“An individual wolf is a smart, strong, resilient animal. But the true strength of wolves is their ability to work together as a wolfpack. AI is not coming to replace the pack. It is joining the pack — and the wolves who learn to lead it will set the pace for the rest of the industry.”
You made it.
Thirteen chapters. A capstone prototype you built yourself. A corporate skill library that didn’t exist before this course started. A synthetic wolfpack you can actually deploy — not hypothetically, not someday, but on Monday morning when you’re back at your desk.
This final chapter is not a summary. You’ve been summarizing as you go — every Pack Debrief, every BLUF, every lab reflection has done that work. This chapter is something different. It’s the sendoff.
Three things are on the agenda:
First, how to do this responsibly — not as a compliance checkbox, but as an operational discipline that makes you more trusted, more effective, and more defensible to any customer or auditor who walks through the door.
Second, what’s coming — an honest, grounded look at the developments that will reshape your role in the next five years. Not hype. Earned optimism.
Third, how to stay sharp — because the analysts who compound on what they learned here will look like a different species from the ones who don’t, and the difference is 90 minutes a week.
Let’s close this out.
113.1 Responsible AI in a Federal Context¶
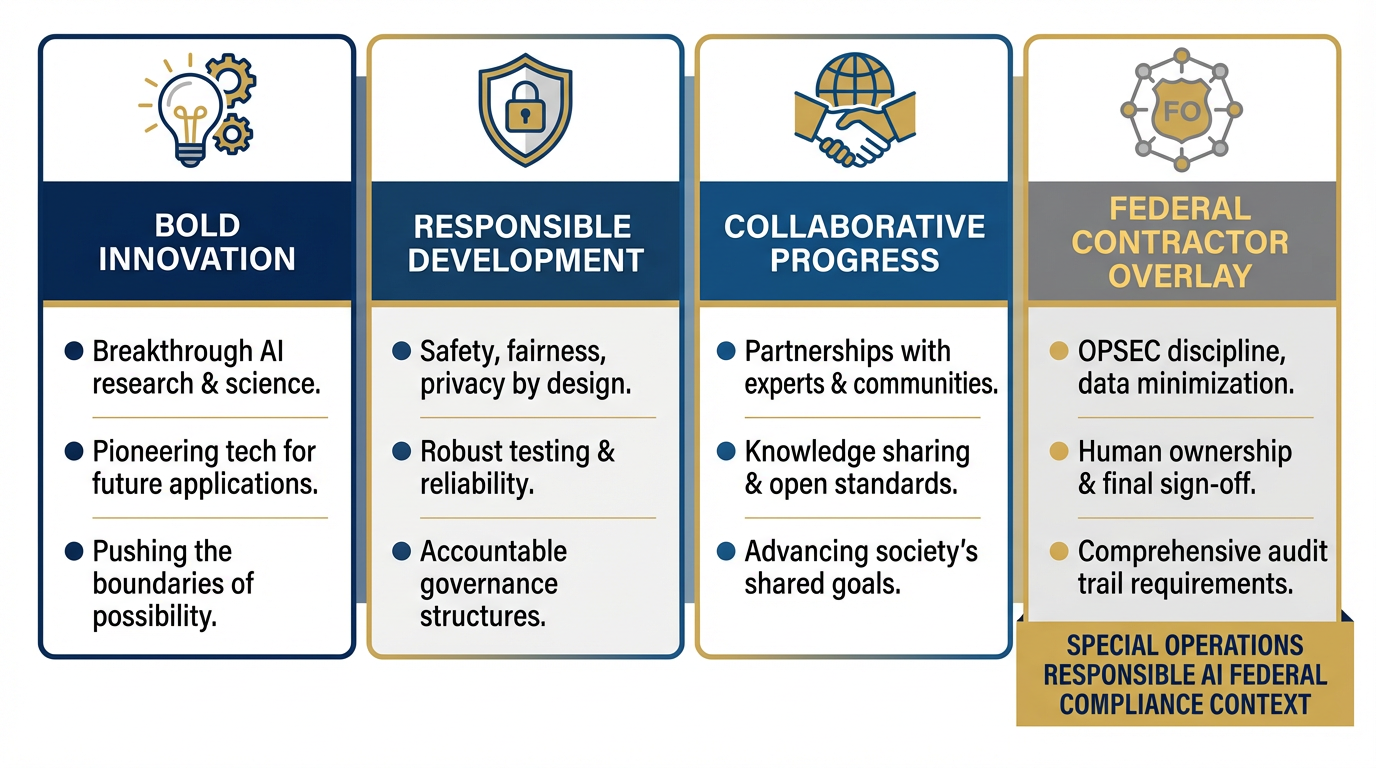
Figure 1:Google’s three AI principles — bold innovation, responsible development and deployment, and collaborative progress — translated into the operational realities of federal contracting. The federal contractor layer adds: OPSEC discipline, human ownership of every deliverable, and audit trail requirements.
Google’s AI framework, published at ai.google/principles, is built on three pillars: bold innovation, responsible development and deployment, and collaborative progress. At the federal contractor level, you keep the first and third — and you operationalize the second in ways that Google, as a commercial product company, doesn’t need to worry about.
The principles that matter most for Lukos work are these, drawn directly from Google’s framework:
Implementing appropriate human oversight, due diligence, and feedback mechanisms — This is not optional at Lukos. Every AI-assisted deliverable has a named human who owns it.
Employing rigorous design, testing, monitoring, and safeguards to mitigate unintended or harmful outcomes and avoid unfair bias — This is your spot-check, document, and audit discipline.
Promoting privacy and security, and respecting intellectual property rights — This is your OPSEC checklist.
The parts of Google’s framework that are less immediately applicable in a federal defense context: the emphasis on enabling “bold innovation” in commercial products at scale. Your job is not to push AI into production for 2 billion users. Your job is to deliver high-quality, defensible analysis and support to DoD and federal customers. That context changes which risks you prioritize.
Bias and Fairness in the Lessons Learned Context¶
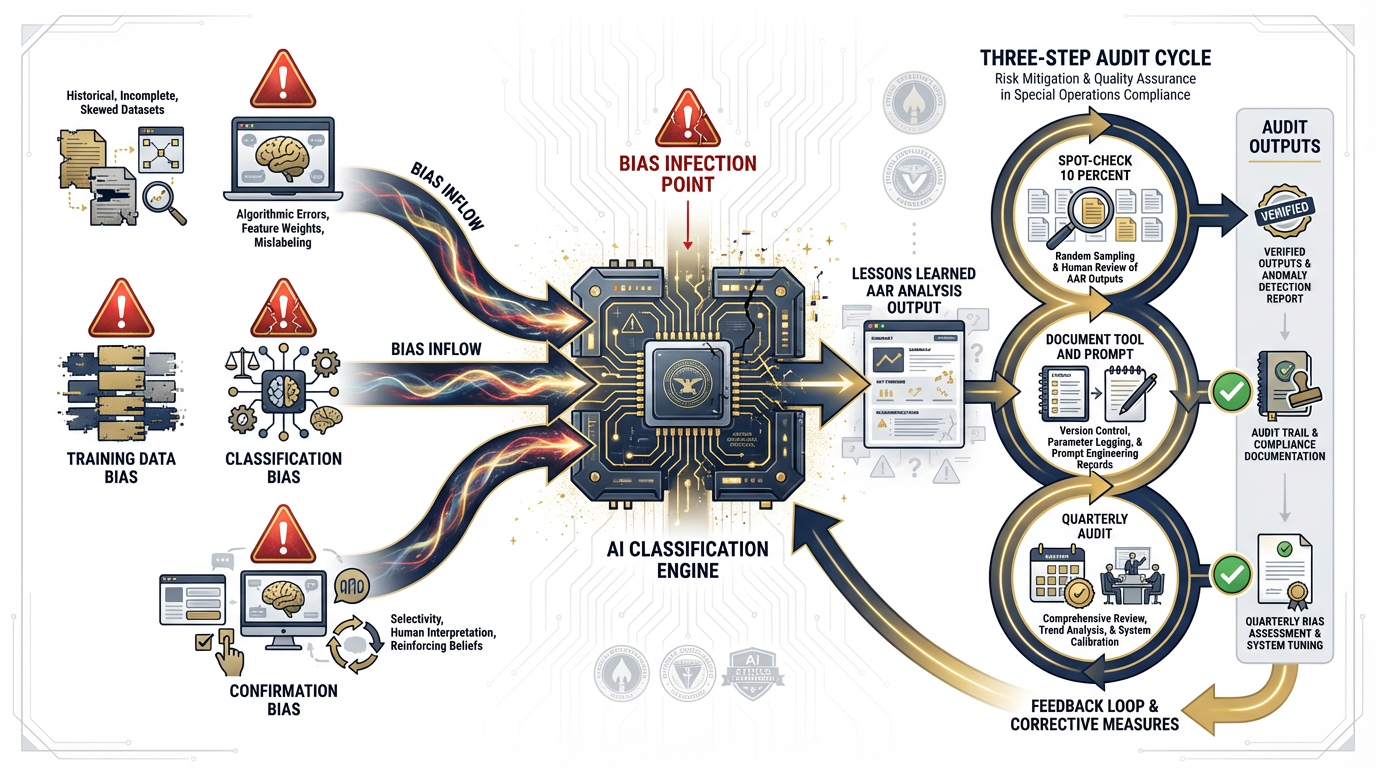
Figure 2:AI bias in AAR analysis enters through three channels: training data bias (models trained on non-military text), classification bias (over-indexing on keyword frequency), and confirmation bias (the model reflects the framing of the prompt). The three-step discipline: spot-check, document, audit.
Here is a scenario worth thinking through carefully.
An analyst uses Gemini to classify 500 After-Action Review observations into thematic categories: logistics, communications, personnel, sustainment, and leadership. The AI returns a clean taxonomy with confidence scores. The analyst submits the product to the customer.
What could go wrong?
Several things. AI models trained primarily on general text corpora may systematically under-classify observations that use military-specific language or abbreviations the model hasn’t encountered frequently. More subtly, the model may over-index on observations that contain certain keywords — “failure,” “shortfall,” “gap” — and cluster them together as a single theme even when they represent distinct operational problems. The resulting taxonomy looks authoritative but may obscure exactly the patterns the customer needs to see.
The discipline to counter this is not complicated. It has three steps:
Step 1 — Spot-check. Before submitting any AI-classified product, pull a random 10% of observations and manually verify the classification. Not every observation — 10%. This is not a burden. This is how you catch systematic errors before they become customer problems.
Step 2 — Document. Record what tool was used, what prompt was used, and what the analyst’s verification protocol was. This documentation is not bureaucratic overhead — it is the answer to the question a customer or auditor will eventually ask: “How do you know this is right?”
Step 3 — Audit. On a quarterly basis, review a sample of AI-assisted products against the original source data. Did the classifications hold up? Were there systematic errors that appeared across multiple products? This is how the practice improves over time.
The “Show Your Work” Discipline¶
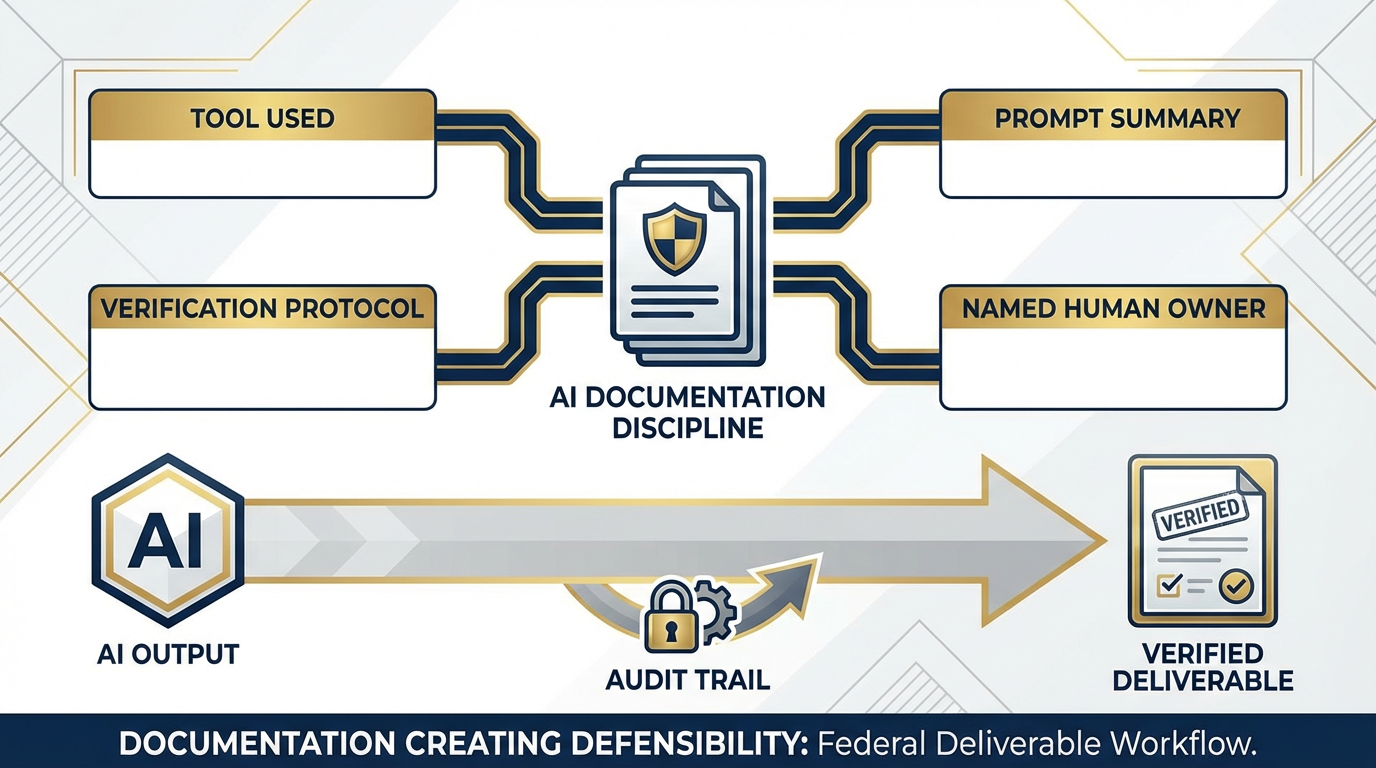
Figure 3:Every AI-assisted deliverable requires four documentation elements: the tool used, the prompt used, the verification protocol, and the named human owner. This is not a burden — it is professional practice, and it is what makes AI adoption defensible to federal customers.
Federal contractors have always been required to explain their work. You cite your sources. You document your methodology. You show the customer how you got from raw data to conclusions. AI doesn’t change this requirement — it adds a layer to it.
If AI contributed to a deliverable, that contribution is documented. Full stop.
This is not a constraint. This is professional practice, and it has a practical advantage: the analyst who documents their AI-assisted workflow is the analyst who can reproduce it, improve it, teach it to a colleague, and defend it to any customer who asks. The analyst who doesn’t is flying blind — and one bad product ends the conversation.
The documentation template is simple:
Tool: Gemini 1.5 Pro via AI Studio / Vertex AI / NotebookLM
Prompt: [summarized version of the prompt used]
Verification: [what spot-check protocol was applied]
Owner: [analyst name, date]
That’s it. Four lines. It takes 90 seconds. It makes everything defensible.
The Lukos-Specific Overlay¶
Lukos is a Service-Disabled Veteran-Owned Small Business. That designation carries weight with DoD customers — it signals a commitment to principled service, not just contract performance. The responsible AI overlay at Lukos is not a constraint on the mission. It IS the mission.
An SDVOSB that deploys AI carelessly — uploading CUI to commercial tools, generating unverified analysis, producing deliverables with no audit trail — is not innovating. It is creating liability. It is eroding the customer trust that wins re-competes.
An SDVOSB that deploys AI responsibly — with verified outputs, documented workflows, appropriate tools for the sensitivity level, and named human ownership — is demonstrating exactly the kind of mature, professional support that DoD customers pay for. Responsible AI is a competitive advantage, not a compliance burden.
213.2 The Master OPSEC and Federal Compliance Checklist¶

Figure 4:The Master OPSEC Checklist: five categories, fifteen checks. Print this. Laminate it. Run every AI workflow through it before the product goes to a customer. This is the document that makes your AI practice defensible.
This checklist is a living document. Update it as new tools are approved or deprecated. Run every AI-assisted workflow through it before the product goes to a customer. It should become muscle memory.
FedRAMP authorization status for all tools can be verified at marketplace
Surface Selection¶
Is this surface FedRAMP authorized for this data sensitivity level? (Verify at marketplace
.fedramp .gov — this is the authoritative list. Authorization status changes. Check before every new use case.) Does this surface have an audit trail? (Can you produce a log of what was submitted and when, if a customer or auditor asks?)
Who has access to this surface and the data on it? (Is it scoped to the right people? Are shared accounts a risk?)
Data Hygiene¶
Has any classified, CUI, or FOUO material been checked BEFORE it enters any AI tool? (This check happens BEFORE you touch the keyboard. Not after. The damage from one upload cannot be undone.)
Is PII present? If yes — does this tool have a BAA or equivalent agreement? (Personally Identifiable Information in a commercial AI tool without a Business Associate Agreement or equivalent is a compliance violation and a liability.)
Are source documents sanitized to the correct level? (If the source is a classified document with a sanitized version, you’re working from the sanitized version. Confirm this explicitly.)
Prompt and Output Security¶
Does the prompt contain any sensitive information that shouldn’t be in a commercial AI tool? (Re-read your prompt before you submit it. Names, unit designations, operational details — these don’t belong in a commercial AI tool unless that tool is appropriately authorized.)
Has the output been verified before it goes to a customer? (The spot-check from 13.1. No exceptions.)
Is the output clearly labeled as AI-assisted? (This is professional practice. The customer deserves to know.)
API Key and Credential Discipline¶
Is every API key stored in a secrets manager — not in code, not in chat, not in a doc? (API keys left in code repos, chat histories, or shared documents are a security incident waiting to happen.)
Are credentials rotated on personnel changes? (When someone leaves the team, rotate every credential they had access to. Every one.)
Are agent profiles (authenticated sessions) treated as credentials? (A saved Gemini Gem or agent configuration with access to sensitive tools is a credential. Manage it accordingly.)
Model and Tool Governance¶
Is the model being used FedRAMP authorized or otherwise approved? (When in doubt: marketplace
.fedramp .gov. If it’s not there and it’s not explicitly approved, it doesn’t touch sensitive work.) Is there a named human who owns every AI-assisted deliverable? (Not “the team.” Not “AI.” A name. A person. If something is wrong with the product, that person is accountable — and empowered to fix it.)
Is there an audit trail for every model run that touches sensitive data? (What tool, what prompt, what output, what date, who verified. Four lines. Every time.)
313.3 The Career Implications¶
Let’s be direct. Not fear-mongering. Not naive optimism. Direct.
AI is not coming to take your job. AI is coming to give you a different job — and the analysts who see that clearly, right now, are positioning for a promotion they don’t realize they’re already competing for.
The Lessons Learned Analyst in Five Years¶
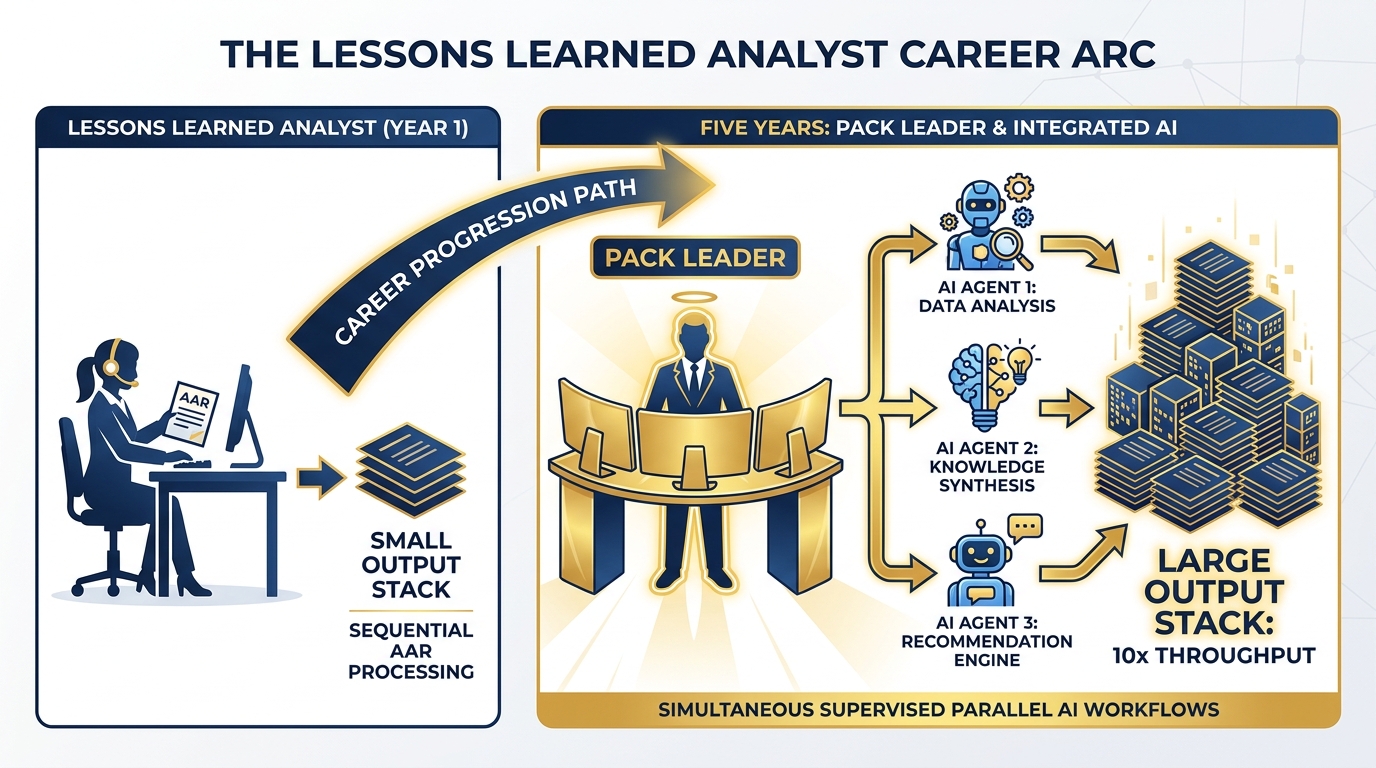
Figure 5:Five-year career arc for the Lessons Learned Analyst: from individual contributor processing AARs sequentially to pack leader supervising 3-4 AI agents running in parallel. Throughput: 10x. Quality: higher. The tool: the synthetic wolfpack built in this course.
The analyst who embraces the synthetic wolfpack becomes a pack leader.
Here’s what that looks like concretely: Instead of working through 500 AAR observations one by one, the pack leader designs and supervises three parallel AI workflows — one classifying by theme, one extracting tactical patterns, one surfacing command-level implications. All three run simultaneously. The analyst reviews, synthesizes, and delivers a product in the time it used to take to do the first workflow alone.
That’s not a prediction. That’s the workflow you built in this course.
The analyst who doesn’t build this gets outcompeted — not by AI, but by the analyst who built it. The job that used to take a team of four takes one pack leader and four synthetic teammates. The customer sees a better product in less time. The re-compete goes to the pack leader.
The ORSA in Five Years¶
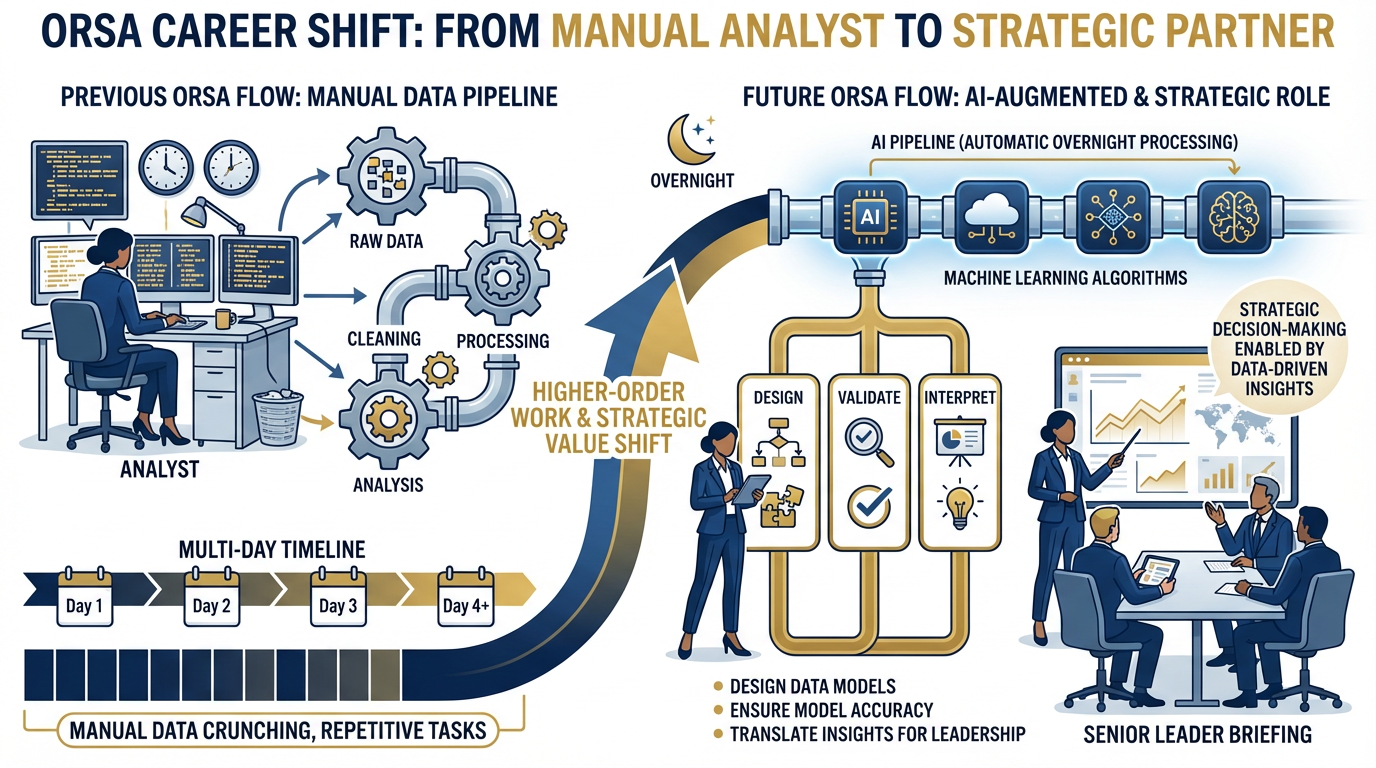
Figure 6:The ORSA’s value shift: from running data analysis pipelines (time-consuming, manual) to designing them, validating them, and interpreting results for senior leaders. The pipeline runs overnight. The ORSA’s morning is spent on the question that actually matters: what does this mean for the commander?
Data analysis pipelines that used to take an ORSA three days run overnight.
The ORSA’s value shifts from running the analysis to designing it, validating it, and interpreting it for senior leaders. These are higher-order skills. They are also the skills that are genuinely difficult to automate — and the ORSA who develops them becomes the person in the room who can translate between the AI’s output and the commander’s question.
The ORSA who doesn’t develop them becomes the person who is very good at a pipeline that runs itself.
The Program Manager in Five Years¶
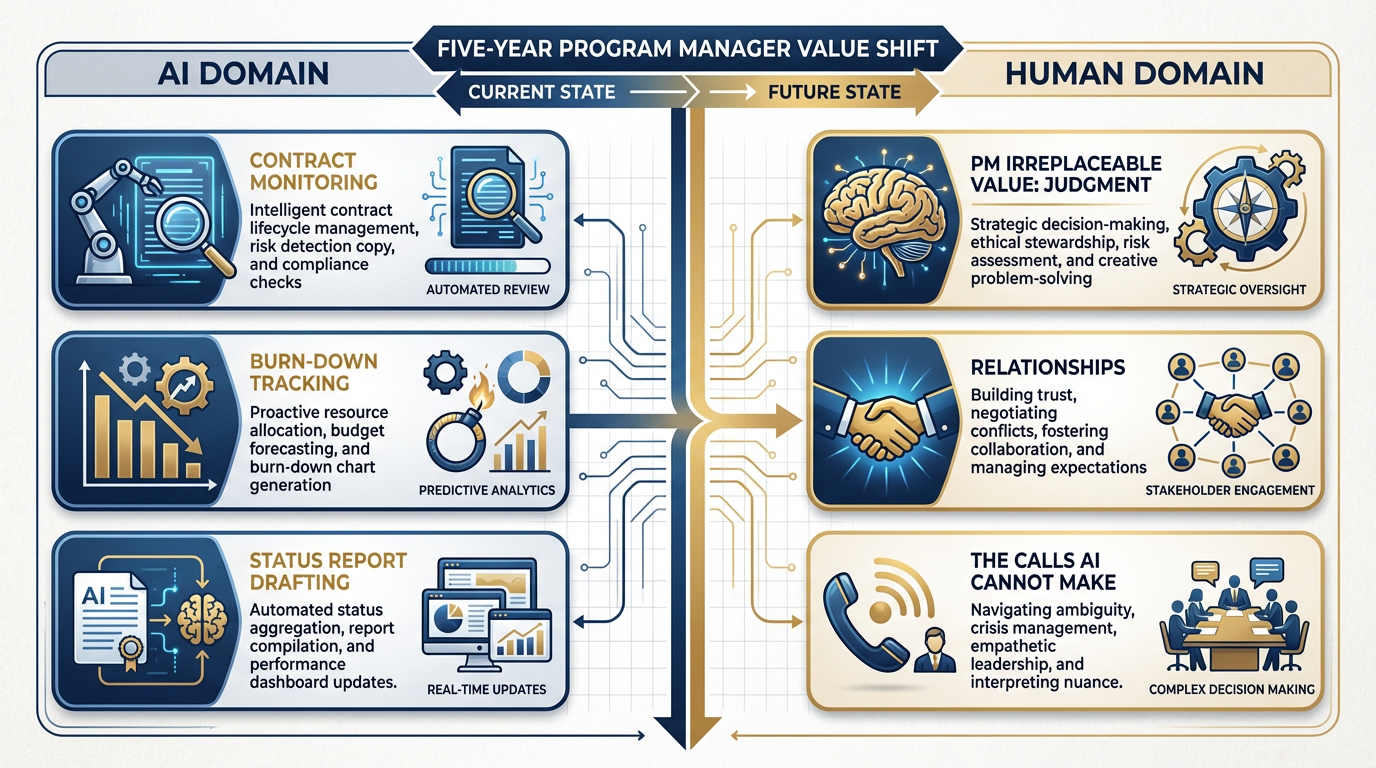
Figure 7:The Program Manager in five years: AI agents monitor contract burn-down, flag anomalies, and draft status reports. The PM’s irreplaceable value is in judgment (what this anomaly actually means), relationships (the call to the customer before the anomaly becomes a problem), and decision-making under ambiguity.
AI agents will monitor contract performance, flag burn-down anomalies, and draft status reports. This is not a distant possibility — the tools to do this exist today.
The PM’s value shifts to the things AI cannot do: judgment, relationships, and the calls AI can’t make. When a burn-down anomaly appears, the AI flags it. The PM knows whether it means the program is in trouble or just passed through a scheduled quiet period. The PM makes the call to the customer before it becomes a problem. The PM reads the room in a meeting that isn’t on anyone’s calendar.
Judgment, relationships, and calibrated decision-making under ambiguity: these are the PM’s durable competitive advantages. Build them intentionally.
The Site Lead in Five Years¶
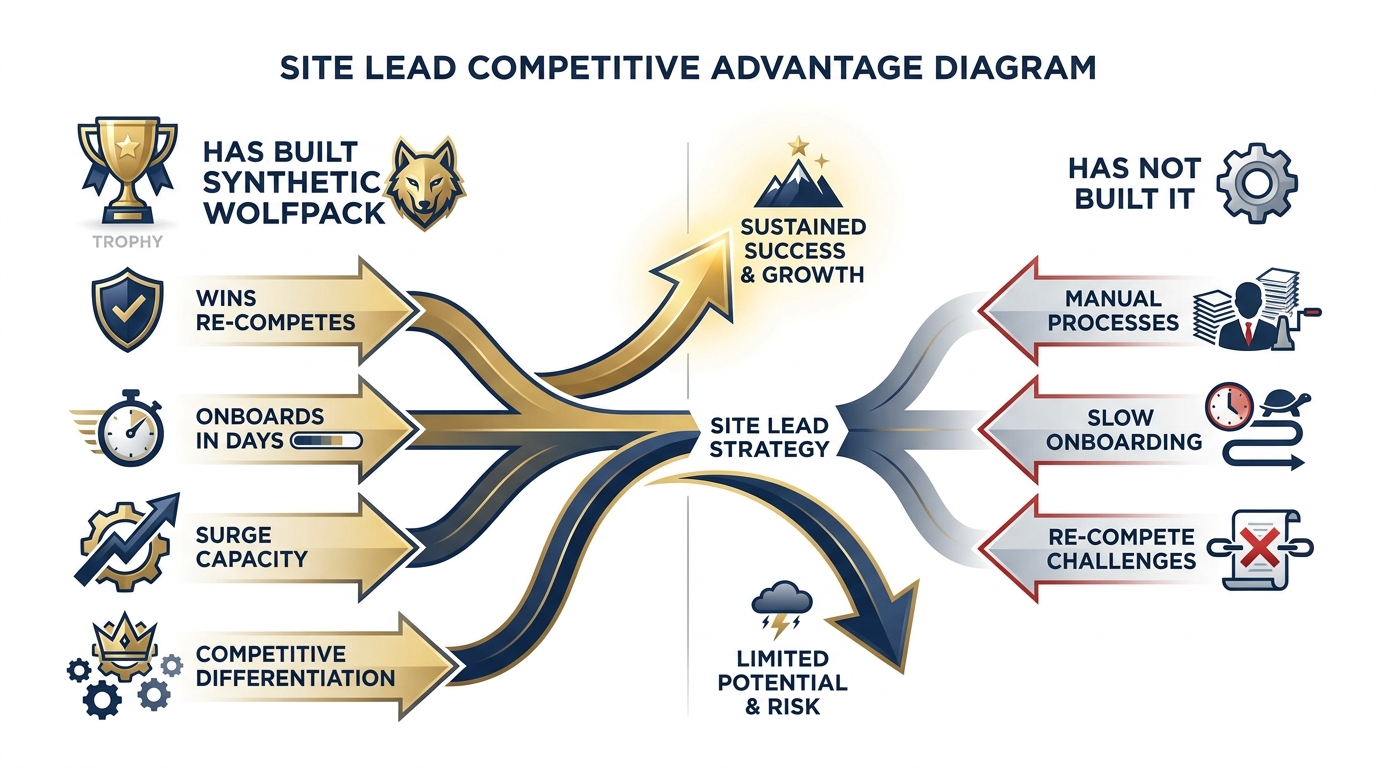
Figure 8:The site lead who has built a corporate skill library and a synthetic wolfpack is running a fundamentally different operation. They win re-competes. They onboard new analysts in days instead of weeks. They produce more, at higher quality, with the same headcount. The site lead who hasn’t built this is explaining to the customer why it’s still manual.
The site lead who has built a corporate skill library and a synthetic wolfpack is running a fundamentally different operation from the one who hasn’t.
They onboard a new analyst in days instead of weeks — because the skills exist, documented, tested, and deployable. They respond to surge requirements with capacity rather than chaos. They produce more, at higher quality, with the same headcount. When the re-compete comes, they have a story to tell that the incumbent without these capabilities cannot match.
The site lead who hasn’t built this explains to the customer why they’re still doing it manually. That is a conversation that ends contracts.
The Honest Statement¶
“Supervisor of synthetic teammates” is not a science fiction premise. It is a job description that exists today at Lukos — if you build what this book teaches.
The analysts who build it will lead it. The analysts who don’t will work for the ones who did.
That’s not a threat. It’s a career map. And you’re holding the directions.
413.4 Continuous Learning — The Lukos Cadence¶
The analysts who compound on this course will look like a different species in 18 months. The ones who don’t will remember the course fondly and wonder why their colleagues keep getting tapped for the interesting work.
The difference is 90 minutes a week. Here is the cadence.
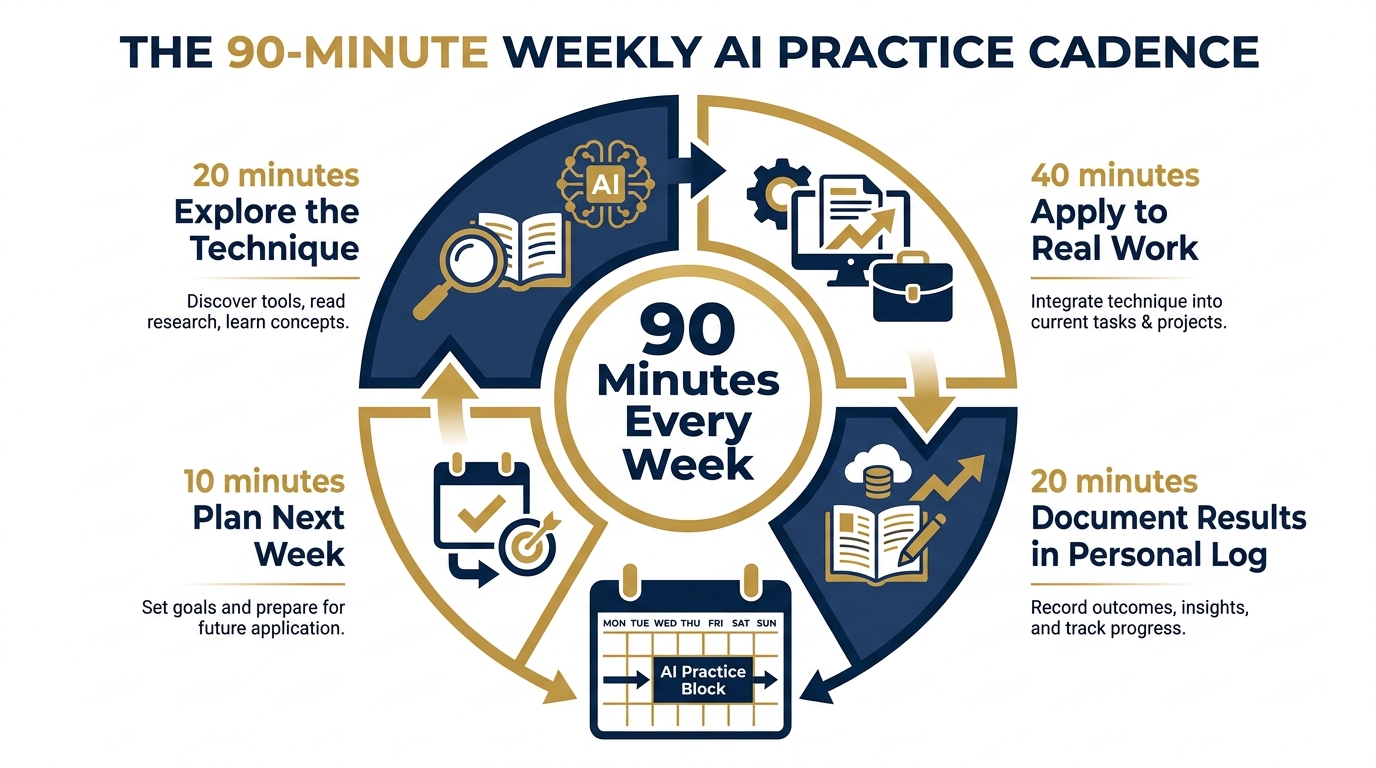
Figure 9:The weekly cadence: 90 minutes, one new technique, a personal log entry. Not a training session — a deliberate practice. The structure: 20 minutes exploring the technique, 40 minutes applying it to real work, 20 minutes documenting what worked and what didn’t, and 10 minutes planning next week’s technique.
The Weekly 90-Minute Practice¶
Pick one technique you haven’t fully deployed. Spend 90 minutes on it. Apply it to something real — not a practice exercise, a real work product. Write one paragraph in your personal log: what you tried, what worked, what you’ll do differently next time.
Do this every week. Without exception. The analysts who do this compound. The analysts who don’t plateau. The gap between them widens every week, and after 18 months it is very hard to close.
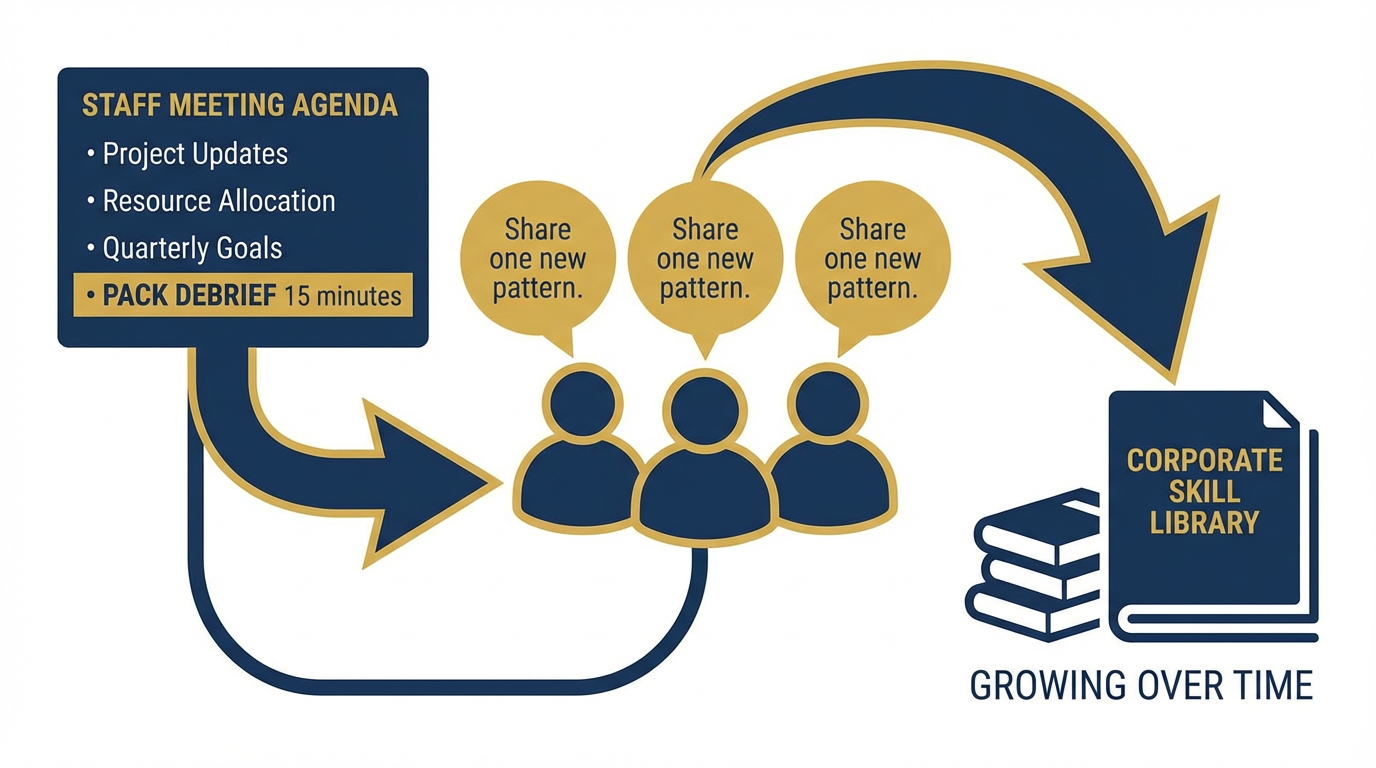
Figure 10:The monthly pack debrief: 15 minutes at the end of a staff meeting. Every team member shares one new AI pattern they’ve adopted. No slides required. Just: what did you try, did it work, and can someone else use it? This is how the pack learns together.
The Monthly Pack Debrief¶
At the end of every staff meeting — 15 minutes, no slides required — every team member shares one new pattern they’ve adopted. Not a presentation. One thing. “I tried X for Y and it cut my time by half.” That’s the format.
This is how the pack learns together. It’s also how the corporate skill library grows — because when someone shares a pattern, someone else writes it into a Gem and contributes it.
The Quarterly Skill Audit¶
Every quarter, the site lead reviews the corporate skill library. Three questions:
What’s stale? (Tools deprecated, workflows no longer matching how work gets done)
What’s missing? (Patterns people are using informally that haven’t been captured)
Who contributed? (Recognition matters — the analysts who contribute to the library are the ones building the institutional capability)
This audit takes 90 minutes. It prevents the library from becoming a graveyard of outdated Gems.
The Annual Stack Review¶
The model lineup will change. Every year — as you do the comparison exercise from Chapter 1 on arena.ai — re-run your decision matrix. Which model is the best all-rounder for your work? Which has the best cost-performance for high-volume tasks? Which has the best document handling for the AAR corpus?
The models will be different. The process for evaluating them won’t. That process is the durable skill.
drlee.io and drlee.ai¶
Dr. Lee maintains ongoing essays, courses, and cohort programs at drlee.io and drlee.ai. These are the resources for what comes after this book — the techniques that emerge in the months after publication, the new tools that weren’t in the course, the community of Lukos analysts who are building together.
Subscribe. Participate. Contribute.
513.5 The Industries Lukos Will Touch in the Next Decade¶

Figure 11:Lukos’s AI adoption curve creates an expansion arc: DoD and USSOCOM (today) → DHS/HHS federal civilian (2026-2028) → Commercial enterprise (2027-2030) → International partner-nation engagement (2028+). The lessons-learned methodology — 45,000+ observations — becomes a transferable asset across every sector.
Lukos built its reputation on one core competency: converting operational experience into actionable knowledge. Forty-five thousand lessons learned. The methodology that turns AARs into institutional memory. That competency doesn’t expire. It expands.
DoD and USSOCOM¶
The next five years at USSOCOM will see AI move from pilot programs to embedded operational practice. The component commands — JSOC, NAVSPECWARCOM, MARSOC, AFSOC, USASOC — are at different points on the adoption curve. The organizations that have already built the internal capability to deploy AI responsibly and at scale will be the ones positioned for the contract vehicles that follow.
Lukos, having built that capability internally, is positioned to be the organization that brings it to customer sites — not just as a product, but as a practice. The synthetic wolfpack isn’t just a Lukos efficiency gain. It’s a deliverable.
DHS and HHS: The Federal Civilian Opportunity¶
The same AI maturity curve that DoD is navigating is playing out, on a slight delay, across the federal civilian agencies. DHS — with its border operations, threat analysis, and incident response workloads — has direct parallels to the analytical challenges Lukos has solved for USSOCOM.
HHS — with its vast volume of program data, grant performance monitoring, and policy analysis requirements — is sitting on a lessons-learned problem that would be immediately recognizable to any Lukos analyst. The terminology is different. The methodology transfers.
Commercial Enterprise¶
The lessons-learned methodology Lukos has refined over decades in the DoD environment is directly applicable to enterprise customers with a different vocabulary for the same problems: after-action reviews become retrospectives, command-level implications become executive insights, and the 45,000-observation corpus becomes a corporate knowledge base.
The analysts who complete this course understand how to structure, analyze, and synthesize institutional knowledge at scale. That is a skill set with a very large addressable market outside of DoD.
International Partner-Nation Engagement¶
AI scales what was previously impossible at the team level. For partner-nation engagement — where the task has always been transferring methodology, not just delivering products — AI enables a fundamentally different model. A small team of Lukos analysts, with a well-designed synthetic wolfpack, can support partner-nation capability development at a scale that would have required a much larger team five years ago.
The constraint was always bandwidth. AI doesn’t remove the need for expert analysts — it multiplies their reach.
613.6 What to Watch¶
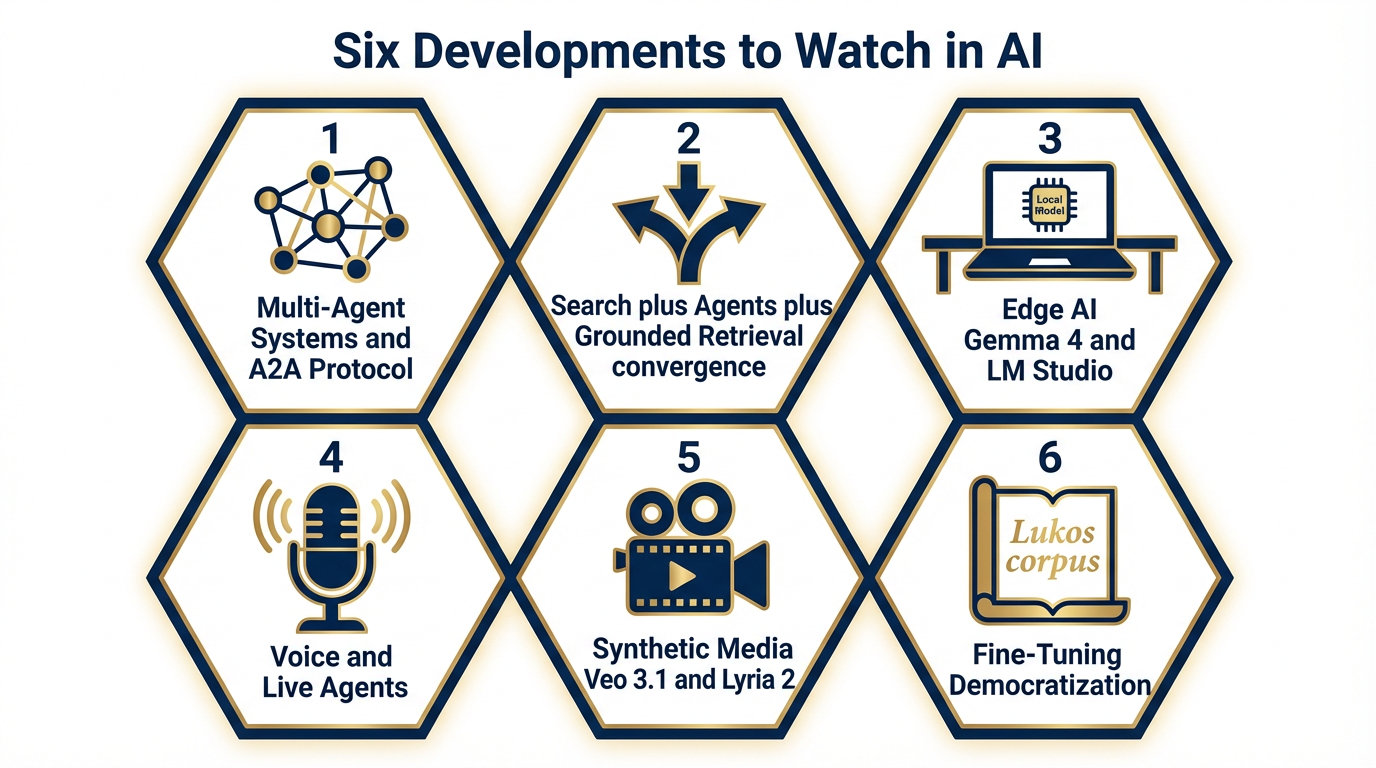
Figure 12:Six developments to track: (1) Multi-agent systems and the A2A protocol, (2) Convergence of search, agents, and grounded retrieval, (3) Edge AI — Gemma 4 and LM Studio, (4) Voice and live agents, (5) Synthetic media — Veo 3.1, Lyria 2, Nano Banana Pro, (6) Fine-tuning democratization.
The model lineup changes faster than this book can track. Here are six structural developments to watch — not specific model versions, but directions of travel that will shape your work for years.
Multi-Agent Systems and the A2A Protocol¶
The Agent-to-Agent (A2A) protocol is an emerging open standard that allows AI agents from different platforms to communicate, coordinate, and hand off tasks. This is the technical foundation for the next generation of the synthetic wolfpack — not just Gemini agents talking to each other, but agents from different ecosystems operating in coordinated pipelines.
Watch this closely. The Vertex AI Agent Builder already supports multi-agent orchestration. The A2A protocol, as it matures, will remove the platform lock-in that currently constrains what multi-agent systems can do. When Gemini agents, Claude agents, and specialized domain agents can talk to each other, the synthetic wolfpack becomes a synthetic joint force.
The Convergence of Search, Agents, and Grounded Retrieval¶
What happens when FireCrawl, NotebookLM, and the Live grounding API are one integrated surface? You get an agent that doesn’t just retrieve documents — it understands them, cross-references them, and generates analysis grounded in real-time verified sources.
This convergence is already visible in the latest Vertex AI release notes: RAG Cross Corpus Retrieval (available April 2026) allows retrieval from multiple knowledge corpora simultaneously. The metadata search capability for RAG Engine allows schema-based filtering during retrieval. These are not incremental improvements — they are the components of a grounded analysis pipeline that would have been a major research project two years ago.
Edge AI: Gemma 4 as a First-Class Deployment Target¶
Gemma 4, released April 2026 under the Apache 2.0 license, is not a fallback for environments without connectivity. It is a first-class deployment target. Gemma 4 models are multimodal — handling both text and image input — and available in the Vertex AI Model Garden.
The significance for federal work: Gemma 4 can run in environments where commercial cloud AI is not authorized. For analysts working in disconnected or low-connectivity environments, LM Studio plus a locally-hosted Gemma 4 model is a genuine operational capability, not a workaround.
The Apache 2.0 license means organizations can deploy, fine-tune, and redistribute Gemma 4 without the licensing constraints that apply to proprietary models. For Lukos — and for federal organizations exploring on-premise AI deployment — this is a significant development.
Voice and Live Agents: The Real-Time AI Tutor¶
The Live model family enables real-time, voice-native AI interaction. The training delivery implication is significant: a tabletop exercise where an AI participates as a role-player, responds to analyst questions in real time, and provides after-action feedback within the exercise itself.
This is not a speculation. The technical capability exists in the current Gemini API. The application to professional military education and contractor training is an obvious next step.
Synthetic Media: Veo 3.1, Lyria 2, and Nano Banana Pro¶
Veo 3.1 Lite, available on Vertex AI in public preview as of April 2026, is the most cost-efficient video generation model in the Veo family. Lyria 2 generates high-quality audio. Nano Banana Pro generates images.
Together, these tools enable AI-generated training content at a scale that was previously cost-prohibitive: video briefings with narration, visual aids generated from text descriptions, audio summaries of lengthy reports. For Lukos training deliverables — and for the training content produced alongside this book — these are production-grade tools, not experiments.
Fine-Tuning Democratization: The Lukos-Specific Model¶
Here is the long game.
Lukos has 45,000+ lessons learned in its corpus. That corpus — properly structured, sanitized, and formatted — is a fine-tuning dataset for a Lukos-specific model. A model trained on 45,000 lessons learned from USSOCOM operations would generate analysis that reflects institutional memory in ways that a general-purpose model cannot.
The infrastructure for this exists today in Vertex AI. The technical barriers to fine-tuning are lower than they have ever been. The question is not whether this is possible — it’s when Lukos decides it is a priority.
The analysts who understand the mechanics of fine-tuning (covered in Chapter 11) are the analysts who will lead this project when it launches.
713.7 The Closing Word¶

The pack goes forward. Every analyst who completes this course carries the kit: the prompting discipline, the agent architecture, the OPSEC checklist, the continuous learning cadence. The pack compounds. The mission continues.
You built something in this course.
Not just a prototype. Not just a Gem library. You built a practice — a discipline of working with AI that is responsible, verifiable, and powerful. You built habits that compound. You built a mental model of what the synthetic wolfpack actually looks like when it’s deployed on real work, not theoretical exercises.
The book is over. The work begins.
Every analyst now has the kit, the patterns, and the discipline. You have the OPSEC checklist, laminated or printed, ready to run against every new tool and every new workflow. You have the weekly 90-minute practice, the monthly pack debrief, the quarterly skill audit. You have a clear-eyed view of what your role looks like in five years — and what it takes to lead rather than follow that transition.
What you do with it over the next 24 months is what Lukos’s next decade looks like.
The model lineup will change. The principles won’t. Context engineering, persona, grounding, supervision, governance — these outlast every specific model. The pack that internalizes these principles will adapt to whatever comes next. The pack that only learned tool-specific tricks will have to start over every time the tools change.
Be the pack that learned the principles.
“An individual wolf is a smart, strong, resilient animal. But the true strength of wolves is their ability to work together as a wolfpack. AI is not coming to replace the pack. It is joining the pack — and the wolves who learn to lead it will set the pace for the rest of the industry.”
The book is over. The work begins.
Every analyst now has the kit, the patterns, and the discipline. What you do with it over the next 24 months is what Lukos’s next decade looks like.
The pack is waiting. Let’s move.
8Three-Tier Hands-On Labs¶
Group Lab: The 30-Day Commitment¶
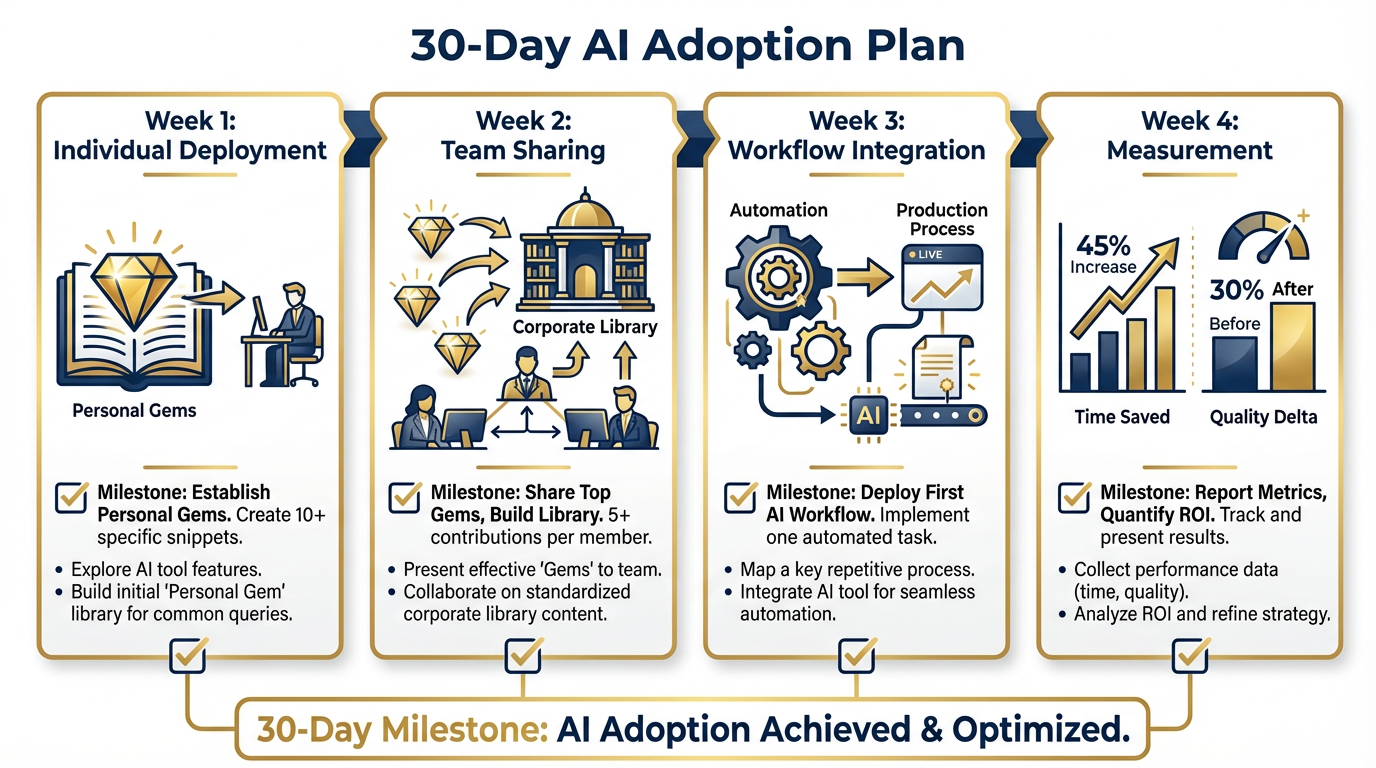
Figure 14:The 30-day adoption plan: Week 1 — individual deployment (Gemini Gems, personal skill library). Week 2 — team sharing (contribute one skill to corporate library). Week 3 — workflow integration (one automated workflow in production). Week 4 — measurement (document time saved, quality delta, customer feedback).
This is not a planning exercise. This is a commitment exercise. The difference is a signature.
Tier 1 — The On-Ramp (5 min)
Every person writes down: one AI tool they will deploy at work within 5 business days of returning from this course. One sentence. Tool name, specific use case, expected outcome. Sign it. Hand it to your site lead.
Not “I might try.” Not “I’ll look into.” A specific tool. A specific use case. A date: within five business days.
✅ Success looks like: A signed 5-day commitment from every participant in the room. The site lead collects them. In five business days, they follow up.
Tier 2 — The Core Rep (20 min)
In small groups of 3-4, build a 30-day AI adoption plan for your site:
| Week | Focus | Milestone |
|---|---|---|
| Week 1 | Individual deployment | Each analyst has a personal Gem library active; one Gem used on a real deliverable |
| Week 2 | Team sharing | Each analyst contributes one skill to the corporate library; one Gem shared with the team |
| Week 3 | Workflow integration | One automated workflow (not a one-off — a repeatable process) running in production |
| Week 4 | Measurement | Document: time saved, quality delta (customer feedback or peer review), one lesson learned |
Present the plan to the room. Dr. Lee and Professor Marquez give feedback.
✅ Success looks like: A 30-day adoption plan specific to your Lukos site, reviewed by the instructors, with named owners for each milestone.
Tier 3 — The Wow Moment (25 min)
Run your current AI workflow through the Master OPSEC Checklist from Section 13.2. Every checklist item. For every unchecked box: write one sentence of remediation.
This is not a gotcha exercise. Every workflow will have gaps. The point is to surface them before a customer or auditor does.
✅ Success looks like: A completed OPSEC checklist for your personal AI workflow, with remediations documented for every gap. This artifact goes home with you. It is the document that makes your AI practice defensible.
Individual Lab: Your Personal AI Development Plan¶
This lab is about the next 90 days, not the next 13 chapters.
Tier 1 (5 min)
Identify three skills you want to develop in the next 90 days:
One from Chapters 2-4 (everyday tools — Gemini, NotebookLM, AI Studio prompting)
One from Chapters 6-8 (agents and skills — Gems, Vertex AI agents, the corporate skill library)
One from Chapters 9-11 (advanced capabilities — multi-agent systems, fine-tuning, Veo, RAG)
Write them down. Be specific: not “get better at prompting” — “master multi-shot prompting for AAR classification” is specific.
Tier 2 (15 min)
Build your 90-day learning plan. For each of the three skills:
Resource: Where will you learn it? (drlee.io, Vertex AI documentation, a specific chapter exercise, a cohort program)
Exercise: What specific exercise will you complete?
Milestone: How will you know you’ve achieved it? What deliverable will exist?
Tier 3 (25 min)
Write a one-page AI Maturity Statement for your role at Lukos:
Current state: Where are you today? (Use the AI Readiness Gap Assessment from the Prologue as your baseline)
90-day target: Where will you be? What will you be able to do that you can’t do today?
Customer value: What deliverable will you be able to produce for a customer that you couldn’t produce before this course — and how will it be better, faster, or more defensible?
✅ Success looks like: A personal AI Maturity Statement, signed and dated. You’ll revisit it in 90 days to measure your progress. Put it somewhere you’ll actually see it.
9Field Notes¶
10Pack Debrief¶
Chapter 13 of “AI for Lukos Professionals — The Wolfpack’s Edge” Dr. Ernesto Lee and Professor Carlos Marquez | Miami Dade College © 2026 — All rights reserved