Chapter 4: Machine Learning & Large Language Models
Big Data, Data Centers, and the LLMs Reshaping Business
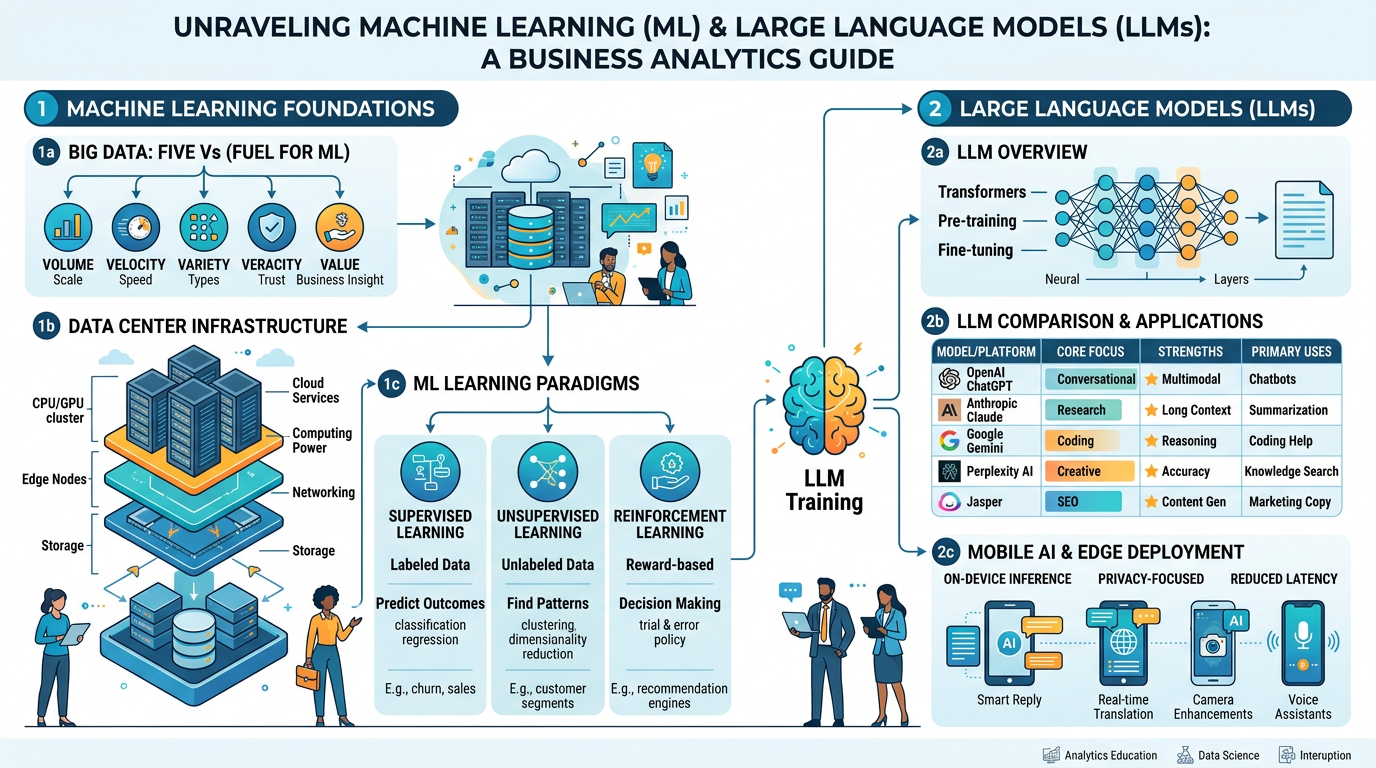
Figure 1:An illustrated overview of the machine learning landscape — from big data foundations and data center infrastructure to the large language models transforming business today.
“The heart of the discerning acquires knowledge, for the ears of the wise seek it out.”
Proverbs 18:15 (NIV)
We live in an era of unprecedented information abundance. Every day, humanity generates approximately 402.74 million terabytes of data — a number so vast it defies human comprehension. Every email sent, every social media post shared, every transaction processed, every sensor reading recorded, and every search query entered contributes to a growing ocean of data that doubles in size roughly every two years. This is the age of big data, and it has fundamentally changed what is possible with artificial intelligence.
In Chapter 1, we introduced the foundational concepts of AI and machine learning. In Chapter 2, we traced the historical arc from early neural networks to the deep learning revolution. In Chapter 3, we explored how NLP enables machines to understand and generate human language. Now, in this chapter, we bring these threads together to examine the powerful engines that drive modern AI: machine learning algorithms trained on big data, running on massive data center infrastructure, producing the large language models that are reshaping every industry.
This chapter is both technical and practical. You will understand the infrastructure — the physical data centers and cloud computing platforms — that make modern AI possible. You will learn how machine learning algorithms transform raw data into intelligent predictions. And you will conduct a thorough, comparative analysis of the leading LLMs — ChatGPT, Claude, Gemini, Perplexity, and Jasper — understanding their distinct strengths, limitations, and optimal business use cases.
As Christian business professionals, you will also grapple with important questions: What is the environmental cost of training massive AI models? Who controls the data that powers these systems? How do we make wise, stewardly decisions about which AI tools to adopt? The pursuit of knowledge is a godly endeavor — Proverbs 18:15 reminds us that “the heart of the discerning acquires knowledge” — but wisdom demands that we acquire that knowledge thoughtfully and deploy it responsibly.
1Big Data: The Fuel of Machine Learning¶
1.1What Is Big Data?¶
To understand why big data matters for machine learning, consider a simple analogy. Imagine learning to identify different dog breeds. If you have seen only three photographs of golden retrievers, your ability to recognize one in the wild will be limited. But if you have studied ten thousand photographs of golden retrievers — in different lighting, angles, sizes, ages, and settings — your recognition ability becomes remarkably robust. Machine learning works the same way: more high-quality data generally produces better models.
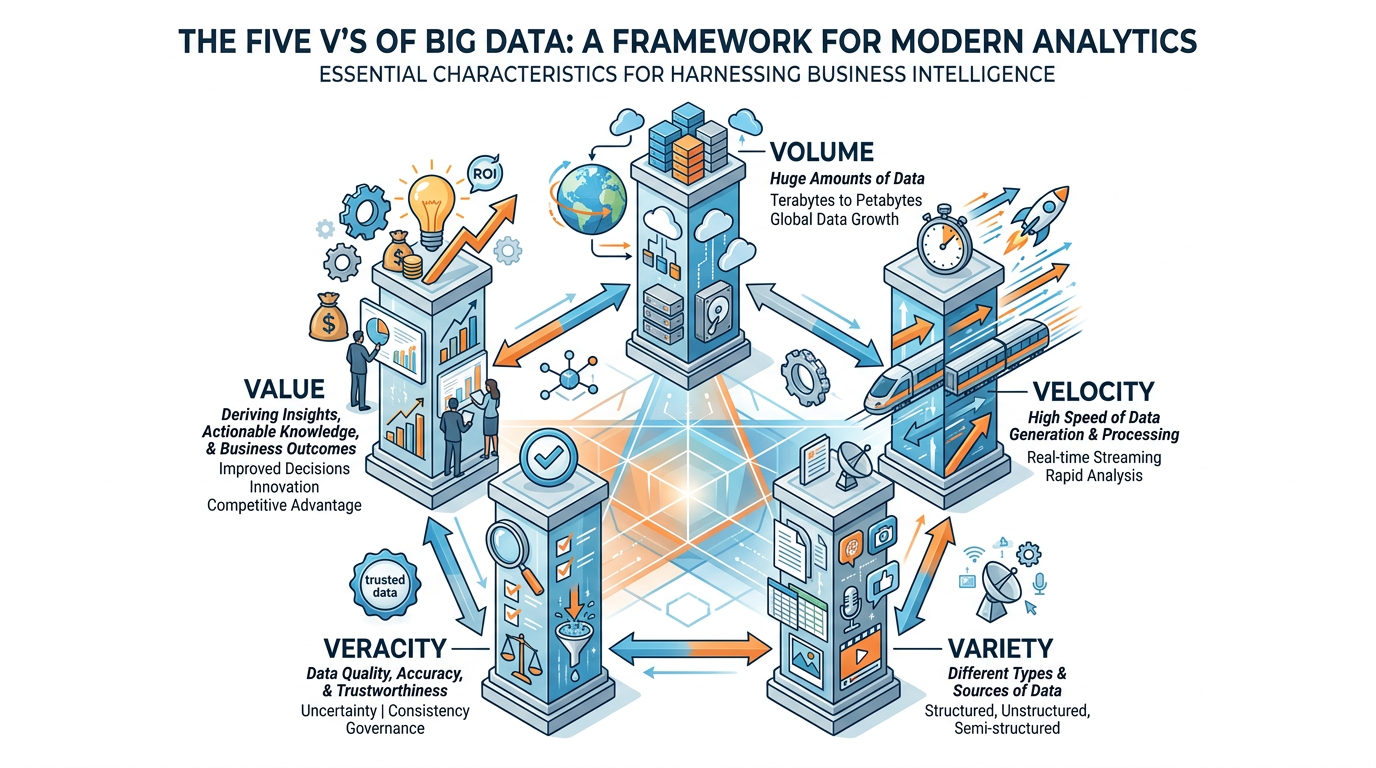
Figure 2:The Five V’s of Big Data — Volume, Velocity, Variety, Veracity, and Value — provide a framework for understanding the characteristics and challenges of modern data.
1.2The Five V’s Explained¶
Scale of data generated and stored.
2.5 quintillion bytes of data created daily
Walmart processes 1 million customer transactions per hour
YouTube users upload 500+ hours of video per minute
A single autonomous vehicle generates 4 TB of data per day
Traditional databases (SQL) max out at terabytes. Big data systems (Hadoop, Spark) handle petabytes and beyond.
Speed at which data is generated and must be processed.
Stock market trades execute in microseconds
Social media trends emerge and fade within hours
IoT sensors generate continuous real-time streams
Fraud detection must happen within milliseconds
Real-time processing is critical: a fraud alert that arrives 24 hours after the transaction is useless.
Diversity of data types and sources.
Structured: Database tables, spreadsheets (only ~20% of all data)
Semi-structured: JSON, XML, emails, log files
Unstructured: Text, images, video, audio, social media (~80% of all data)
The real challenge: combining structured sales data with unstructured customer reviews, social media posts, and call center recordings to build a unified customer view.
Trustworthiness and quality of data.
1 in 3 business leaders don’t trust their data
Duplicate records, missing values, inconsistent formats
Social media data includes bots, spam, and misinformation
Sensor data may include calibration errors
“Garbage in, garbage out” — ML models trained on low-quality data produce low-quality predictions, no matter how sophisticated the algorithm.
Business insights extracted from data.
Raw data has no inherent value — only processed data creates insights
The goal: turn terabytes of noise into actionable intelligence
Value extraction requires the right tools, skills, and strategy
Example: Netflix’s recommendation engine (built on big data) saves the company an estimated $1 billion annually in reduced customer churn.
1.3Big Data in Business: Where Does It Come From?¶
Table 1:Major Sources of Business Big Data
Source | Data Type | Volume | Business Application |
|---|---|---|---|
Transaction Systems | Structured (purchases, payments, returns) | Millions of records/day for large retailers | Sales forecasting, inventory optimization |
Social Media | Unstructured (posts, comments, images) | 500M+ tweets/day, 3.5B+ Instagram posts/day | Brand monitoring, trend analysis |
IoT Sensors | Semi-structured (temperature, location, motion) | Billions of readings/day across industries | Predictive maintenance, supply chain tracking |
Web & App Analytics | Semi-structured (clickstreams, session data) | Trillions of events/day globally | Conversion optimization, UX improvement |
Customer Service | Unstructured (calls, chats, emails) | Millions of interactions/day for enterprises | Quality monitoring, issue detection, training |
Enterprise Systems | Structured (ERP, CRM, HR, finance) | Varies; core operational data | Process optimization, workforce planning |
2Data Centers: The Physical Infrastructure of AI¶
2.1What Is a Data Center?¶
When you ask ChatGPT a question, search Google, or stream a Netflix movie, your request travels across the internet to a data center — often thousands of miles away — where powerful servers process your request and send the result back, all within milliseconds. Data centers are the invisible backbone of the digital economy.
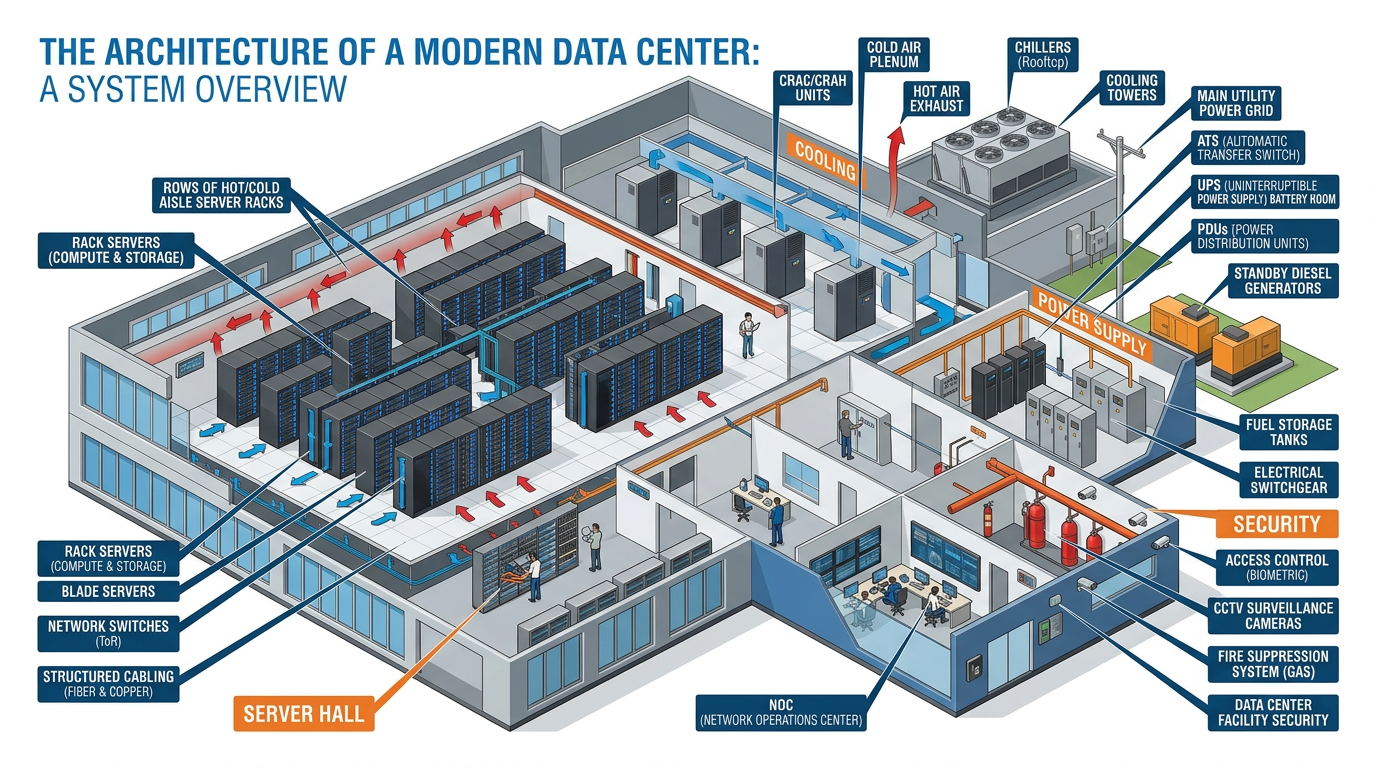
Figure 3:Inside a modern data center — the physical infrastructure that powers cloud computing, AI training, and the digital services we depend on daily.
2.2The Scale of Modern Data Centers¶
The scale of modern data centers is staggering:
Operated by: Google, Amazon (AWS), Microsoft (Azure), Meta, Apple
Scale:
Google operates 40+ data centers across 5 continents
Amazon’s AWS has 100+ data centers in 31 geographic regions
Microsoft Azure operates 60+ regions with hundreds of data centers
A single hyperscale facility may contain 100,000+ servers
Power Consumption:
A typical hyperscale data center consumes 20-50 megawatts of electricity
Google’s global data centers consumed approximately 18.3 terawatt-hours in 2022 — more than many small countries
Data centers globally consume approximately 1-2% of global electricity
The AI training challenge:
Training a large language model like GPT-4 or Gemini requires enormous computational resources:
Thousands of specialized GPUs (Graphics Processing Units) running simultaneously
Training runs that last weeks to months
Estimated cost of training GPT-4: $78-100 million
Power consumption for training a single large model: equivalent to the lifetime energy consumption of 5-10 American households
Key hardware:
NVIDIA H100/H200 GPUs: The dominant chips for AI training (~40,000 each)
Google TPUs (Tensor Processing Units): Custom chips designed specifically for AI workloads
High-bandwidth memory: Models require terabytes of fast-access memory
InfiniBand networking: Ultra-fast interconnects between GPUs for distributed training
The sustainability challenge:
Data centers have a significant environmental footprint:
Water usage: Large data centers use millions of gallons of water for cooling daily. Microsoft’s data centers consumed 6.4 billion liters of water in 2022.
Carbon emissions: Despite corporate commitments to clean energy, many data centers still rely partially on fossil fuels
E-waste: Server hardware is replaced every 3-5 years, generating significant electronic waste
Land use: Hyperscale campuses can span hundreds of acres
Industry responses:
Google has operated carbon-neutral since 2007 and aims for 24/7 carbon-free energy by 2030
Microsoft committed to being carbon negative by 2030
Amazon aims for net-zero carbon by 2040
Innovative cooling: underwater data centers (Microsoft’s Project Natick), liquid cooling, waste heat reuse
2.3Cloud Computing: Democratizing Data Center Access¶
Most businesses do not need to build their own data centers. Cloud computing platforms provide on-demand access to data center resources — computing power, storage, databases, machine learning tools, and AI services — on a pay-as-you-go basis.
Table 2:Major Cloud Computing Platforms
Platform | Provider | Market Share (2025) | Key AI/ML Services |
|---|---|---|---|
Amazon Web Services (AWS) | Amazon | ~31% | SageMaker, Bedrock (LLM access), Comprehend, Rekognition |
Microsoft Azure | Microsoft | ~25% | Azure OpenAI Service, Cognitive Services, Machine Learning Studio |
Google Cloud Platform (GCP) | ~11% | Vertex AI, Gemini API, BigQuery ML, AutoML | |
IBM Cloud | IBM | ~3% | Watson AI, watsonx, Watson Studio |
Oracle Cloud | Oracle | ~2% | OCI AI Services, Oracle Machine Learning |
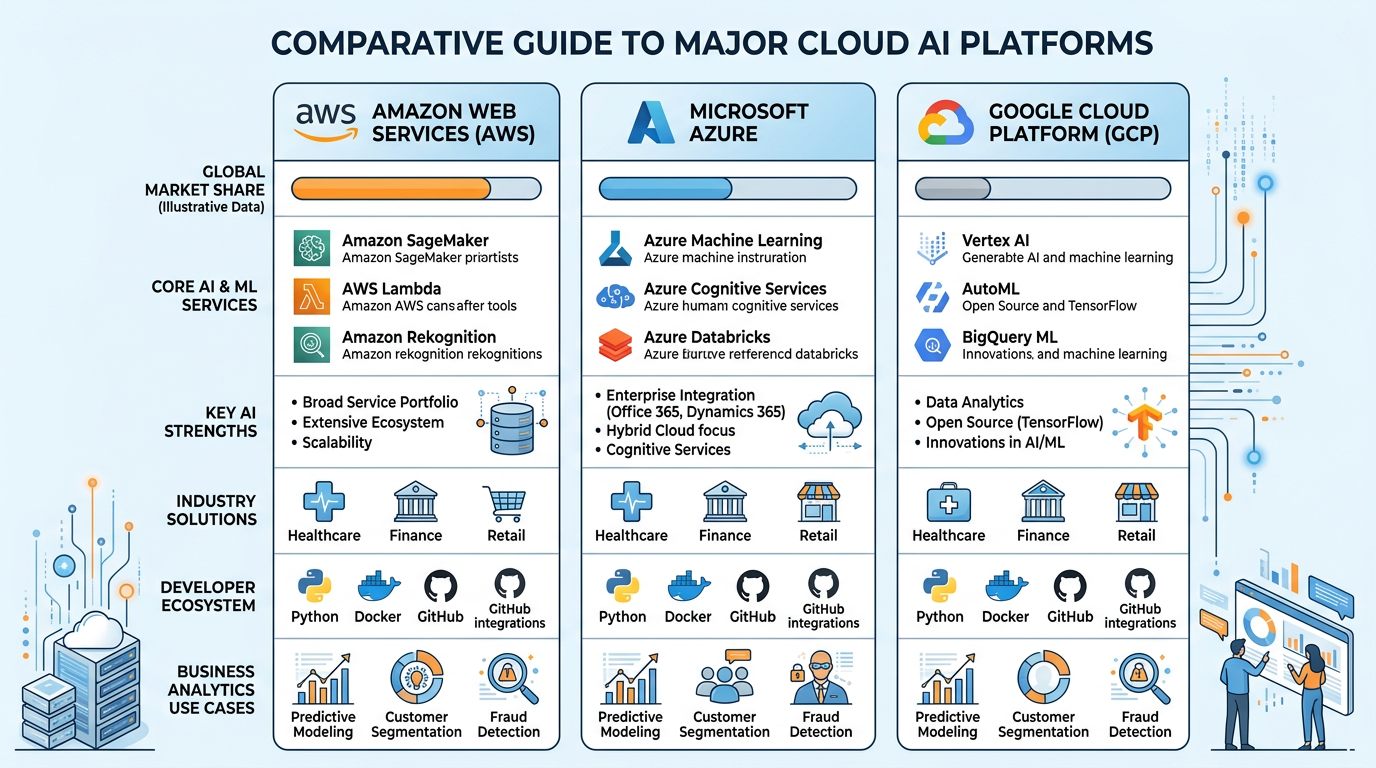
Figure 4:The three dominant cloud computing platforms — AWS, Azure, and Google Cloud — each offering comprehensive AI and machine learning services that power enterprise AI deployments.
3Machine Learning Foundations: How Machines Learn¶
3.1The Core Concept¶
At its heart, machine learning is about teaching computers to learn patterns from data rather than being explicitly programmed with rules. In Chapter 1, we introduced the three main types of machine learning. Let us now go deeper into how these approaches work and how businesses apply them.
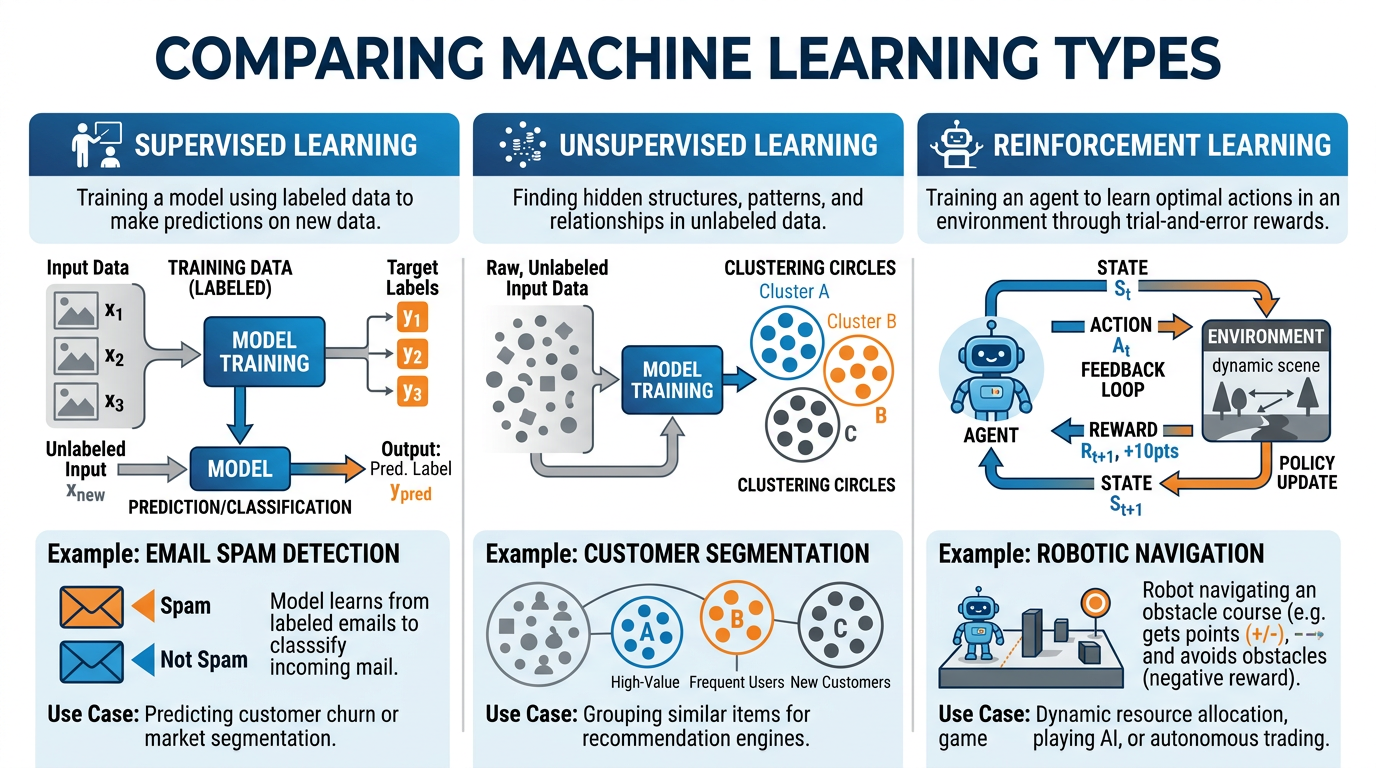
Figure 5:The three paradigms of machine learning — supervised, unsupervised, and reinforcement learning — each suited to different types of business problems.
3.2Supervised Learning: Learning from Labeled Examples¶
How it works: Imagine teaching a child to recognize fruits. You show them an apple and say “apple.” You show them a banana and say “banana.” After hundreds of examples, the child can identify apples and bananas they have never seen before. Supervised learning works the same way — the “labels” (apple, banana) are the supervision.
Business Applications:
Input: Email features (sender, subject, content, links) Label: Spam or Not Spam How it learns: Trained on millions of emails labeled by humans as spam or legitimate. Learns patterns — certain keywords, sender behaviors, link patterns — that predict spam.
Input: Customer financial data (income, debt, payment history, credit utilization) Label: Default or No Default How it learns: Trained on historical loan data where outcomes are known. Predicts the probability that a new applicant will default.
Input: Patient symptoms, test results, medical images Label: Diagnosis (disease present or absent) How it learns: Trained on thousands of cases with confirmed diagnoses. Can identify patterns that even experienced physicians might miss.
Input: Historical sales data, seasonality, marketing spend, economic indicators Label: Actual sales figures How it learns: Identifies relationships between input variables and sales outcomes, then projects future sales based on current conditions.
3.3Unsupervised Learning: Discovering Hidden Patterns¶
How it works: Imagine dumping a thousand photographs on a table with no labels. A human would naturally start grouping them — landscapes here, portraits there, food photos in another pile. Unsupervised learning does the same thing with data — finding natural groupings that humans might not have thought to look for.
Business Applications:
Customer Segmentation: Grouping customers by purchasing behavior, demographics, and preferences — without predefined categories. A retailer might discover a segment of “late-night impulse buyers who respond to flash sales” that no marketer had thought to target.
Anomaly Detection: Identifying unusual transactions that may indicate fraud, manufacturing defects that deviate from normal patterns, or network intrusions that differ from typical traffic.
Market Basket Analysis: Discovering products frequently purchased together (the famous “beer and diapers” correlation), enabling cross-selling and store layout optimization.
Topic Modeling: Automatically discovering themes in large document collections — what topics are customers discussing in their support tickets?
3.4Reinforcement Learning: Learning Through Trial and Error¶
How it works: Like training a dog — reward good behavior, discourage bad behavior. The learner tries different actions, observes the results, and gradually develops a strategy that maximizes rewards. Unlike supervised learning, there is no “correct answer” provided — the learner must discover the best strategy through experimentation.
Business Applications:
Dynamic Pricing: Airlines and ride-sharing platforms use reinforcement learning to adjust prices in real time based on demand, competition, and customer behavior
Recommendation Engines: Netflix and Spotify continuously refine recommendations based on what users actually watch or listen to (the reward signal)
Supply Chain Optimization: Autonomous systems learn to manage inventory, routing, and scheduling to minimize costs and maximize delivery speed
Robotics: Industrial robots learn complex assembly tasks through repeated attempts, improving with each iteration (explored further in Chapter 7)
3.5The Machine Learning Pipeline¶
Regardless of the type, every ML project follows a similar pipeline:
4Large Language Models: The AI Revolution¶
4.1What Is a Large Language Model?¶
Large language models represent the most significant practical breakthrough in AI since the invention of the internet. In just a few years, LLMs have gone from research curiosities to tools used daily by hundreds of millions of people. They power the chatbots you interact with, the writing assistants you may use for schoolwork, the coding tools developers rely on, and an increasingly large share of the customer service, marketing, and business intelligence activities across every industry.
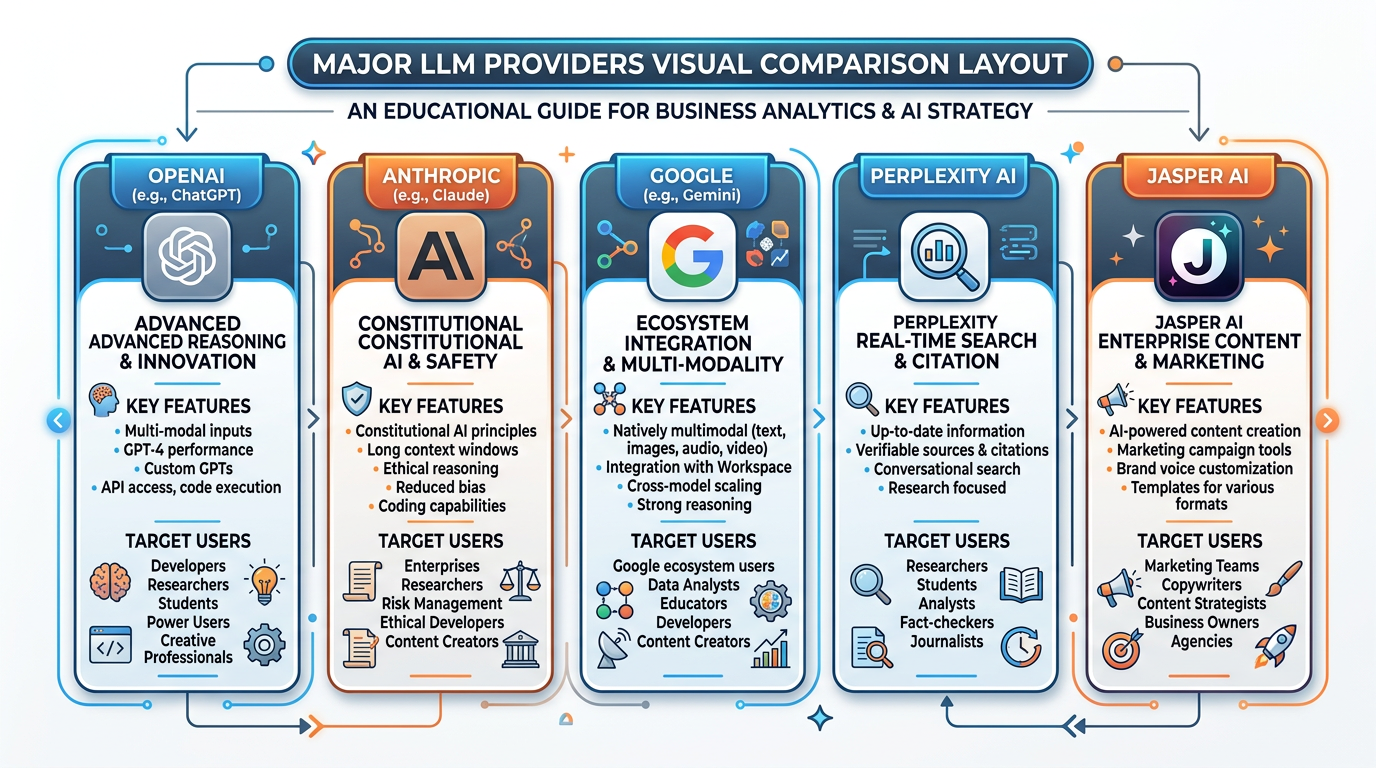
Figure 6:The large language model landscape — a comparison of the major LLM platforms reshaping how businesses operate, create, and compete.
4.2How LLMs Work: A Simplified Explanation¶
At a high level, LLMs work by predicting the next word (or token) in a sequence. During training, the model reads billions of sentences and learns the statistical patterns of language — which words tend to follow which other words, in what contexts. This seemingly simple mechanism, scaled to billions of parameters and trained on trillions of tokens, produces remarkably sophisticated behavior.
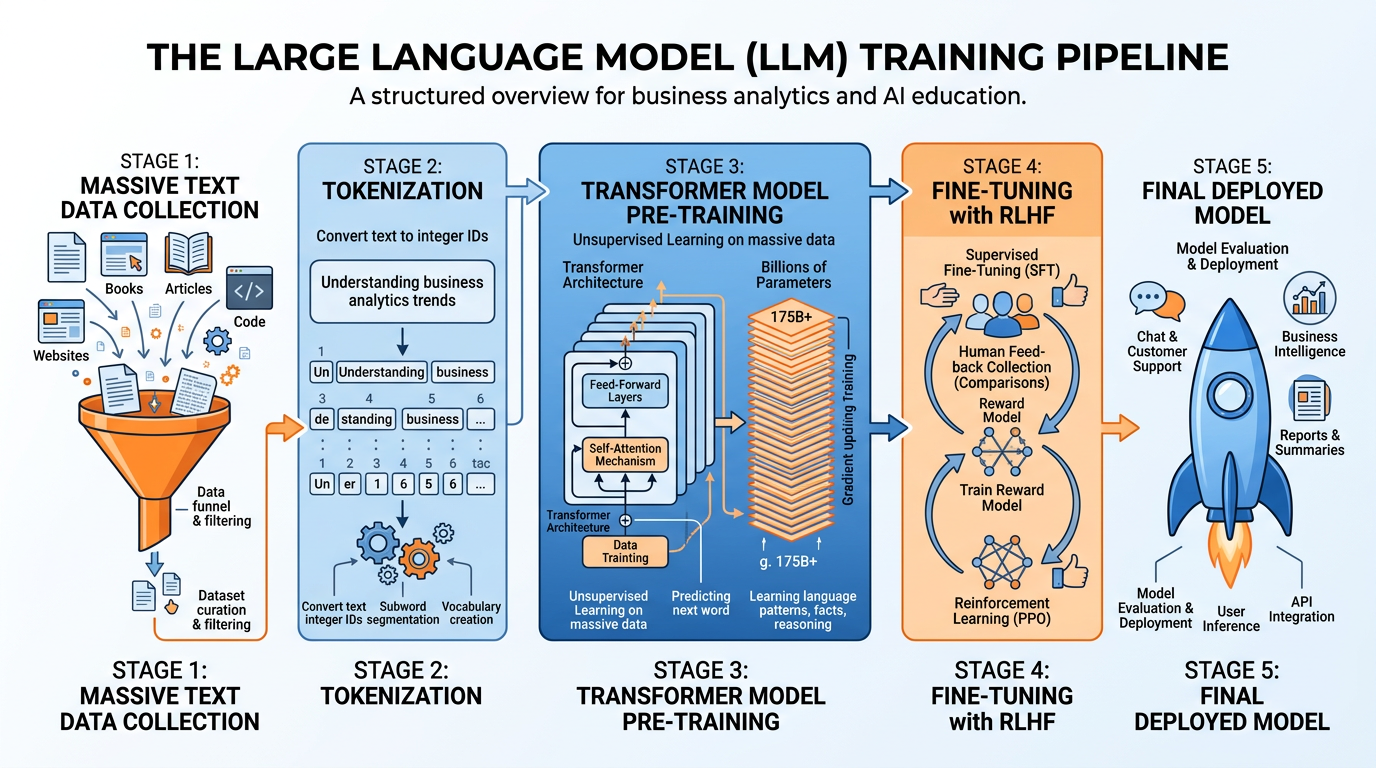
Figure 7:The LLM training pipeline — from raw internet text through tokenization, pre-training on transformer architecture, fine-tuning with human feedback, to the deployed model you interact with.
Key concepts:
Tokens: LLMs do not process whole words — they use subword tokens (as we discussed in Chapter 3). “Unhappiness” might become [“un”, “happi”, “ness”]. GPT-4 processes up to 128,000 tokens per conversation.
Parameters: The “knowledge” of an LLM is stored in billions of numerical weights. GPT-4 is estimated to have over 1.7 trillion parameters. Each parameter is adjusted during training to better predict the next token.
Context Window: The maximum amount of text an LLM can consider at once. A larger context window means the model can process longer documents, maintain longer conversations, and consider more information when generating responses.
RLHF (Reinforcement Learning from Human Feedback): After initial training, models are refined using human preferences — humans rate model outputs, and the model learns to produce responses that humans prefer. This is why ChatGPT gives helpful, harmless responses rather than simply predicting statistically likely text.
4.3The Hallucination Problem¶
5Comparing the Leading LLMs¶
The LLM landscape in 2025 features several major players, each with distinct strengths, architectures, and optimal use cases. Understanding these differences is essential for making informed business decisions about AI tool adoption.
5.1ChatGPT (OpenAI)¶
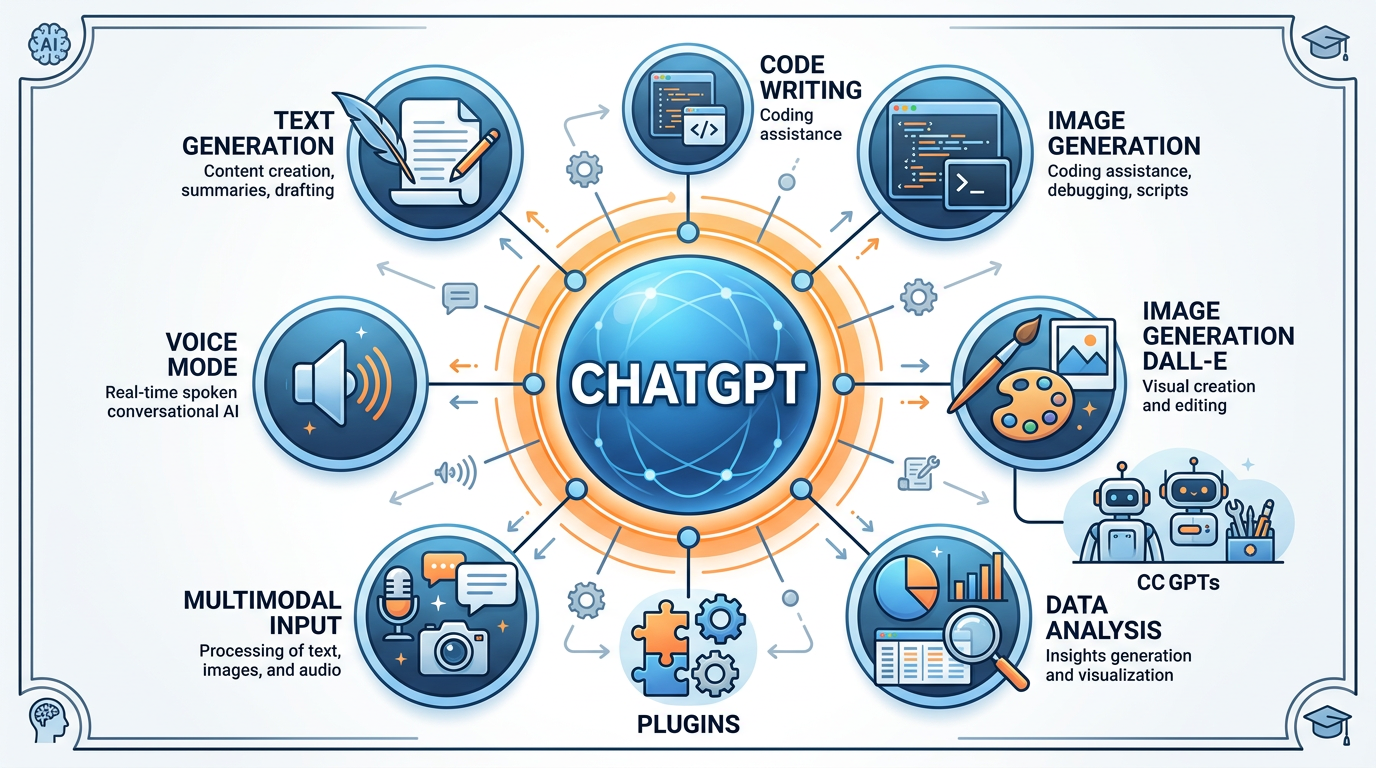
Figure 8:ChatGPT’s ecosystem of capabilities — from conversational AI and code generation to custom GPTs, plugins, and multimodal features that have made it the most widely adopted LLM platform.
Developer: OpenAI (founded 2015; partnership with Microsoft) Current Models: GPT-4o, GPT-4o mini, o1, o3-mini Users: 200+ million weekly active users (as of 2025) Pricing: Free tier (GPT-4o mini) / Plus (200/mo) / Team ($25/user/mo) / Enterprise (custom)
ChatGPT is the model that ignited the LLM revolution. Launched in November 2022, it reached 100 million users in just two months — the fastest-growing consumer application in history. Its intuitive conversational interface made advanced AI accessible to non-technical users for the first time.
Versatility: Excels across writing, coding, analysis, creative tasks, and conversation
Ecosystem: Custom GPTs (user-created specialized assistants), plugins, DALL-E image generation, Advanced Data Analysis (code interpreter)
Multimodal: Can process text, images, audio, and files
Context window: Up to 128K tokens (GPT-4o)
Coding: Consistently ranks among the top LLMs for code generation and debugging
Brand recognition: The default LLM most users think of; extensive third-party integrations
Hallucination: Still prone to generating plausible but incorrect information
Knowledge cutoff: Training data has a cutoff date (though browsing can supplement)
Cost: Advanced features require paid subscription; API costs can scale quickly
Privacy concerns: Conversations may be used for model training (unless opted out)
Censorship/Refusals: Sometimes overly cautious, refusing benign requests
Content creation: Marketing copy, blog posts, social media content
Code development: Writing, reviewing, and debugging code
Data analysis: Uploading spreadsheets for automated analysis and visualization
Customer service: Building custom GPTs for specific support workflows
Brainstorming: Idea generation, strategic planning, problem-solving
5.2Claude (Anthropic)¶
Developer: Anthropic (founded 2021 by former OpenAI researchers) Current Models: Claude 3.5 Sonnet, Claude 3.5 Haiku, Claude 3 Opus Pricing: Free tier / Pro (25/user/mo) / Enterprise (custom)
Anthropic was founded with a focus on AI safety — building helpful, harmless, and honest AI systems. Claude reflects this philosophy: it is designed to be thoughtful, nuanced, and careful in its responses, making it particularly well-suited for professional and enterprise applications.
Long context: Up to 200K tokens — can process entire books, codebases, or document sets in a single conversation
Writing quality: Known for nuanced, natural, and well-structured prose; preferred by many professional writers
Safety and honesty: More likely to acknowledge uncertainty, less prone to confidently stating falsehoods
Analysis depth: Excels at deep document analysis, summarization, and complex reasoning
Artifacts: Unique feature for creating interactive documents, code, and visualizations within the conversation
Constitutional AI: Trained using a novel approach that reduces harmful outputs without extensive human labeling
No image generation: Cannot create images (text and code only for output)
Fewer integrations: Smaller plugin/app ecosystem compared to ChatGPT
No real-time browsing: Relies on training data; cannot search the internet (as of early 2025)
Availability: Less widely available in some regions
Occasional over-caution: May refuse tasks that are perfectly appropriate
Legal and compliance: Contract analysis, regulatory review, policy drafting (benefits from long context)
Research and analysis: Processing lengthy documents, literature reviews, due diligence
Professional writing: Reports, proposals, executive summaries where quality matters
Code review: Thorough code analysis and refactoring
Sensitive communications: When careful, thoughtful language is critical
5.3Google Gemini¶
Developer: Google DeepMind Current Models: Gemini 2.0 Flash, Gemini 1.5 Pro, Gemini 1.5 Flash, Gemini Ultra Pricing: Free tier / Google One AI Premium ($19.99/mo, includes 2TB storage)
Gemini is Google’s flagship AI model and the most natively multimodal LLM — designed from the ground up to process text, images, audio, video, and code simultaneously (as explored in Chapter 3). Its integration with Google’s ecosystem (Search, Gmail, Docs, Sheets, YouTube) gives it unique advantages for productivity.
True multimodal: Native processing of text, images, audio, video, and code in a single model
Google integration: Deep integration with Google Workspace (Docs, Sheets, Gmail, Drive, Calendar)
Massive context: Gemini 1.5 Pro supports up to 2 million tokens — the largest context window of any major LLM
Real-time information: Connected to Google Search for up-to-date answers
NotebookLM: Powerful research tool that creates AI study guides, including audio “podcast” summaries
Cost effective: Generous free tier; competitive pricing for API access
Mobile: Deeply integrated into Android; available as default assistant
Image generation inconsistencies: Has faced criticism for inaccurate or biased image generation
Newer ecosystem: Third-party integrations still catching up to OpenAI
Regional availability: Some features limited outside the US
Google dependency: Full value requires investment in Google’s ecosystem
Accuracy: Some benchmarks show slightly lower factual accuracy than GPT-4 on certain tasks
Google Workspace users: Email drafting, spreadsheet analysis, document creation within the Google ecosystem
Research: NotebookLM for academic and business research synthesis
Multimodal tasks: Analyzing images, videos, and documents simultaneously
Mobile-first businesses: Android integration for on-the-go AI access
Cost-sensitive deployments: Competitive pricing for API-based applications
5.4Perplexity AI¶
Developer: Perplexity AI (founded 2022) Model: Uses multiple underlying models (GPT-4, Claude, proprietary) Pricing: Free tier / Pro ($20/mo)
Perplexity AI occupies a unique niche: it is an AI-powered research engine that combines LLM capabilities with real-time web search. Unlike ChatGPT or Claude, which generate responses from training data, Perplexity searches the internet in real time and generates responses with inline citations — making it the most verifiable LLM tool available.
Real-time search: Every response includes live web search results with citations
Source verification: Inline citations let you click through to original sources
Reduced hallucination: By grounding responses in real sources, hallucination risk is significantly lower
Research efficiency: Replaces the Google search → read multiple pages → synthesize cycle
Follow-up questions: Excellent at multi-turn research conversations, building on previous answers
Multiple models: Pro users can choose between different underlying models (GPT-4, Claude, etc.)
Limited creative generation: Not as strong for creative writing, brainstorming, or open-ended tasks
Dependent on web quality: Responses are only as good as the sources found online
No file processing: Cannot analyze uploaded documents (as of early 2025)
No image/code generation: Focused on research and information synthesis
Newer platform: Smaller community, fewer integrations
Market research: Real-time competitive intelligence with verified sources
Due diligence: Research on companies, people, and trends with citations
Fact-checking: Verifying claims and statistics with original sources
Current events: When up-to-the-minute information is critical
Academic research: Finding and synthesizing scholarly and professional sources
5.5Jasper AI¶
Developer: Jasper AI (founded 2021) Target: Marketing and business content teams Pricing: Creator (69/mo) / Business (custom)
Unlike general-purpose LLMs, Jasper is purpose-built for marketing and business content creation. It is designed for brand-consistent content at scale — maintaining tone, style, and messaging across all channels. Jasper is not a chatbot; it is a content production platform powered by AI.
Brand voice: Train Jasper on your brand’s style guide, tone, and terminology for consistent output
Marketing templates: 50+ pre-built templates for ads, emails, social posts, blog content, product descriptions
Campaign management: Create entire marketing campaigns with coordinated messaging across channels
SEO integration: Built-in SEO optimization for content
Team collaboration: Multiple users can share brand settings, campaigns, and content workflows
Enterprise features: SOC 2 compliance, SSO, team management, usage analytics
Narrow focus: Primarily marketing content — not suitable for coding, research, or analysis
Cost: Significantly more expensive than general-purpose LLMs
Underlying models: Uses GPT-4 and other models under the hood — you’re paying for the specialized interface and features, not a proprietary model
Learning curve: Brand training and template system require setup investment
Quality variance: Output quality depends heavily on the quality of inputs and brand training
Content marketing teams: Blog posts, articles, social media at scale
E-commerce: Product descriptions, category pages, marketing emails
Advertising: Ad copy, landing pages, A/B test variations
Brand management: Maintaining consistent voice across distributed teams
Campaign execution: Multi-channel content creation from a single brief
5.6Head-to-Head Comparison¶
Table 3:LLM Comparison Matrix
Feature | ChatGPT | Claude | Gemini | Perplexity | Jasper |
|---|---|---|---|---|---|
Primary Strength | Versatility | Analysis & Writing | Multimodal & Google | Research & Citations | Marketing Content |
Context Window | 128K tokens | 200K tokens | 2M tokens | Varies by model | N/A (template-based) |
Multimodal | Text, Image, Audio | Text, Image (input) | Text, Image, Audio, Video | Text only | Text only |
Real-time Web | Yes (with browsing) | No | Yes (Google Search) | Yes (core feature) | Limited |
Image Generation | Yes (DALL-E) | No | Yes (Imagen) | No | Yes (via integration) |
Best For | General business | Professional services | Google ecosystem | Research & verification | Marketing teams |
Free Tier | Yes (limited) | Yes (limited) | Yes (generous) | Yes (limited) | No |
Paid Price | $20/mo | $20/mo | $19.99/mo | $20/mo | $49-69/mo |
6Mobile AI: LLMs in Your Pocket¶
6.1The Mobile AI Revolution¶
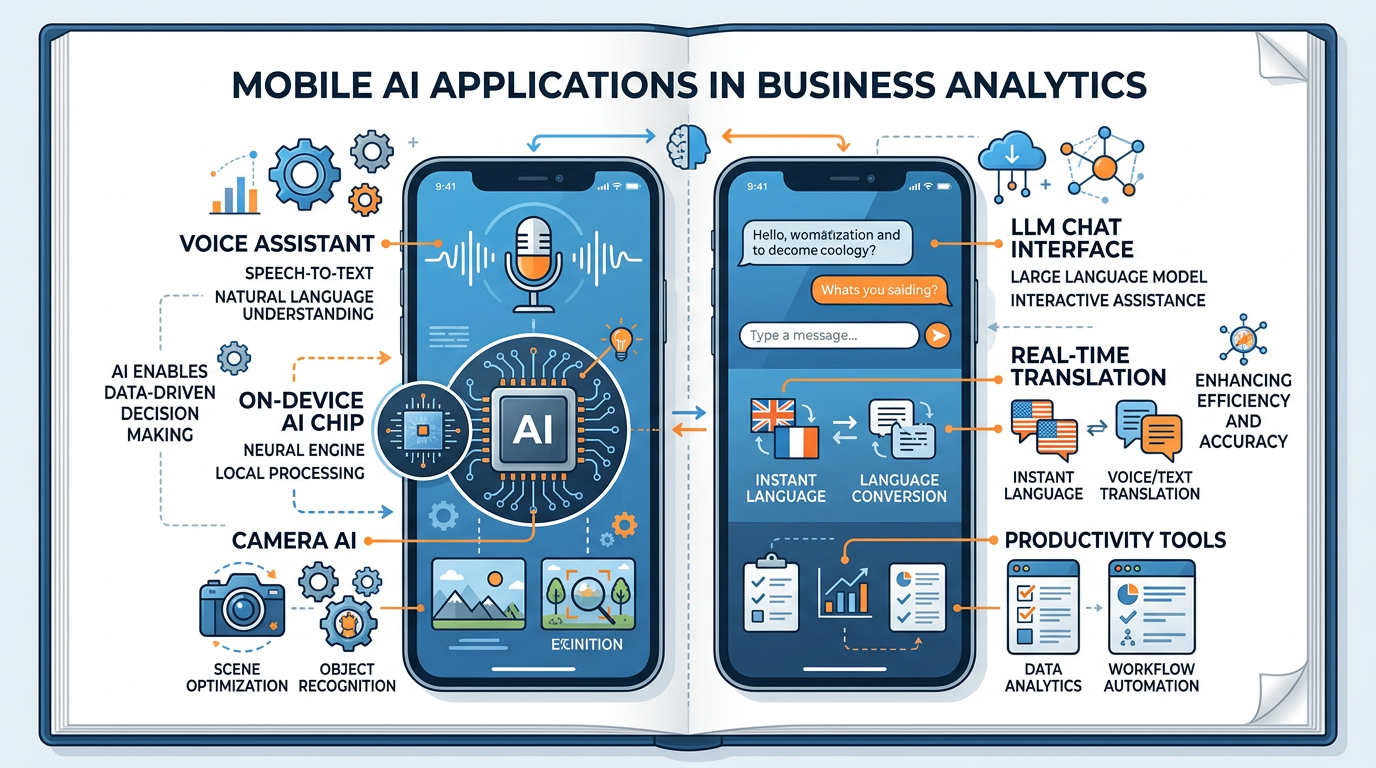
Figure 9:Mobile AI is bringing the power of large language models directly to smartphones — from intelligent assistants and on-device processing to AI-enhanced cameras and productivity tools.
The democratization of LLMs extends beyond desktop computers and web browsers. In 2024-2025, we are witnessing the rapid integration of AI capabilities directly into mobile devices — putting the power of large language models literally in your pocket.
6.2On-Device vs. Cloud AI¶
A critical distinction in mobile AI is where the processing happens:
How it works: Your phone sends your request over the internet to a data center, where powerful servers process it and send back the result.
Examples: ChatGPT mobile app, Google Gemini (for complex queries), Siri (for most requests)
Advantages:
Access to the most powerful models (GPT-4, Gemini Ultra)
No hardware limitations — processing power is in the cloud
Models can be updated without device updates
Disadvantages:
Requires internet connection
Latency (round-trip delay)
Privacy concerns (data leaves your device)
Ongoing costs (data usage, API fees)
How it works: AI models run directly on your phone’s processor, without sending data to the cloud.
Examples: Apple Intelligence, Google Gemini Nano, Samsung Galaxy AI
Advantages:
Works offline — no internet required
Zero latency — instant responses
Complete privacy — data never leaves your device
No ongoing cloud costs
Disadvantages:
Limited by phone hardware (smaller, less capable models)
Models are harder to update
Cannot handle the most complex tasks
Consumes battery and processor resources
6.3Mobile AI Business Applications¶
Mobile AI is creating new business opportunities and transforming existing workflows:
Technicians use mobile AI to diagnose equipment issues on-site — photographing a malfunctioning machine and getting instant diagnostic guidance through multimodal AI analysis.
In-store associates use mobile AI to instantly answer customer questions about product availability, specifications, and alternatives — accessing knowledge that previously required extensive training.
Clinicians use mobile AI for point-of-care decision support — analyzing symptoms, checking drug interactions, and accessing medical guidelines during patient encounters.
Sales representatives use mobile AI to prepare for meetings on the go — summarizing prospect information, generating talking points, and drafting follow-up emails between appointments.
7The Economics of LLMs: Costs, Pricing, and Business Models¶
7.1Understanding AI Costs¶
Deploying LLMs in business involves multiple cost dimensions that leaders must understand:
Table 4:LLM Cost Components
Cost Component | Description | Typical Range |
|---|---|---|
Subscription Fees | Monthly per-user cost for LLM platforms | $0-200/user/month |
API Usage (Input Tokens) | Cost per token for sending prompts to the model | $0.15-60 per 1M tokens |
API Usage (Output Tokens) | Cost per token for generated responses | $0.60-200 per 1M tokens |
Fine-tuning | Training a model on your specific data | $10,000-500,000+ depending on scale |
Infrastructure | Servers, GPUs, storage for self-hosted models | $50,000-1M+/year |
Integration | Development time to integrate AI into existing systems | $25,000-500,000+ depending on complexity |
Maintenance | Ongoing monitoring, retraining, and updates | 15-25% of initial deployment cost/year |
7.2Open Source vs. Proprietary LLMs¶
Examples: GPT-4 (OpenAI), Claude (Anthropic), Gemini (Google)
Advantages:
State-of-the-art performance
Managed infrastructure — no servers to maintain
Regular updates and improvements
Enterprise support and SLAs
Disadvantages:
Ongoing subscription/API costs
Data sent to third-party servers
Vendor lock-in
Limited customization
Examples: LLaMA 3 (Meta), Mistral, Falcon, Gemma (Google)
Advantages:
No licensing fees
Complete data privacy (run on your own servers)
Full customization and fine-tuning control
No vendor lock-in
Disadvantages:
Require technical expertise to deploy and maintain
Significant infrastructure costs for large models
Generally lower performance than leading proprietary models
Security and updates are your responsibility
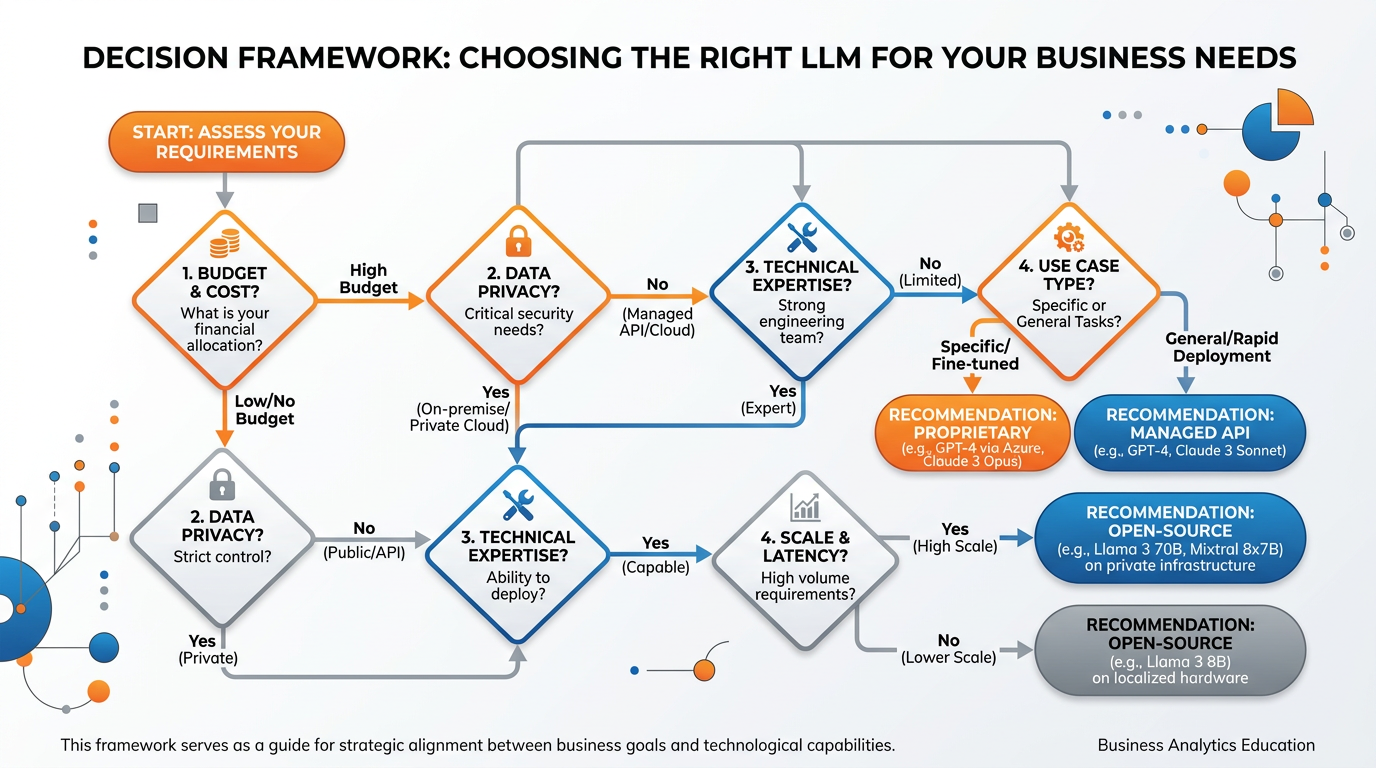
Figure 10:A decision framework for selecting the right LLM — guiding business leaders through key considerations including use case, budget, privacy requirements, and technical capabilities.
8Responsible AI: Bias, Fairness, and Accountability¶
8.1The Bias Challenge in Machine Learning¶
Machine learning models are only as fair as the data they are trained on and the objectives they are optimized for. Bias can enter the ML pipeline at every stage:
Case Study: Bias in Healthcare AI
A widely-used healthcare algorithm, deployed across major US hospitals, was found to systematically discriminate against Black patients. The system used healthcare spending as a proxy for healthcare needs — reasoning that patients who spent more on healthcare were sicker. But because of systemic inequities in healthcare access and insurance coverage, Black patients with the same level of illness spent significantly less on healthcare than white patients. The result: the algorithm recommended fewer resources for Black patients who were equally or more sick.
This case illustrates how bias can be invisible in the data: the algorithm never used race as a variable, yet it produced racially discriminatory outcomes because of a proxy variable embedded in a discriminatory system.
9Module 4 Discussion: Choosing the Right LLM for Business¶
10Module 4 Written Analysis: LLM Business Implementation Plan¶
11Module 4 Reflection: AI Companions and Human Connection¶
12Module 4 Hands-On Activity 1: LLM Comparison Lab in Google AI Studio¶
13Module 4 Hands-On Activity 2: Creating a Business Research Agent with NotebookLM¶
14Chapter Summary¶
This chapter has taken you on a journey from the physical foundations of modern AI — the massive data centers and cloud computing platforms that power everything — through the principles of machine learning to the cutting edge of large language models. You now have a practical framework for understanding and evaluating the AI tools that are reshaping business.
We began with big data and the Five V’s, understanding that the fuel of machine learning is data — vast, fast-moving, varied, and only valuable when processed with the right tools. We explored the physical infrastructure of data centers, appreciating both the engineering marvel they represent and the environmental responsibility they demand.
We deepened our understanding of machine learning through the three paradigms — supervised, unsupervised, and reinforcement learning — each suited to different types of business problems. We then conducted a comprehensive comparison of five leading LLMs — ChatGPT, Claude, Gemini, Perplexity, and Jasper — understanding that there is no single “best” AI. The right tool depends on the task, the context, the budget, and the values of the organization.
We examined the frontier of mobile AI, where LLM capabilities are being democratized through smartphones, and we confronted the critical issues of AI bias, fairness, and the economics of LLM deployment.
Throughout, we maintained our commitment to Christian stewardship — asking not just “Can we use this technology?” but “Should we, and how?” The pursuit of knowledge and the development of powerful tools are godly endeavors. But wisdom, as Proverbs teaches, is not merely the accumulation of knowledge — it is the discernment to use that knowledge rightly. As you move forward in your careers, may you be leaders who harness the power of AI with both competence and conscience.
15Glossary¶
Big Data Datasets so large, complex, and rapidly generated that traditional data processing methods cannot handle them, characterized by the Five V’s: Volume, Velocity, Variety, Veracity, and Value.
Data Center A physical facility housing computing infrastructure — servers, storage, networking, and cooling systems — that stores, processes, and distributes data at scale.
Cloud Computing On-demand access to shared computing resources (servers, storage, databases, AI services) over the internet, provided by platforms like AWS, Azure, and Google Cloud on a pay-as-you-go basis.
Supervised Learning A machine learning approach where algorithms learn from labeled training data — input-output pairs with known correct answers — to make predictions on new data.
Unsupervised Learning A machine learning approach where algorithms discover hidden patterns, clusters, or structures in unlabeled data without being told what to look for.
Reinforcement Learning A machine learning approach where an agent learns optimal decision-making by taking actions in an environment and receiving rewards or penalties based on outcomes.
Large Language Model (LLM) An AI model trained on vast text data using transformer architecture, containing billions of parameters, capable of understanding and generating human language.
Transformer Architecture The neural network architecture underlying modern LLMs, using self-attention mechanisms to process relationships between all words in a sequence simultaneously.
Parameters The numerical weights within a neural network that are adjusted during training. More parameters generally enable the model to capture more complex patterns.
Context Window The maximum amount of text (measured in tokens) that an LLM can process in a single interaction, determining how much information it can consider at once.
Hallucination When an LLM generates information that sounds plausible and confident but is factually incorrect, fabricated, or nonsensical — a fundamental risk of generative AI.
RLHF Reinforcement Learning from Human Feedback — a training technique where human preferences guide model behavior, making LLM responses more helpful, harmless, and honest.
Retrieval-Augmented Generation (RAG) A technique that grounds LLM responses in verified external documents rather than relying solely on training data, reducing hallucinations and improving accuracy.
Token The basic unit of text processing in LLMs — roughly equivalent to three-quarters of a word. LLM pricing and context windows are measured in tokens.
Fine-Tuning The process of further training a pre-trained LLM on a specific dataset to specialize its behavior for a particular domain, task, or style.
GPU Graphics Processing Unit — specialized hardware chips originally designed for rendering graphics, now essential for training and running AI models due to their parallel processing capabilities.
TPU Tensor Processing Unit — custom AI accelerator chips designed by Google specifically for machine learning workloads, offering high performance for model training and inference.
On-Device AI AI processing that runs directly on a user’s device (smartphone, laptop) rather than in the cloud, offering privacy, speed, and offline capability at the cost of model size and power.
Open Source LLM Large language models whose weights and architecture are publicly available (e.g., LLaMA, Mistral), allowing organizations to deploy, customize, and fine-tune them on their own infrastructure.
Algorithmic Bias Systematic and repeatable errors in an AI system that create unfair outcomes, typically arising from biased training data, flawed assumptions, or proxy variables that correlate with protected characteristics.
Having explored the foundations of machine learning and the LLMs powering today’s AI revolution, we turn next to the world of visual intelligence. In Chapter 5: Computer Vision & AI-Generated Content, we will examine how AI sees and creates images — from object detection and medical imaging to the creative frontier of AI-generated art and the ethical questions it raises.