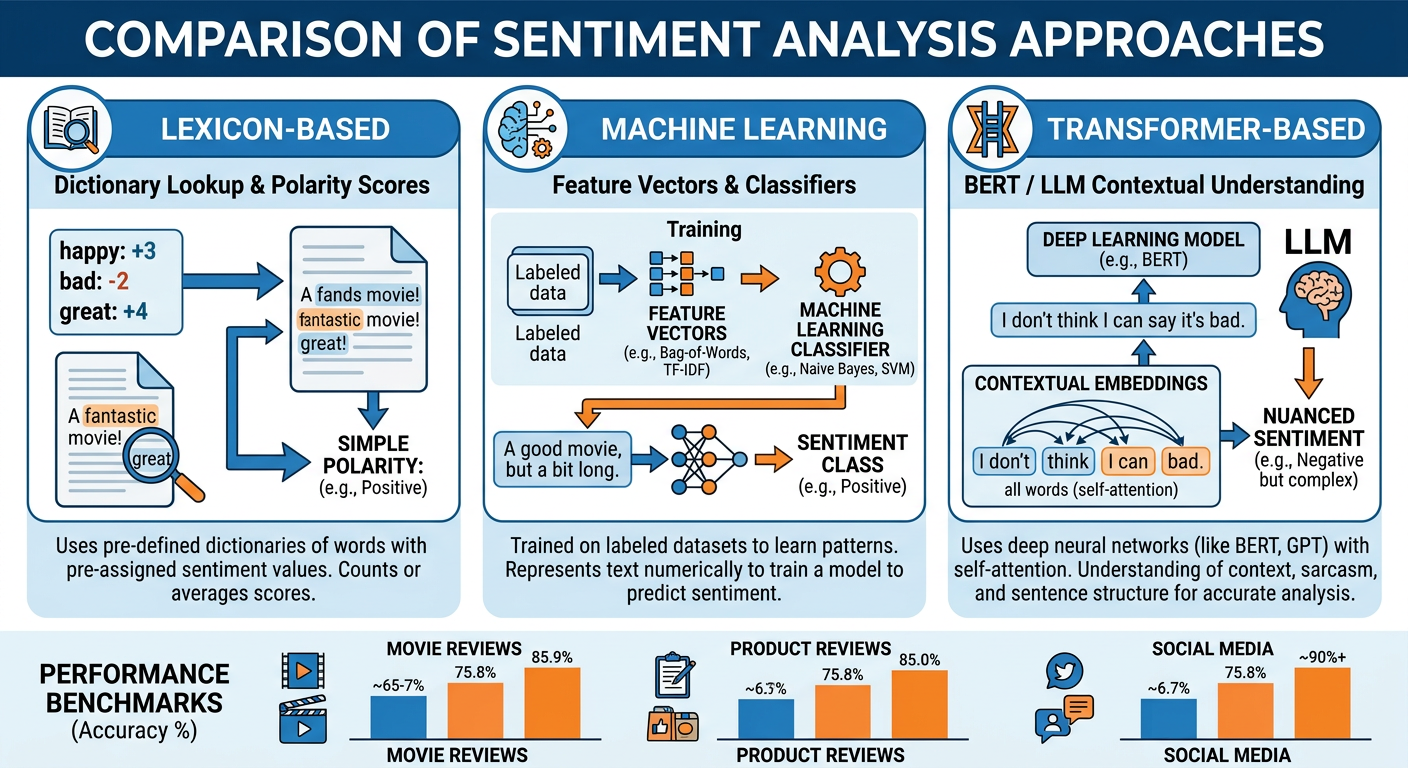
Figure 5:Three Generations of Sentiment Analysis: from lexicons to transformers.
4.23.3.2 Approaches to Sentiment Analysis¶
Three generations of sentiment analysis methodology have evolved over the past two decades, each superseding but not entirely replacing its predecessor.
Generation 1: Lexicon-Based Approaches
Lexicon-based methods rely on curated dictionaries that assign polarity scores to individual words. The system scores a document by summing the polarity of its constituent words. Popular lexicons include:
VADER (Valence Aware Dictionary and sEntiment Reasoner): Specifically designed for social media text, VADER handles slang, emoji, capitalization, and punctuation-based emphasis.
SentiWordNet: Assigns positive, negative, and objectivity scores to WordNet synsets.
AFINN: A simple list of English words rated from -5 (very negative) to +5 (very positive).
from vaderSentiment.vaderSentiment import SentimentIntensityAnalyzer
analyzer = SentimentIntensityAnalyzer()
texts = [
"This product is absolutely AMAZING!!!",
"Worst experience I've ever had. Never again.",
"The package arrived on Tuesday."
]
for text in texts:
scores = analyzer.polarity_scores(text)
print(f"Text: {text[:40]}...")
print(f"Scores: {scores}\n")
# Output example:
# compound: 0.8519 (Very Positive)
# compound: -0.7906 (Very Negative)
# compound: 0.0000 (Neutral)Lexicon-based methods are fast, require no labeled training data, and are interpretable — you can explain exactly why a document received a particular score. Their weakness is handling context and domain specificity. In financial text, “the stock is killing it” is positive, but “the drug killed all test subjects” is catastrophic. Generic lexicons cannot make these distinctions.
Generation 2: Machine Learning Classifiers
Supervised machine learning approaches treat sentiment classification as a standard text classification problem. A labeled dataset (e.g., Amazon reviews with star ratings as proxies for sentiment) trains a classifier — Naive Bayes, Logistic Regression, Support Vector Machine, or a simple neural network — to predict sentiment from TF-IDF or embedding features.
from sklearn.pipeline import Pipeline
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
# Assume df has 'text' and 'sentiment' columns (0=negative, 1=positive)
X_train, X_test, y_train, y_test = train_test_split(
df['text'], df['sentiment'], test_size=0.2, random_state=42
)
pipeline = Pipeline([
('tfidf', TfidfVectorizer(max_features=10000, ngram_range=(1,2))),
('clf', LogisticRegression(max_iter=500))
])
pipeline.fit(X_train, y_train)
predictions = pipeline.predict(X_test)
print(classification_report(y_test, predictions))ML classifiers outperform lexicon methods on in-domain tasks when sufficient labeled data is available. Their limitation is data hunger — you need thousands of labeled examples per domain — and their brittleness when applied to data that differs from the training distribution.
Generation 3: Transformer-Based Models
Pre-trained transformer models (BERT, RoBERTa, and domain-specific variants like FinBERT for finance or BioBERT for biomedicine) represent the current state of the art. These models understand contextual meaning, handle negation naturally (“not good at all”), and transfer knowledge from massive pre-training corpora. Fine-tuning a BERT model for sentiment classification requires only a few hundred to a few thousand labeled examples to achieve accuracy that previously required hundreds of thousands.
from transformers import pipeline
# Zero-shot sentiment analysis using a pre-trained model
sentiment_pipeline = pipeline(
"sentiment-analysis",
model="distilbert-base-uncased-finetuned-sst-2-english"
)
results = sentiment_pipeline([
"The new feature update completely ruined my workflow.",
"I cannot imagine using any other product — it's that good.",
"The delivery was on time as expected."
])
for r in results:
print(f"Label: {r['label']}, Score: {r['score']:.4f}")In the AI era, even zero-shot prompting of a large language model (sending a review to GPT-4o, Claude Sonnet 4.5, or Gemini 2.0 Flash with the instruction “classify the sentiment of this text”) often matches or exceeds fine-tuned classifiers, with the added benefit of requiring no labeled data and producing explanations for its classifications.
4.33.3.3 Aspect-Based Sentiment Analysis (ABSA)¶
Document-level sentiment (“this restaurant review is mostly positive”) is useful but coarse. Aspect-Based Sentiment Analysis (ABSA) goes further, identifying sentiment expressed toward specific attributes or aspects of a product or service. A hotel review might be positive about location and room size, but negative about Wi-Fi speed and breakfast quality — all within the same document. Document-level analysis would label this review “mixed” and lose the granularity that matters most for operations.
4.43.3.4 Challenges and Pitfalls in Sentiment Analysis¶
Even the best sentiment analysis systems struggle with linguistic phenomena that humans navigate effortlessly.
Negation: “This is not a bad product” is positive, but naive word-matching classifies it as negative. Transformer models handle this much better than classical approaches.
Sarcasm and Irony: “Oh great, another software update that breaks everything.” The literal words are positive; the meaning is deeply negative. Sarcasm detection remains an open research problem, particularly in short texts without much contextual signal.
Domain Shift: A model trained on restaurant reviews performs poorly on software documentation feedback. Always validate your sentiment model on a sample of in-domain data before deploying it.
Multilinguality: English NLP tools dominate the market, but many business contexts require sentiment analysis in Spanish, Portuguese, Mandarin, Arabic, or other languages. Multilingual models like mBERT and XLM-RoBERTa extend coverage, but quality still lags English for most languages.
Demographic and Cultural Bias: Sentiment models trained predominantly on English-language, Western internet data may systematically misclassify text from other cultural or socioeconomic contexts. This is a significant fairness concern in customer-facing applications.
53.4 Advanced Text Mining Applications in Business¶
5.13.4.1 Topic Modeling: Discovering Hidden Themes¶
The dominant classical algorithm is Latent Dirichlet Allocation (LDA), introduced by Blei, Ng, and Jordan in 2003. LDA assumes that each document is generated by sampling topics from a document-topic distribution, and then sampling words from each topic’s word-topic distribution. Given a corpus, LDA reverses this generative process through variational inference to discover the underlying topic structure.
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.decomposition import LatentDirichletAllocation
import numpy as np
# Assume 'documents' is a list of preprocessed text strings
vectorizer = CountVectorizer(max_df=0.95, min_df=2,
max_features=1000, stop_words='english')
doc_term_matrix = vectorizer.fit_transform(documents)
lda = LatentDirichletAllocation(n_components=10, random_state=42,
max_iter=20, learning_method='online')
lda.fit(doc_term_matrix)
feature_names = vectorizer.get_feature_names_out()
for topic_idx, topic in enumerate(lda.components_):
top_words = [feature_names[i] for i in topic.argsort()[:-11:-1]]
print(f"Topic {topic_idx}: {', '.join(top_words)}")Modern alternatives to LDA include BERTopic, which uses BERT embeddings and clustering to discover topics with far superior coherence. BERTopic topics are typically more human-interpretable because they emerge from semantic similarity in embedding space rather than word co-occurrence statistics.
Business Application: A financial services company processes ten years of CFPB (Consumer Financial Protection Bureau) complaint narratives. LDA reveals topic clusters corresponding to complaint categories: billing disputes, unauthorized charges, identity theft, collections harassment, and credit reporting errors. Year-over-year topic prevalence trends reveal that identity theft complaints doubled between 2020 and 2022 — a signal that no structured field in the complaint database captured.
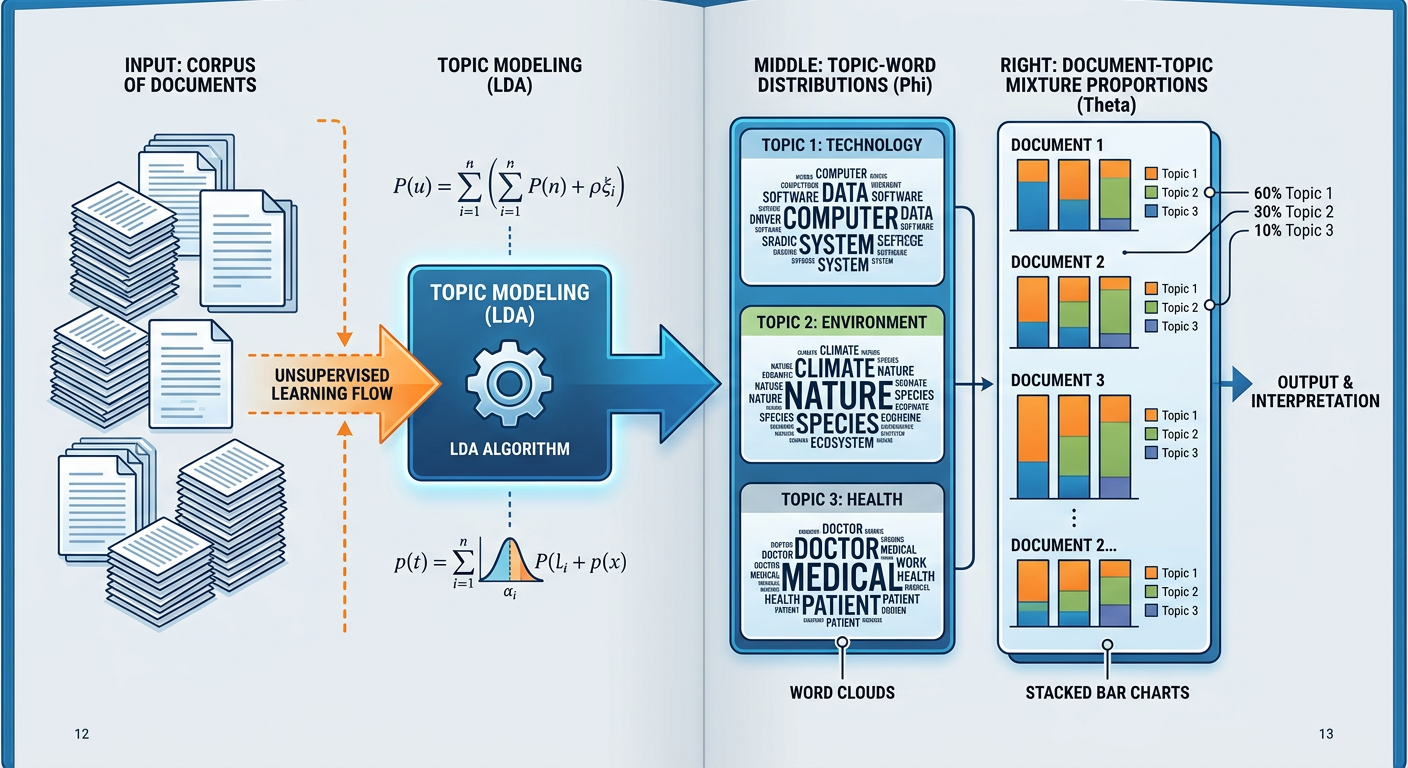
Figure 6:Topic Modeling with LDA: discovering latent themes in document collections.
5.23.4.2 Named Entity Recognition (NER)¶
Named Entity Recognition (NER) is the NLP task of identifying and classifying named entities in text into predefined categories: persons (PER), organizations (ORG), locations (LOC), dates (DATE), monetary values (MONEY), and more. NER is a fundamental building block for information extraction pipelines.
import spacy
nlp = spacy.load("en_core_web_sm")
text = """Apple Inc. announced on October 26, 2023 that CEO Tim Cook
will present the Q4 earnings at their Cupertino headquarters.
Revenue exceeded $89.5 billion, beating analyst expectations."""
doc = nlp(text)
for ent in doc.ents:
print(f"{ent.text:<30} {ent.label_:<15} {spacy.explain(ent.label_)}")
# Output:
# Apple Inc. ORG Companies, agencies, institutions
# October 26, 2023 DATE Absolute or relative dates
# Tim Cook PERSON People, including fictional
# Cupertino GPE Countries, cities, states
# Q4 DATE Absolute or relative dates
# $89.5 billion MONEY Monetary values including unitIn business analytics, NER enables relationship extraction (who did what to whom), knowledge graph construction (mapping relationships between companies, executives, and events), and compliance monitoring (detecting mentions of regulated entities in communications).
5.33.4.3 Text Classification for Business Intelligence¶
Beyond sentiment, text classification addresses many high-value business problems:
Intent Detection: Is this customer message a question, a complaint, a cancellation request, or a compliment? Routing based on detected intent reduces average handle time in contact centers.
Urgency Scoring: Which support tickets require immediate escalation? A classifier trained on historical escalation data can triage incoming tickets in real time.
Regulatory Compliance: Does this email contain language that triggers reporting obligations under financial regulations?- Contract Categorization: Does this vendor agreement belong to the “software licensing,” “professional services,” or “hardware maintenance” category for procurement reporting?
The practical implementation of text classification in enterprise settings relies heavily on the same transfer learning paradigm discussed throughout this chapter. A pre-trained sentence transformer (such as sentence-transformers/all-mpnet-base-v2 from Hugging Face) can be fine-tuned for a specific classification task with a few hundred labeled examples, making high-quality text classification accessible to organizations without large NLP research teams.
63.5 Real-World Case Study: How JPMorgan Chase Deploys NLP at Scale (2025)¶
Few organizations illustrate the business value of text and web mining as vividly as JPMorgan Chase, whose NLP investments have grown from a single high-profile use case in 2017 to a broad enterprise capability by 2025. This case study examines the trajectory of that investment and the lessons it holds for the analytics profession.
6.13.5.1 Background: The COiN System and Its Legacy¶
In 2017, JPMorgan Chase publicized its COiN (Contract Intelligence) platform — an NLP system that automated the review of commercial loan agreements. Reviewing these contracts manually required approximately 360,000 hours of lawyer time annually. COiN processed the same volume of documents in seconds with higher accuracy, freeing attorneys to focus on interpretation, negotiation, and judgment-intensive work rather than mechanical extraction. The commercial impact was immediate and dramatic.
COiN demonstrated several capabilities that now seem foundational: named entity recognition to extract party names, dates, and financial terms; document classification to route contracts to the appropriate legal workflow; and information extraction to populate structured data fields from unstructured legal prose. The platform used a combination of supervised machine learning classifiers fine-tuned on labeled legal documents and rule-based extraction for high-precision fields like monetary amounts and dates.
6.23.5.2 The 2025 Expansion: From Documents to Dialogue¶
By 2025, JPMorgan’s NLP footprint has expanded dramatically. The bank’s AI research division has deployed large language models across three major use cases that illustrate the breadth of what modern NLP can accomplish in financial services.
Earnings Call Intelligence. JPMorgan’s quantitative research team uses LLM-powered systems to analyze earnings call transcripts in real time. When a CEO uses hedging language (“we expect... subject to market conditions”) versus confident language (“we will deliver”), sentiment analysis models trained on financial domain data capture these signals within minutes of a call ending. These signals feed directly into quantitative trading strategies that compete on the milliseconds-to-minutes timescale where NLP-derived alpha is meaningful. The bank’s research shows that transcript-derived sentiment signals retain predictive power for up to 48 hours post-announcement after controlling for traditional financial variables.
Regulatory Intelligence. The bank processes thousands of regulatory documents, enforcement actions, and comment letters from the Federal Reserve, OCC, FDIC, and SEC each year. An NLP pipeline extracts regulatory requirements, maps them to internal policy documents, identifies gaps, and flags new obligations for compliance review. In an environment where regulatory complexity has increased substantially following post-2022 amendments to Basel III capital requirements and expanding crypto-asset guidance, this capability represents significant risk management value.
Customer Communication Mining. JPMorgan Chase processes millions of customer service interactions — phone calls (via speech-to-text), emails, chat transcripts, and secure messages — each month. An NLP platform extracts complaint themes, identifies dissatisfied customers at churn risk, detects potential fraud language patterns, and surfaces process failures that individual front-line representatives would never observe at the aggregate level. The customer experience team receives weekly topic reports identifying the top ten drivers of customer frustration, sorted by frequency and severity, enabling prioritized operational improvements.
6.33.5.3 Key Lessons for Business Analysts¶
The JPMorgan Chase NLP story offers several generalizable lessons for business analysts considering text analytics initiatives.
Start with high-frequency, high-value text sources. Contracts, customer communications, and regulatory documents are high-frequency (large volumes generated continuously), high-stakes (errors are costly), and text-intensive. These characteristics make them ideal targets for NLP investment. Less frequent, lower-stakes text sources — a quarterly CEO letter, for example — may not justify the infrastructure investment.
Domain-specific fine-tuning is non-negotiable. Generic NLP models perform poorly on financial, medical, or legal text because the vocabulary, conventions, and semantic patterns of these domains differ substantially from the general internet corpus on which base models are trained. FinBERT (trained on financial news and filings) outperforms BERT-base on financial sentiment tasks by a margin that often exceeds 10 percentage points in F1 score. Always budget for domain adaptation.
Human-in-the-loop remains essential. Even state-of-the-art NLP systems make errors that a domain expert would immediately recognize. High-stakes decisions — loan approval, regulatory compliance determination, litigation risk assessment — require human review of AI-flagged items. Design your NLP system as an intelligent triage and prioritization layer, not as a fully autonomous decision-maker.
Privacy and confidentiality require careful architecture. Financial institutions handle privileged communications, customer PII, and proprietary business information in their text corpora. Sending these documents to third-party commercial AI APIs may violate regulatory requirements, client confidentiality obligations, and data protection law. On-premise or private-cloud deployment of NLP models may be required in regulated industries.

Figure 7:JPMorgan Chase NLP Portfolio: four distinct text analytics use cases illustrating the breadth of enterprise NLP deployment in financial services.
73.6 Hands-On Activity: Sentiment Analysis and Topic Modeling with Google AI Studio¶
7.13.6.1 Activity Overview¶
In this hands-on activity, you will use Google AI Studio (aistudio.google.com) to explore text analytics concepts through direct experimentation with Google’s Gemini 2.0 Flash model. No coding is required — you will interact with the model through natural language prompts, which is itself an important skill for the modern business analyst who works with AI tools daily.
Learning Objectives:
Apply sentiment analysis concepts to real business text
Practice prompt engineering for NLP tasks
Experience topic modeling through LLM-based theme extraction
Critically evaluate AI-generated text analytics outputs
Estimated Time: 60–90 minutes
Prerequisites: Google account for Google AI Studio access
7.23.6.2 Activity Instructions¶
Phase 1: Sentiment Analysis Across Domains (20 minutes)
Navigate to Google AI Studio and create a new prompt session using the Gemini 2.0 Flash model.
Paste the following customer reviews into the prompt and ask the model to perform sentiment analysis, returning a polarity label (Positive/Negative/Neutral), a confidence score (0–1), and a brief explanation:
“The delivery arrived two days late and the packaging was clearly damaged. The product inside was fine, but the experience left me frustrated.”
“Absolutely cannot recommend this enough. The onboarding team was exceptional, the product works exactly as advertised, and we saw ROI within the first month.”
“It does what it says. Nothing special, nothing broken.”
“The customer support team tried their best but they simply couldn’t resolve my issue after four contacts over three weeks. I’m moving to a competitor.”
Vary your prompt approach for at least two of the reviews: once with a simple “analyze the sentiment” instruction, and once with a detailed prompt that asks the model to use a specific framework (e.g., valence + arousal, or polarity + subjectivity + aspect identification). Document how prompt design affects the output.
Phase 2: Topic Modeling from Customer Feedback (25 minutes)
Collect a set of 20–30 real customer reviews from a publicly accessible source — Google Maps reviews for a local restaurant, Amazon reviews for a consumer product, or app store reviews for a mobile application you use. Copy the review text only (no star ratings).
Ask Gemini to perform zero-shot topic modeling: identify the top 5 recurring themes in the reviews, describe each theme in two to three sentences, estimate the percentage of reviews that touch on each theme, and give an example review excerpt for each theme.
Compare the AI-derived topics to what you observed manually when reading the reviews. Where did the model excel? Where did it miss nuance or collapse related themes incorrectly?
Phase 3: Financial Text Analysis (20 minutes)
Find a recent (2025) earnings call transcript from a publicly traded company that interests you. CNBC, Seeking Alpha, and The Motley Fool publish free transcripts. Locate three to five paragraphs from the CEO or CFO remarks about business outlook and challenges.
Ask Gemini to perform aspect-based sentiment analysis on the transcript excerpt. Specifically: identify all named business aspects mentioned (revenue growth, specific product lines, market segments, competition, macro conditions), rate the sentiment expressed toward each aspect, and flag any hedging or uncertainty language that might carry negative implications despite positive surface framing.
Ask Gemini to compare this excerpt to a transcript from the same company from two years earlier (2023), if available, and identify the key narrative shifts in how management discusses business risk and opportunity.
Phase 4: Critical Reflection (15 minutes)
Write a 300–400 word reflection addressing: (1) One example where the AI’s text analysis surprised you — either positively or negatively — and what this reveals about the capabilities and limitations of current LLM-based NLP. (2) How would you validate whether the AI’s sentiment or topic outputs are accurate enough to trust in a business decision-making context? What ground truth or evaluation approach would you use? (3) Given what you experienced in this activity, how would you position AI-powered NLP tools relative to traditional coded NLP pipelines in a corporate analytics team? What are the tradeoffs?
83.7 Discussion Question: The Rise of AI-Powered Social Listening¶
8.13.7.1 Discussion Prompt¶
In 2025, Nestlé — one of the world’s largest consumer goods companies — announced that it had fully integrated an AI-powered social listening platform into its global brand management operations. The system processes over 50 million social media posts, news articles, and consumer reviews per day across 28 languages, using transformer-based NLP to detect sentiment shifts, identify emerging complaints, track competitive brand health, and flag potential product safety signals in real time. The platform replaced a manual process that previously required teams of analysts in each major market to review sampled text weekly.
Nestlé’s Chief Marketing Officer described the system as “the nervous system of our brand.” When a negative sentiment cluster about a product’s taste profile emerged in Brazilian social media in early 2024, the system flagged it within six hours of the trend beginning; a cross-functional team launched an investigation within 24 hours and confirmed a regional ingredient sourcing issue within 72 hours — a process that previously would have taken weeks to surface through sales data anomalies.
Drawing on the concepts, techniques, and frameworks discussed in this chapter, critically analyze the following questions:
What NLP capabilities — specifically — are required to build a system like Nestlé’s social listening platform? Map the technical components of the pipeline described (multi-language processing, sentiment analysis, topic/theme detection, anomaly flagging) to the specific methods covered in this chapter.
What are the most significant risks and failure modes of deploying this system in a real business context? Consider false positives, cultural and linguistic nuance challenges, sarcasm and irony at scale, and the risk of over-indexing on social media data that may not represent the company’s actual customer base.
The CMO describes the system as the company’s “nervous system.” Is this analogy apt or dangerous? What organizational and governance structures would you put in place to ensure that human judgment remains meaningfully in the loop when this system triggers a major operational response?
If you were the lead analytics architect for a competing consumer goods company with a $2 million annual budget for text analytics, how would you design a similar — but realistic — social intelligence capability? What compromises would you make, and what would your minimum viable product look like?
Your response should be approximately 400–600 words and should demonstrate integration of at least two specific concepts or frameworks from this chapter. Be prepared to share your perspective in class discussion.
8.2📝 Discussion Guidelines¶
Primary Response: Your initial post must address all parts of the prompt with depth and critical thinking. It must include at least one citation (scholarly or credible industry source) to support your argument.
Peer Responses: You must respond thoughtfully to at least two of your peers. Your responses must go beyond simple agreement (e.g., “I agree with your point”) and add substantial value to the conversation by offering an alternative perspective, sharing related research, or asking a challenging follow-up question.
93.8 Chapter Quiz¶
Instructions: Answer all 10 questions. Questions are a mix of multiple choice, true/false, and short answer. This quiz covers all sections of Chapter 3.
Question 1 Which step in the NLP pipeline assigns grammatical labels (noun, verb, adjective) to individual tokens, enabling downstream extraction of subject-verb-object relationships?
A) Tokenization
B) Stop Word Removal
C) Part-of-Speech (POS) Tagging
D) Named Entity Recognition
Question 2 True or False: Lemmatization and stemming always produce identical outputs because they both reduce words to their base forms using the same underlying linguistic rules.
Question 3 A business analyst wants to identify the major themes in 50,000 customer support tickets without using any labeled training data. Which approach is most appropriate?
A) Supervised text classification with logistic regression
B) Latent Dirichlet Allocation (LDA) topic modeling
C) VADER sentiment analysis
D) Named Entity Recognition (NER) with spaCy
Question 4 Explain the key difference between document-level sentiment analysis and aspect-based sentiment analysis (ABSA). Provide a concrete business example where ABSA provides meaningfully more valuable insight than document-level analysis.
Question 5 A hedge fund wants to analyze earnings call transcripts to extract signals about management confidence. Which sentiment analysis approach would likely perform best for this specific use case, and why?
A) VADER lexicon-based analysis
B) A generic bag-of-words logistic regression classifier trained on movie reviews
C) A domain-specific transformer model fine-tuned on financial text (e.g., FinBERT)
D) Manual keyword counting using a proprietary financial dictionary
Question 6 True or False: According to the chapter, APIs are always preferred over web scraping because they are faster, produce cleaner data, and are legally safer — and therefore web scraping has no legitimate business use case in 2025.
Question 7 A data science team is building a web scraper to collect product review data from a major e-commerce platform. List three specific technical or ethical challenges they are likely to encounter and briefly describe one practical mitigation strategy for each.
Question 8 In the context of word embeddings, what key limitation of the Bag-of-Words (TF-IDF) representation does Word2Vec address? Why does this limitation matter for business text analytics applications?
Question 9 Named Entity Recognition (NER) is described as “a fundamental building block for information extraction pipelines.” Provide two specific business applications where NER would be a critical component, explaining what entities would be extracted and how they would generate business value.
Question 10 You are the lead data analyst for a global airline that receives approximately 200,000 customer feedback submissions per month across email, social media, post-flight surveys, and call center transcripts in 12 languages. Leadership wants to move from monthly manual theme reviews to a near-real-time text analytics system.
Describe the end-to-end NLP architecture you would design, including: (a) how you would handle multilingual text, (b) which NLP techniques you would apply and in what sequence, (c) how you would validate the system’s outputs before trusting them for operational decisions, and (d) what governance structure you would put in place to ensure human oversight of AI-flagged issues. Aim for a response of 300–400 words.
103.9 The Future of Text and Web Mining: Large Language Models and Beyond¶
10.13.9.1 The LLM Revolution in Business Text Analytics¶
The emergence of large language models — GPT-4o, Claude Sonnet 4.5, Gemini 2.0 Pro, and their successors — has permanently altered the landscape of business text mining. For the first time, general-purpose language models trained on internet-scale text corpora can perform high-quality NLP tasks with zero or minimal task-specific training data, simply by receiving well-crafted instructions in natural language. This capability, called zero-shot prompting, collapses the traditional requirement for large labeled datasets and significantly reduces the time and cost of deploying NLP solutions in business contexts.
Consider the implications for a mid-sized manufacturing company that wants to analyze customer complaint emails. In the traditional ML paradigm, the team would need to: (1) label thousands of complaints by category, (2) train and tune a classifier, (3) evaluate performance, and (4) maintain the model as language patterns evolve. With a modern LLM, a skilled analyst can design a prompt that categorizes and extracts key information from complaint emails in a single API call, requiring no labeled data and minimal maintenance. For many business text analytics applications, the LLM approach is not only faster and cheaper but also more flexible — the prompt can be updated in minutes to accommodate new categories or extraction requirements.
10.23.9.2 Retrieval-Augmented Generation (RAG) for Business Text Analytics¶
One of the most practically important architectural patterns in enterprise NLP is Retrieval-Augmented Generation (RAG). The core challenge: a general-purpose LLM knows about the world up to its training cutoff, but it knows nothing about your company’s internal documents, proprietary product knowledge, or recent events after training. RAG solves this by dynamically retrieving relevant text chunks from a private knowledge base and providing them as context to the LLM at inference time.
A business use case: an insurance company wants a system that can answer agent questions about policy coverage terms. The company’s policy documents total millions of words across thousands of PDF files — far too much to include in a single LLM prompt, and too sensitive to train a public model on. A RAG architecture embeds all policy documents as vector representations in a vector database (Pinecone, Weaviate, or pgvector in PostgreSQL). When an agent submits a question, the system retrieves the most semantically relevant policy sections, constructs a prompt that includes those sections plus the question, and asks the LLM to answer based on the provided context. The result is accurate, grounded responses that cite specific policy sections — without hallucination, without exposing proprietary data to third-party training processes.
By 2025, RAG has become the dominant architecture for enterprise knowledge management applications, internal chatbots, compliance Q&A systems, and analyst research tools. The vector database market — essentially nonexistent in 2020 — exceeded $1 billion in annual revenue by 2025, fueled almost entirely by RAG deployments.
10.33.9.3 Multimodal Text Analytics: When Text Meets Images and Audio¶
The next frontier for business text analytics is multimodality — the ability to process and reason across multiple data types simultaneously. Modern foundation models like GPT-4o, Gemini 2.0, and Claude 3.5 Sonnet can analyze images alongside text, opening entirely new categories of business application.
In quality control, a manufacturer can send photographs of potentially defective components along with textual specifications and ask a multimodal model to assess conformance. In legal document review, scanned contracts can be processed directly as images without a separate OCR step. In market research, social media posts that combine image and caption can be analyzed holistically, capturing the visual-textual meaning that text-only analysis misses.
Audio transcription, powered by models like OpenAI’s Whisper and Google’s Chirp, has made voice data — historically one of the most underutilized business data sources — accessible to text analytics pipelines at enterprise scale. Sales calls, customer service recordings, earnings calls, and earnings call audio can now be transcribed at near-human accuracy and fed into the same NLP pipelines that process written text. Organizations that have deployed audio transcription at scale report that voice data consistently surfaces customer insights and risk signals that purely text-based channels miss.
10.43.9.4 Ethical Frontiers in Business NLP¶
As text and web mining capabilities become more powerful, the ethical stakes rise in proportion. Several emerging ethical issues deserve particular attention from business analytics professionals deploying these systems in 2025 and beyond.
Synthetic text and misinformation. The same LLM capabilities that make text analytics powerful also make it trivially easy to generate convincing fake reviews, fraudulent customer feedback, and synthetic social media posts. Companies deploying sentiment analysis and social listening systems must increasingly grapple with the possibility that their input data has been intentionally polluted. Detecting AI-generated text has become an active research area, but current classifiers are imperfect, especially against state-of-the-art generation models.
Worker monitoring and surveillance. Text analytics applied to employee communications — emails, Slack messages, meeting transcripts — enables unprecedented levels of organizational surveillance. While there are legitimate business intelligence applications (detecting insider threats, measuring organizational culture), there are also serious concerns about employee privacy, power asymmetry, chilling effects on communication, and potential violations of labor law. Organizations deploying employee communications analytics should do so transparently, with clear policies, explicit scope limitations, and robust access controls.
Copyright and intellectual property. Scraping web content and using it to train NLP models has prompted significant legal uncertainty following a wave of copyright litigation in 2023 and 2024. The New York Times v. OpenAI case, along with parallel actions by book authors and creative publishers, signals that the legal framework for using web-scraped text in AI systems is actively being contested. Business analytics teams building or fine-tuning NLP models on scraped data should consult legal counsel about the provenance and permissibility of their training corpora.