Chapter 8: The Synthetic Wolfpack
Multi-Agent Orchestration — Building the AI Team That Works While You Sleep
1Chapter 8: The Synthetic Wolfpack — Multi-Agent Orchestration¶
“A lone wolf can take down a rabbit. A wolfpack takes down an elk. The question isn’t whether your AI can do a task. It’s whether your AI team can execute a mission.”
You’ve spent the last seven chapters building individual capabilities.
You learned how to prompt with precision. You gave the model memory with NotebookLM. You built Gems with specific personas. You gave your agents tools — FireCrawl for live web access, Office Viewer for document ingestion. You authored your first Skills: reusable specialist knowledge that turns a general-purpose model into a domain expert.
Now we do something different.
Now we build the team.
8.1 The Mental Model: Synthetic Employees¶
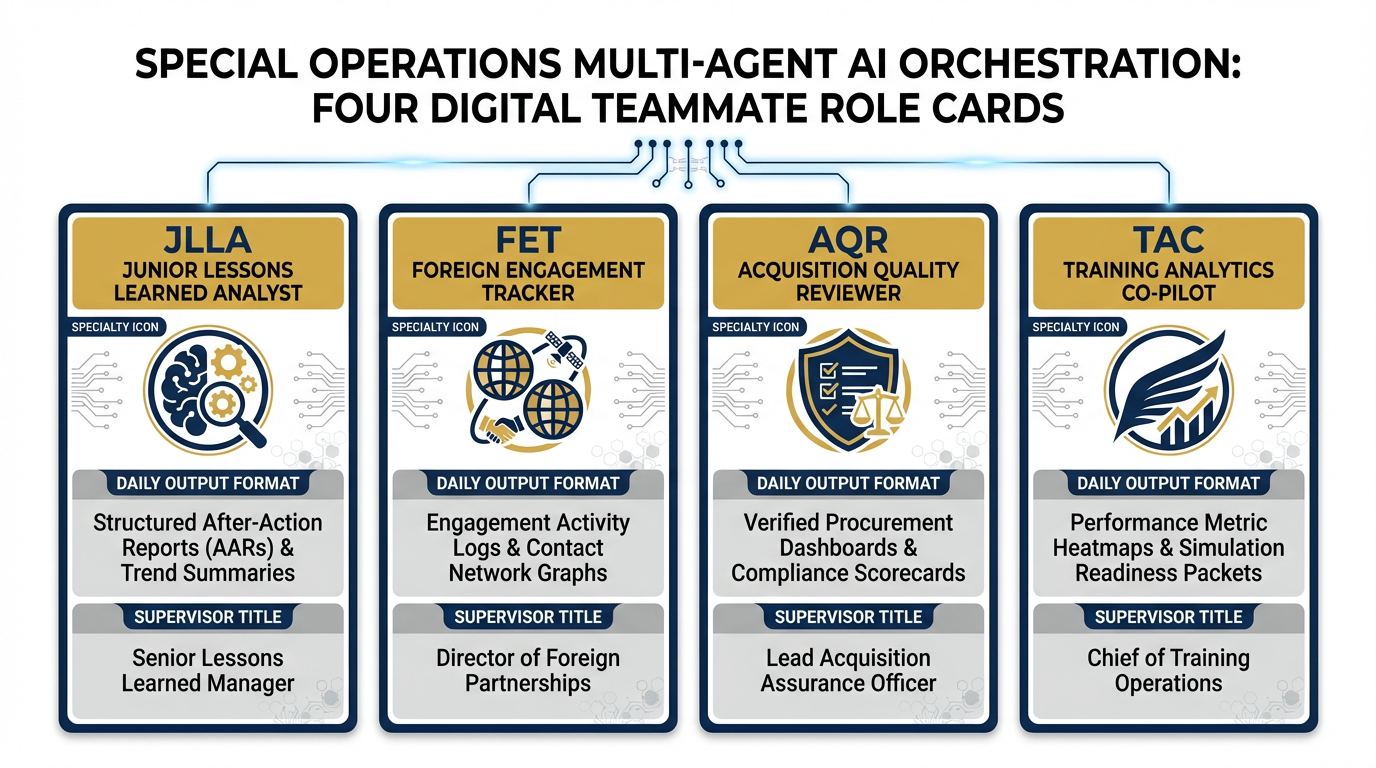
Figure 1:The Synthetic Wolfpack. Four digital teammates, each with a defined role, a specialist skill, a daily output, and a named human supervisor. This is not automation — it is augmentation with accountability.
Here is the frame shift that defines this entire chapter.
For the first six chapters of this book, we talked about AI as a tool — something you pick up, use for a task, and set down. The AI equivalent of a calculator. Enormously useful. But fundamentally reactive. It does what you ask. It waits until you ask again.
That frame is about to break.
We are not talking about AI tools that help an employee do their job faster. We are talking about AI agents that are employees. Digital teammates with defined roles, defined scope of authority, defined escalation rules, and a named human supervisor. Teammates who show up every morning, process their assigned inputs, produce their assigned outputs, flag what they cannot handle, and clock out — without you having to manage every step.
The 30-year shift looks like this. In 1995, a Lessons Learned analyst wrote every report. By 2015, they had templates and databases, but still read every document. In 2025, they have AI tools that accelerate the reading. By 2028, they have a team of four synthetic analysts doing the first-pass reading overnight while they sleep — and they arrive in the morning to review, edit, and approve finished work.
That is not science fiction. That is Antigravity’s Agent Manager, today.
The Special Forces Analogy¶
Think about how a Special Forces ODA is structured.
The 18A team leader doesn’t do everything. They command a team of specialists: an 18B weapons sergeant, an 18C engineer sergeant, an 18D medical sergeant, an 18E communications sergeant. Each has a primary specialty. Each knows their lane. Each can operate independently when the tactical situation demands it. But each reports to the team leader. Each escalates decisions that exceed their authority. Each operates within the team’s concept of operations, not outside it.
The synthetic wolfpack works the same way.
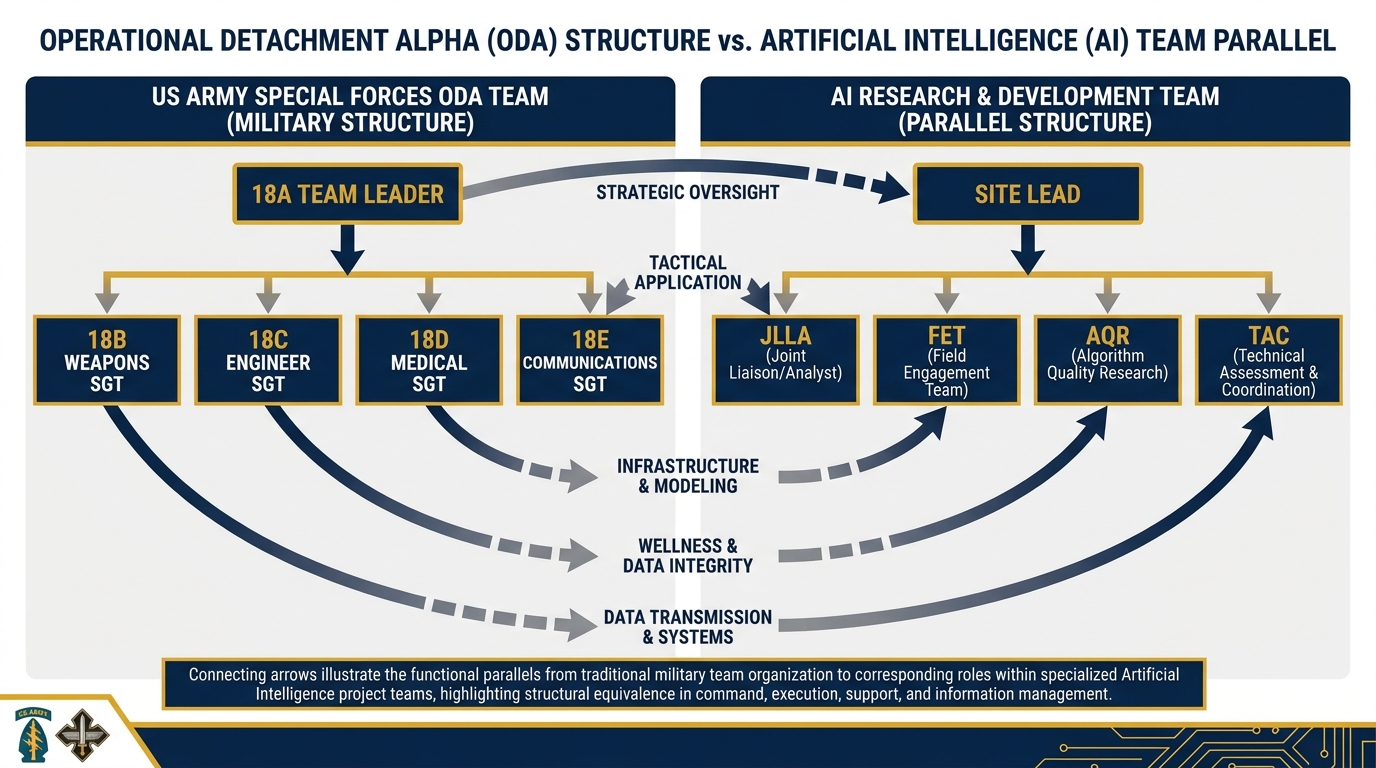
Figure 2:The SF Team Analogy. The 18A leads; specialists execute within their lanes. The synthetic wolfpack mirrors this: the Site Lead supervises; each synthetic teammate handles their assigned workstream, escalates what they can’t handle, and never steps outside their scope of authority.
The 18A doesn’t hand the medical kit to the communications sergeant. The JLLA doesn’t write the acquisition review. Each agent has a specialty. Each knows their lane. Each escalates to the human team leader when they hit the edge of their authority.
That principle — specialist roles, clear escalation, human supervision — is what makes this deployable in a federal contracting environment. And it’s what makes the difference between an AI experiment and a durable operational capability.
8.2 The Four Lukos Synthetic Teammates¶
Over the course of this book, we’ve built four Skills designed for the Lukos Lessons Learned mission. Each Skill is the intellectual core of a synthetic teammate. Together, they constitute the Lukos wolfpack.
Here they are.
JLLA — Junior Lessons Learned Analyst¶
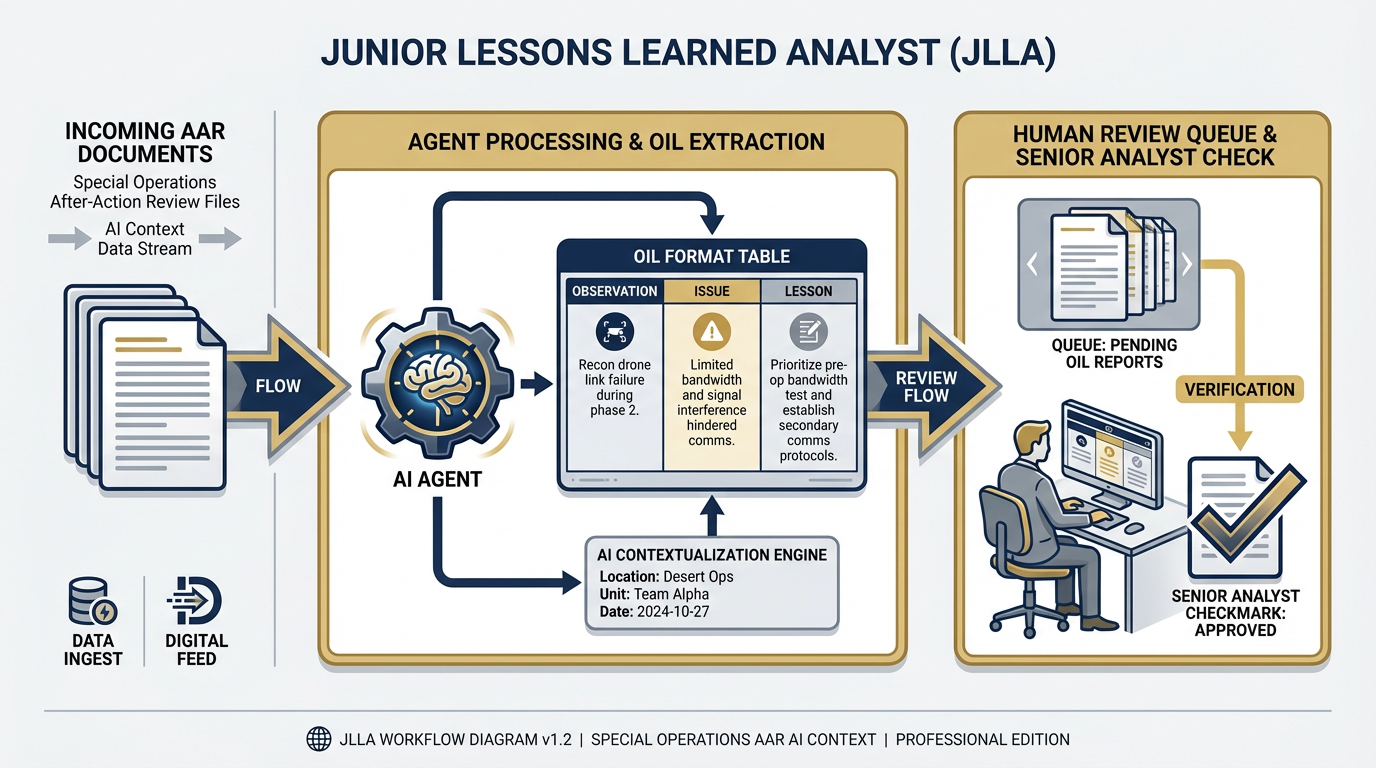
Figure 3:JLLA — Junior Lessons Learned Analyst. Every incoming AAR passes through JLLA first. The agent reads the document, extracts observations, issues, and lessons in OIL format, and queues the structured output for senior analyst review. No AAR enters the pipeline unread; no human reads an unextracted document.
Role: First-pass reader on every incoming AAR.
Skill: lessons-learned-extraction (Chapter 7)
Daily output: For every AAR received during the duty day, JLLA produces a structured OIL table containing: Observation (what happened), Issue (what it reveals), and Lesson (what should change). Output is formatted for immediate ingestion into JLLIS or presentation to a senior analyst.
Escalates: Ambiguous entries where the lesson cannot be clearly determined. Documents that appear to be below the appropriate classification threshold. Any content that references ongoing operations or sensitive programs by name.
Supervisor: Site Lead or Senior Lessons Learned Analyst
What JLLA does not do: JLLA does not make classification determinations. JLLA does not edit or revise its extractions based on program politics or relationships. JLLA does not send its output anywhere without a human review step in the workflow.
The JLLA is the wolfpack’s point of entry. Every AAR, every day. Consistent, tireless, and — when properly supervised — accurate enough to replace the first two hours of every analyst’s morning.
FET — Foreign Engagement Tracker¶
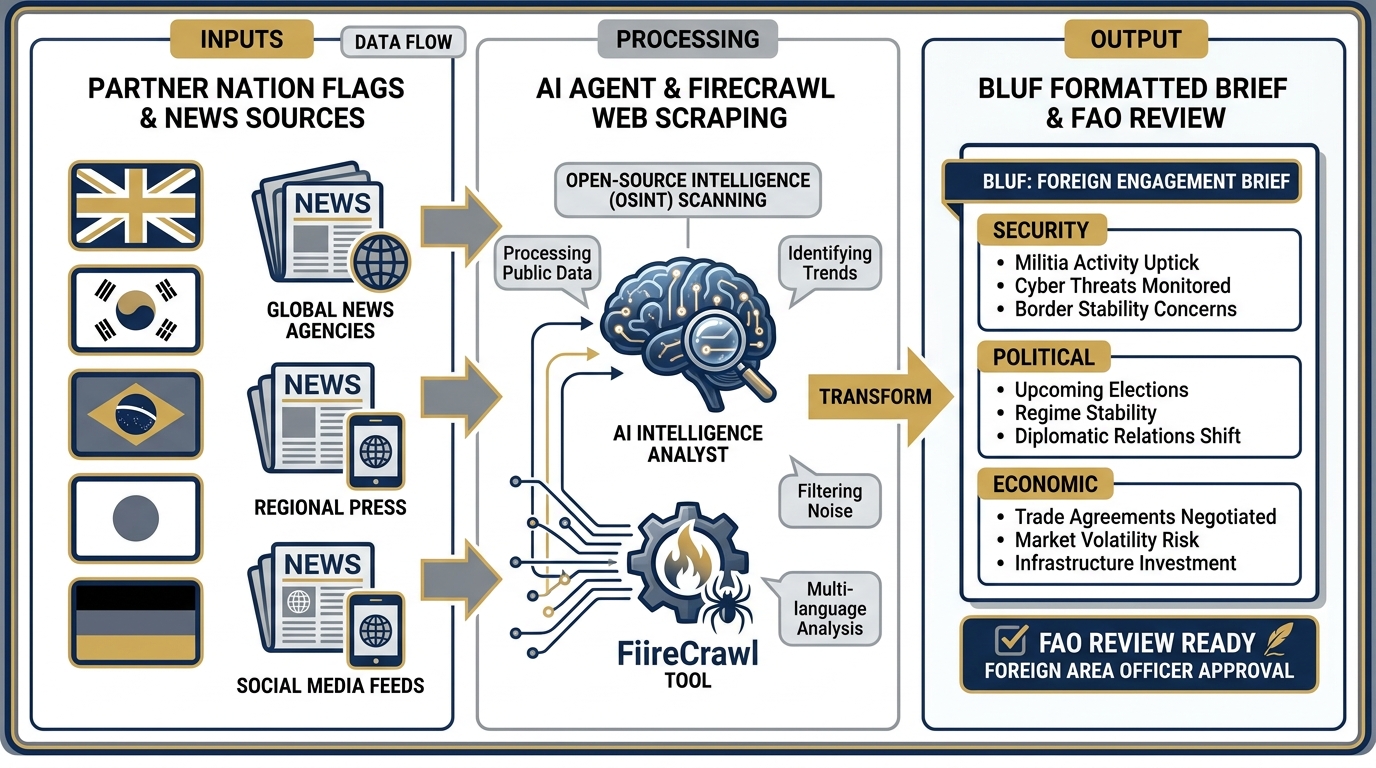
Figure 4:FET — Foreign Engagement Tracker. Assigned partner nations are monitored continuously. Every morning, FET synthesizes open-source reporting on security, political, and economic developments into a BLUF-formatted brief — ready for Foreign Area Officer review before the first meeting of the day.
Role: Daily open-source monitoring of assigned partner nations.
Skills: partner-nation-briefer (Chapter 7) + FireCrawl (Chapter 6)
Daily output: For each assigned partner nation, FET produces a BLUF-formatted brief covering: (1) Security — significant incidents, escalations, or changes to the threat environment; (2) Political — leadership developments, policy shifts, elections, or statements relevant to engagement; (3) Economic — sanctions activity, trade developments, or fiscal changes that affect the partnership.
Escalates: Any development that appears operationally significant. Source reliability concerns — if a source that appears credible publishes something that contradicts all other reporting, FET flags it rather than resolving the contradiction autonomously. Any topic involving classified programs by name.
Supervisor: Foreign Area Officer or Senior Analyst
What FET does not do: FET does not assess source reliability independently. FET does not draw conclusions about partner nation intent or capability without flagging them as analytical judgments for human review.
The FET runs on FireCrawl — the live web access tool from Chapter 6 — giving it real-time access to open-source reporting across dozens of sources simultaneously. The Foreign Area Officer used to spend 90 minutes every morning doing this manually. FET does it overnight.
AQR — Acquisition Quality Reviewer¶
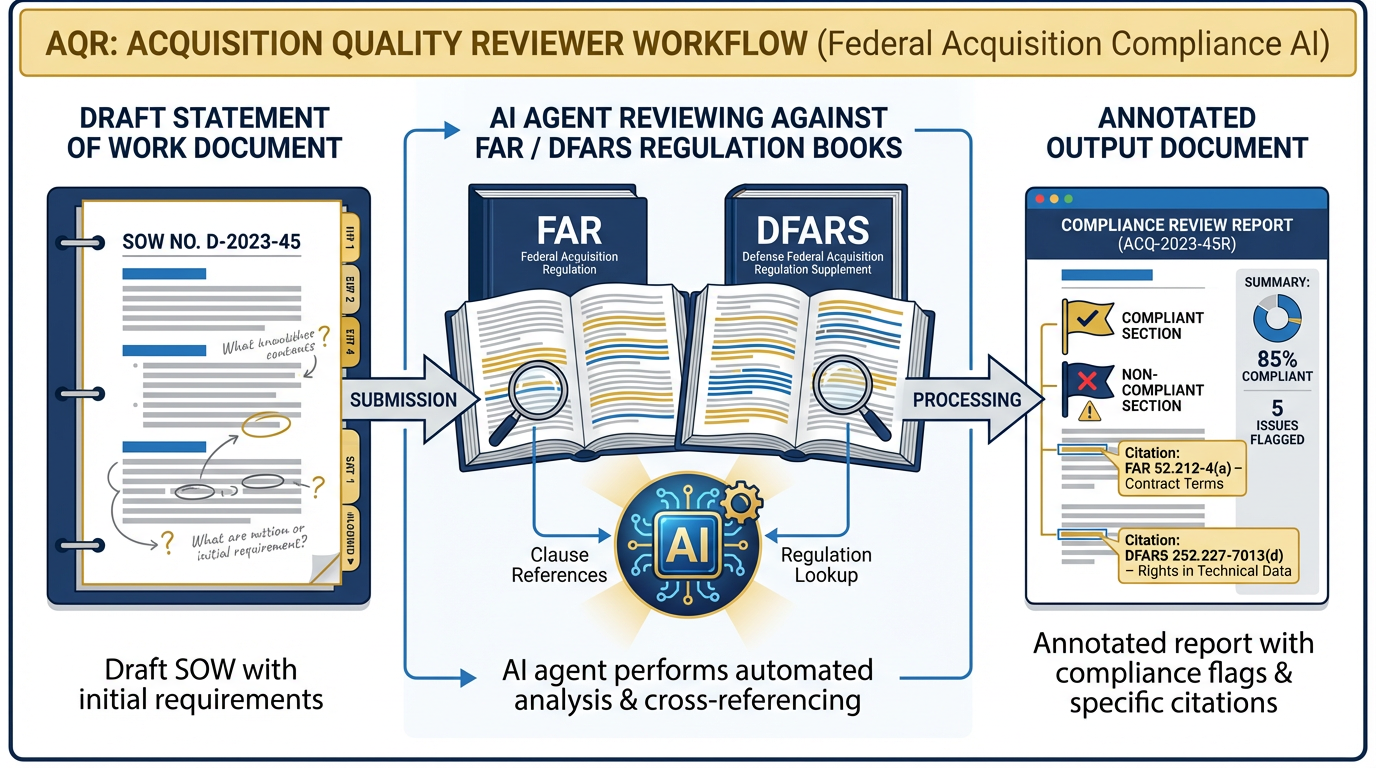
Figure 5:AQR — Acquisition Quality Reviewer. Every draft SOW or PWS passes through AQR for a first-pass compliance review against FAR and DFARS. The agent produces an annotated document with specific clause references — giving the Contracting Officer Representative a structured starting point, not a blank screen.
Role: Red-team reviewer for draft Statements of Work and Performance Work Statements.
Skill: far-clause-explainer (Chapter 7)
Daily output: For each draft SOW or PWS submitted for review, AQR produces an annotated document that: identifies clauses that may require specific FAR/DFARS compliance language, flags provisions that appear to create ambiguity about deliverables or acceptance criteria, and references the specific FAR/DFARS sections relevant to each flag.
Escalates: Any potential compliance issue that could create legal exposure. Novel acquisition vehicles or contract structures not covered by the standard FAR/DFARS framework. Any provision involving intellectual property, data rights, or cybersecurity requirements.
Supervisor: Acquisition Officer or Contracting Officer Representative
What AQR does not do: AQR does not provide legal advice. AQR does not make final compliance determinations. AQR is a structured first-pass review, not a legal opinion.
The Acquisition Officer used to spend four hours reviewing every draft SOW before it went to legal. AQR cuts that to a one-hour review of AQR’s annotated output. The attorney reviews what matters; the routine flags are already resolved.
TAC — Training Analytics Co-Pilot¶
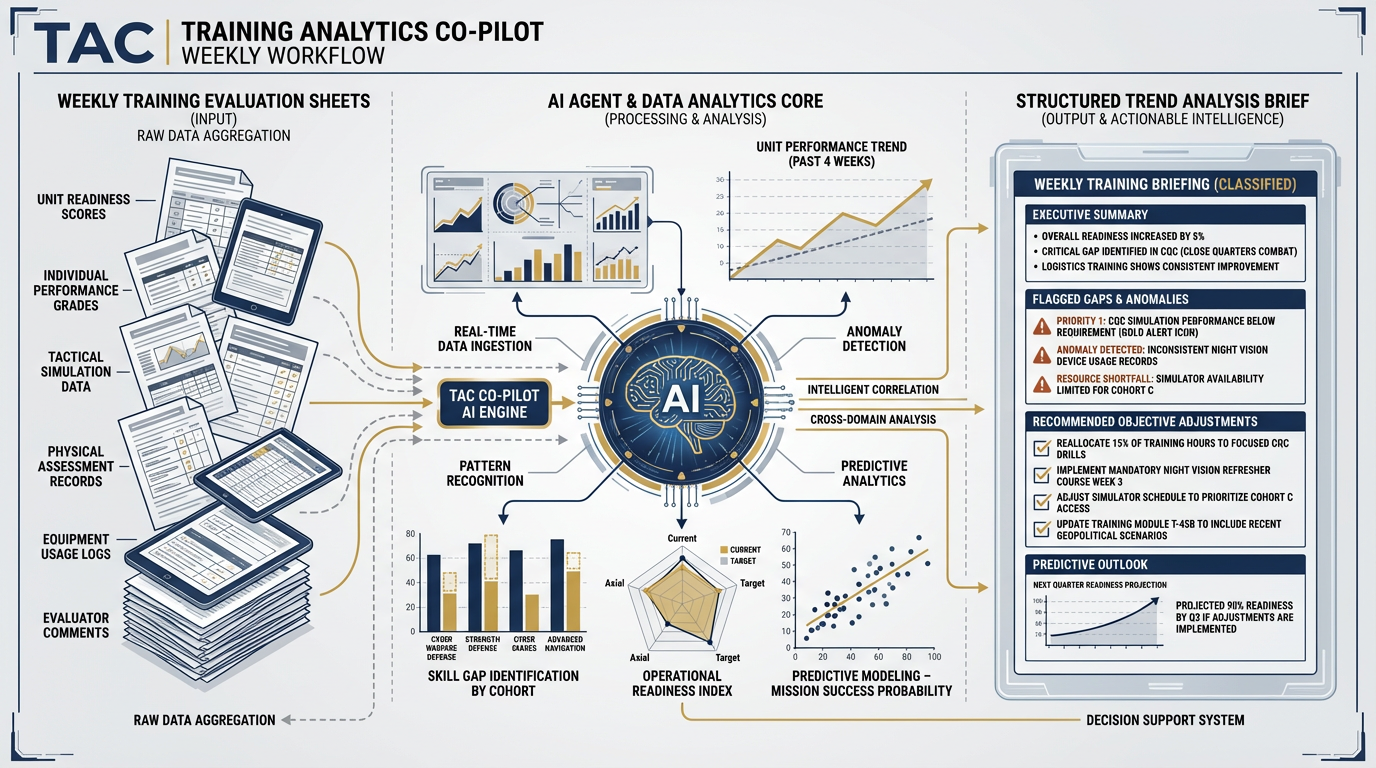
Figure 6:TAC — Training Analytics Co-Pilot. Weekly training evaluation data flows into TAC, which aggregates observations across units and events, identifies trend signals and performance gaps, and produces recommended objective adjustments — ready for Training Developer review before the weekly training planning meeting.
Role: Weekly aggregation of training evaluation data into trend signals and recommendations.
Skill: training-objective-mapper (Chapter 7)
Daily/weekly output: TAC aggregates training observations submitted during the week across all units and exercises, identifies recurring performance gaps against training objectives, and produces a structured trend brief with: (1) flagged objective areas showing consistent degradation; (2) units showing performance concern patterns; (3) recommended adjustments to training objective weighting for the next cycle.
Escalates: Systemic gaps that appear to require curriculum redesign rather than objective adjustment. Unit-level performance concerns that may indicate leadership or resource issues beyond the training program’s scope.
Supervisor: Training Developer or Site Lead
What TAC does not do: TAC does not make personnel assessments or recommendations about individual performance. TAC does not redesign curriculum autonomously — it flags and recommends, then escalates.
The Training Developer used to spend Friday afternoons aggregating a week of observation sheets by hand. TAC does it Thursday night. Friday morning is for decisions, not data entry.
8.3 The Supervision Discipline — Non-Negotiable¶
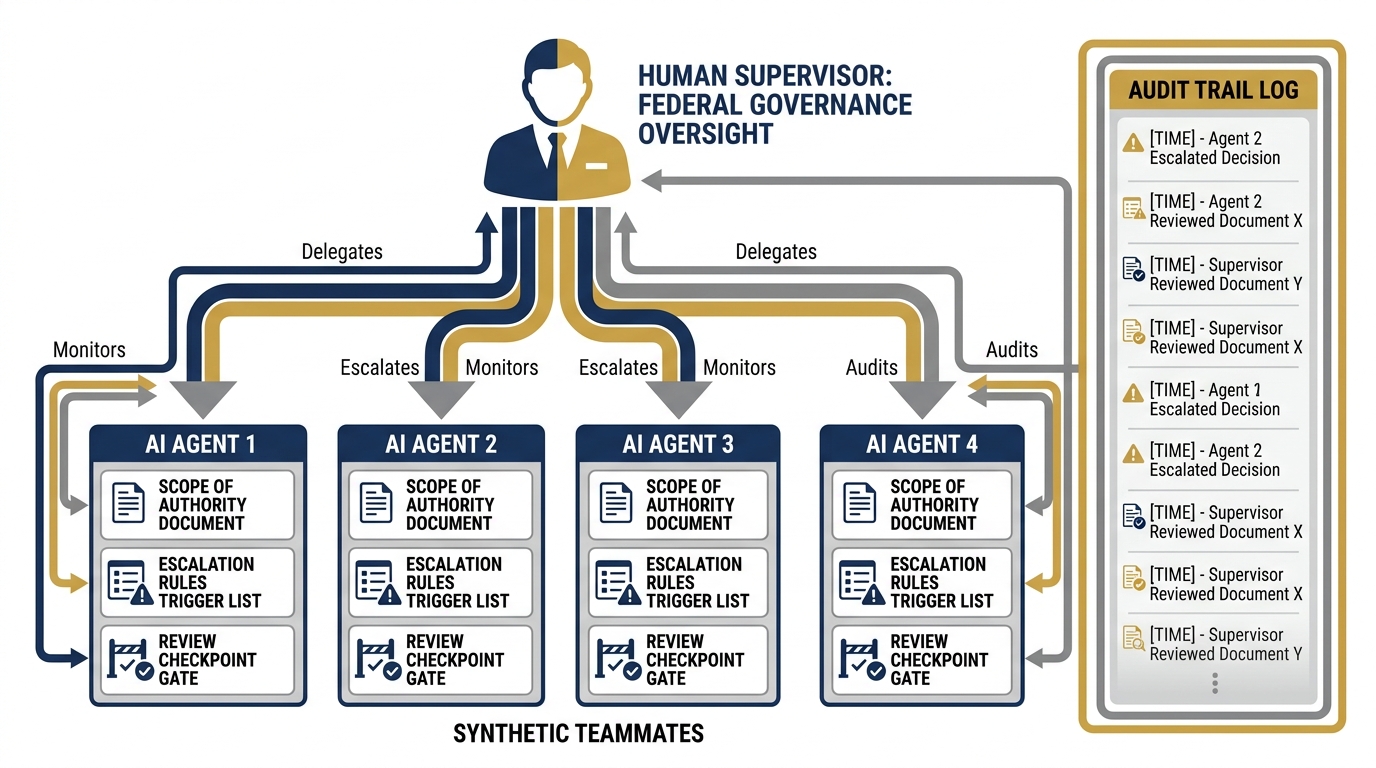
Figure 7:The Supervision Discipline. Every synthetic teammate gets a written job description, a defined scope of authority, explicit escalation rules, and a named human supervisor — before deployment. This is not bureaucracy. It is what separates a deployable AI capability from an AI experiment that eventually causes a problem.
We need to spend real time here. Because this is the section that makes or breaks the deployment.
You are a federal contractor. Your customer pays for human expertise. There is no version of the Lukos contract — or any federal contract — where the customer agrees to have AI make the decisions. They are paying for your team’s judgment. AI augments that judgment. AI does not replace it.
That means the supervision discipline is not optional. It is the price of admission.
Every Synthetic Employee Gets a Job Description¶
Before any synthetic teammate is deployed, it gets a one-page document that specifies:
What it can do autonomously. JLLA can read any unclassified AAR and produce an OIL extraction without asking. That is within its scope of authority.
What it cannot do. JLLA cannot send its output to JLLIS. It cannot make classification determinations. It cannot decide whether an observation is too sensitive to document. Those decisions belong to a human.
What triggers escalation. Any document that references an ongoing operation by name. Any ambiguous entry where the lesson is not clear. Any content that the agent flags internally as requiring senior review.
Who the supervisor is. Not “the team.” One specific named human. The Site Lead. The Foreign Area Officer. The Contracting Officer Representative. One person, by name, who reviews the output and signs off.
This document — the scope of authority — is what you hand to your program manager when they ask “how does the AI work?” It is also what you hand to your government customer when they ask “who is responsible for this output?” The answer is always the named human supervisor.
The Trust-But-Verify Protocol¶
Every synthetic teammate output gets a human spot-check before it goes anywhere.
When you first deploy a synthetic teammate, spot-check 100% of outputs. Manually compare the agent’s work against your own assessment on a sample of inputs. Build confidence in the gap between what the agent produces and what you would have produced.
As the agent proves reliable — and it will, if the Skill is well-built — you can reduce the spot-check percentage. But never to zero. In a federal contracting environment, “never to zero” is not a philosophical position. It is a contractual one. Your customer is paying for human review. That review must happen.
The Audit Trail¶
Every agent action is logged. Every output is versioned. Every human review is documented.
In Antigravity’s Agent Manager, your agent actions are recorded in the session log. That log is your audit trail. In a GFE environment or a classified network, that logging requirement may need to be replicated manually — but the discipline is the same.
If someone asks in six months, “who reviewed this JLLIS entry before it was submitted?” — you should be able to answer with a name, a date, and a version number. Not “the AI processed it.” A human reviewed it. Here is the record.
This is what makes your synthetic wolfpack deployable in a federal context. Not the technology. The accountability architecture around the technology.
8.4 Single Agent → Orchestrator → Multi-Agent System¶
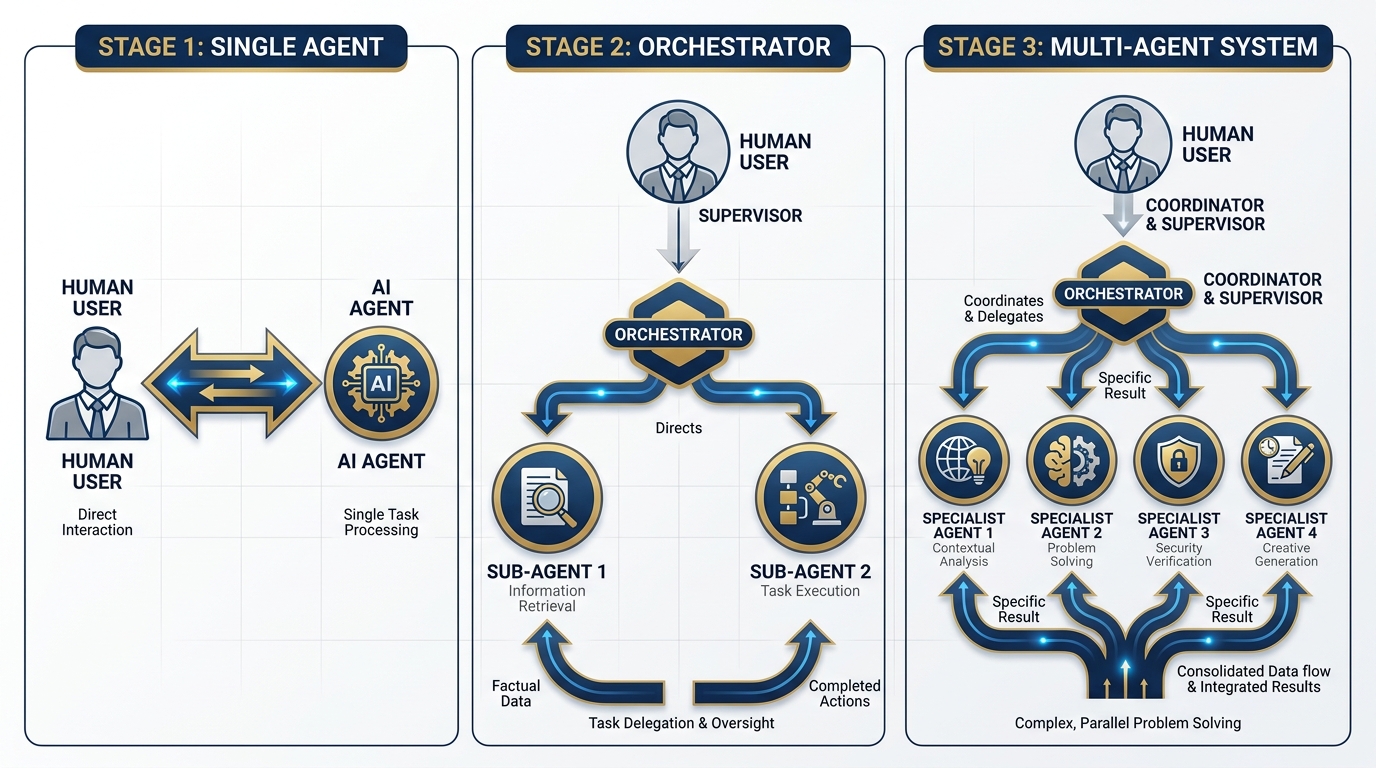
Figure 8:The Architecture Progression. From single-agent interactions (Chapters 2–6) to orchestrated multi-agent pipelines (Chapter 8). Each step adds coordination capability and force multiplication — but also adds supervision complexity that must be managed.
Let’s walk through the architecture progression, because the jump from “one agent” to “four agents working in parallel” is not a single step. It’s three.
Stage 1: Single Agent¶
This is everything you built in Chapters 2 through 6.
You have a task. You open Antigravity, open a workspace, load a Skill if you have one, and run the agent. The agent does the work. You review the output. You approve, edit, or reject.
One agent. One task. One human. Sequential.
This is powerful. It’s also the equivalent of having one analyst and assigning every task to that analyst personally. At some point, you need a team.
Stage 2: The Orchestrator Agent¶
Here is where the jump happens.
An orchestrator agent receives a mission — not a task, a mission. It reads the mission, breaks it into component tasks, dispatches those tasks to sub-agents, collects their outputs, and synthesizes a final product for human review.
Think of the orchestrator as your senior analyst. They receive the mission from you, break it down, brief the team, collect results at the end of the day, and present you with a finished product to review and approve.
The sub-agents are the team. They each get one piece of the mission, execute it in their lane, and return their output to the orchestrator.
You supervise the orchestrator. The orchestrator coordinates the sub-agents. The sub-agents produce specialized outputs. The chain of command is intact.
Stage 3: The Multi-Agent System¶
The full multi-agent system is multiple specialists working in parallel on different workstreams, coordinated by the orchestrator, with the human supervising the orchestrator’s output.
This is the wolfpack.
Four agents running simultaneously. JLLA reading AARs. FET monitoring partner nations. AQR reviewing acquisition documents. TAC aggregating training data. All overnight. All producing structured outputs that land in a human review queue at 0600.
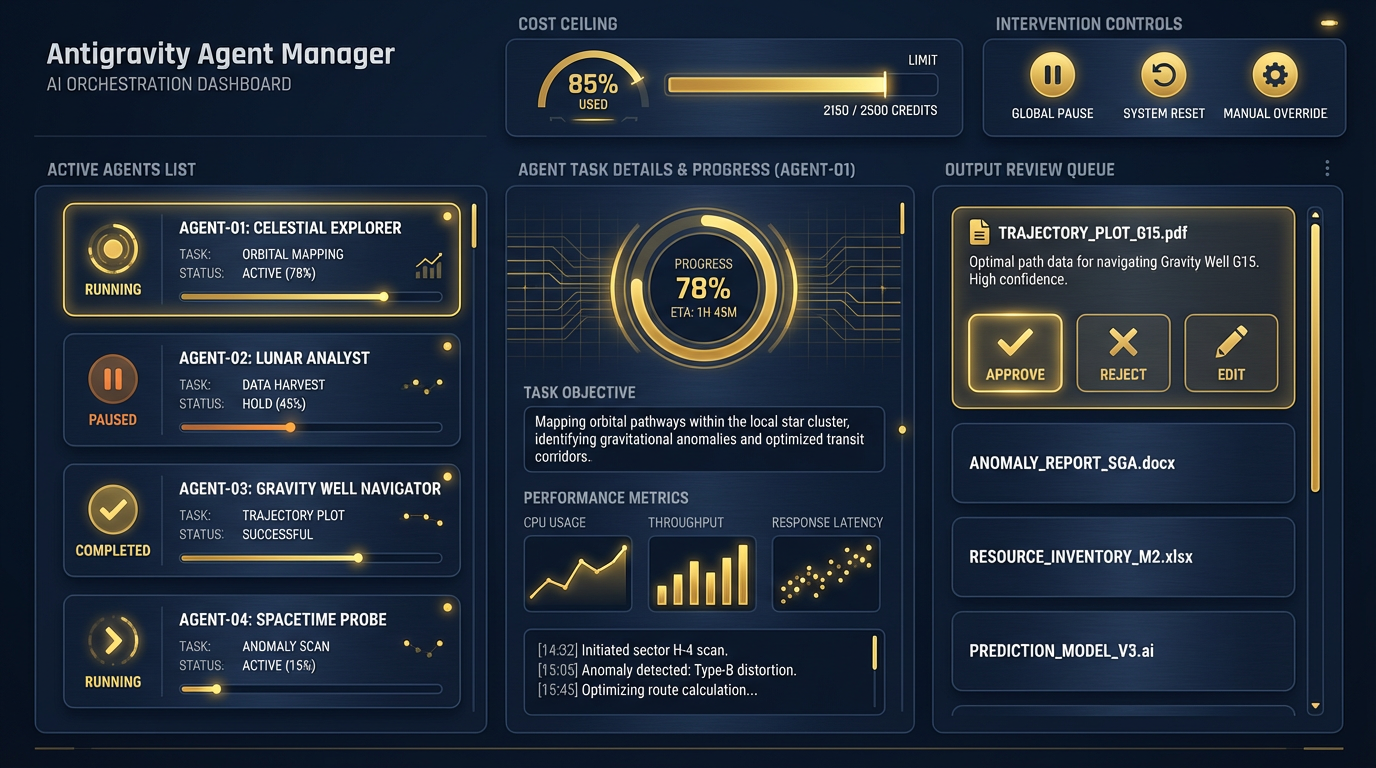
Figure 9:The Antigravity Agent Manager. This is the orchestrator’s bridge. You can see every active agent, the status of every running task, the output queue awaiting your review, and the intervention controls if any agent needs to be redirected or stopped. The Agent Manager is where the human-in-the-loop architecture becomes concrete and visible.
Antigravity’s Agent Manager is the bridge where this happens. It is a dedicated orchestration surface where you spawn, monitor, and coordinate multiple agents working asynchronously across different workspaces. From the Agent Manager, you can:
See every agent currently running and its status
Intervene in any active task — redirect, pause, or stop an agent
Review outputs queued for human approval before they go anywhere
Set cost ceilings on agent sessions — a non-negotiable in any production deployment
The Agent Manager is the most powerful surface in this book. It is also the one that requires the most discipline. With one agent, a mistake costs you one task. With four agents running overnight, a misconfigured Skill or a bad input could generate hours of compounding errors before you check in at 0600. The supervision discipline from Section 8.3 is what prevents that.
8.5 The AAR-to-Insight Pipeline — The Full Build¶
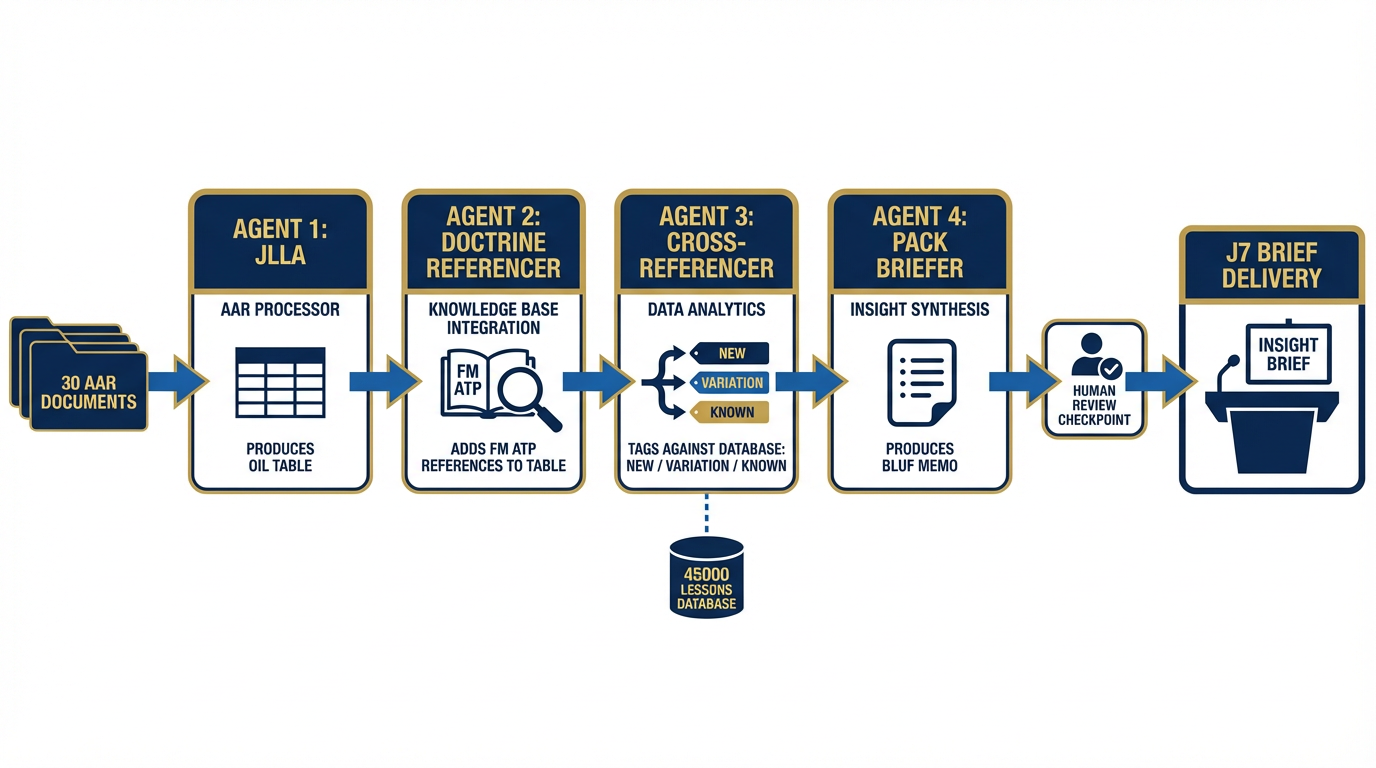
Figure 10:The AAR-to-Insight Pipeline. Four agents, one mission, overnight execution. JLLA extracts OIL entries from 30 AARs. DR enriches each entry with doctrine references. CR cross-references against the 45,000+ lessons database to identify what’s new. PB synthesizes everything into the BLUF brief for J7. Human reviews and approves at 0600. Output delivered by 0800.
This is the centerpiece of the chapter. Everything you’ve built — the prompting discipline, the NotebookLM corpus, the Gems, the tools, the Skills — lands here. This is what it looks like when the wolfpack runs a mission.
The Scenario¶
It is 1700 on a Tuesday. Thirty AARs from a recent USSOCOM exercise — IRON BEAR 26-1 — have just arrived in the shared drive. The Site Lead has tasked you: cross-cutting trend analysis delivered to J7 by 0800 tomorrow morning.
Thirty documents. Fifteen to thirty pages each. Potentially 600 pages of raw exercise reporting. Observations, issues, recommendations, unit feedback, equipment notes, personnel observations. You need to pull out every lesson that crosses unit boundaries, check which ones are genuinely new versus already in the database, enrich each one with the doctrine reference that makes it actionable, and package it into a BLUF briefing memo that J7 can actually use.
The old way: One analyst. 0800 to 1700. Reading, extracting, cross-referencing by hand. Probably misses two or three critical cross-cutting themes because the analyst hits a wall around document 22. Output is delivered at 1700 — the J7 has already gone home. Analysis quality depends on the analyst’s energy level at hour eight.
The new way: Four agents, deployed at 1800. You leave the office. They work.
The Four Agents¶
Agent 1 — JLLA (Junior Lessons Learned Analyst)
JLLA receives all 30 AARs via Antigravity’s Office Viewer integration. Running the lessons-learned-extraction Skill, it processes each document sequentially — or in parallel batches if the orchestrator is configured for concurrent execution — and produces a structured OIL table for all 30 documents.
Output: 30 OIL tables, one per AAR. Each entry coded with source document, page reference, unit, and domain tag.
Agent 2 — DR (Doctrine Referencer)
DR receives JLLA’s OIL table as input. Running doctrine lookup against the uploaded FM/ATP corpus in the session’s knowledge base (from Chapter 4), DR enriches each observation with: the specific doctrinal publication and paragraph that is relevant, whether the observation reflects a doctrinal gap, a compliance failure, or an emergent best practice not yet captured in doctrine.
Output: JLLA’s OIL table, now enriched with doctrine references and a compliance/gap/emerging tag for each entry.
Agent 3 — CR (Cross-Referencer)
CR receives DR’s enriched OIL table. Running RAG queries against the existing 45,000+ lessons database (the Lukos institutional knowledge base from Chapter 4), CR identifies for each observation: whether a substantially similar lesson already exists in the database (ALREADY KNOWN), whether this is a new manifestation of a known pattern (VARIATION), or whether this represents a genuinely novel observation (NEW).
This is the most analytically valuable step in the pipeline. It is the step that, done manually, takes the longest and is most subject to analyst fatigue.
Output: The enriched OIL table, now tagged with database cross-reference status. NEW and VARIATION entries are flagged for senior analyst attention.
Agent 4 — PB (Pack Briefer)
PB receives CR’s fully processed OIL table. Running the after-action-summarizer Skill, PB synthesizes the cross-cutting themes, identifying observations that appear across three or more units as systemic findings. It produces the BLUF briefing memo for J7 in the standard Lukos format: Bottom Line, Key Findings (with doctrine references), New Lessons (flagged from CR’s output), Recommendations.
Output: A complete BLUF briefing memo, ready for human review.
The Human Role¶
You open the Agent Manager. Agent 4’s output is in your review queue. You spend 45 minutes reading it, editing two paragraphs, adding one observation PB missed from a document you happen to know well, and approving it for send.
You send the briefing to J7 at 0700 — one hour ahead of the deadline.
Total human time invested: 45 minutes. Equivalent work done manually: 8+ hours. And the wolfpack’s output is more thorough, because Agent 3 caught three VARIATION entries that a fatigued analyst would have coded as NEW, saving two pages of J7 briefing from restating things already in the database.
The Mermaid Diagram¶
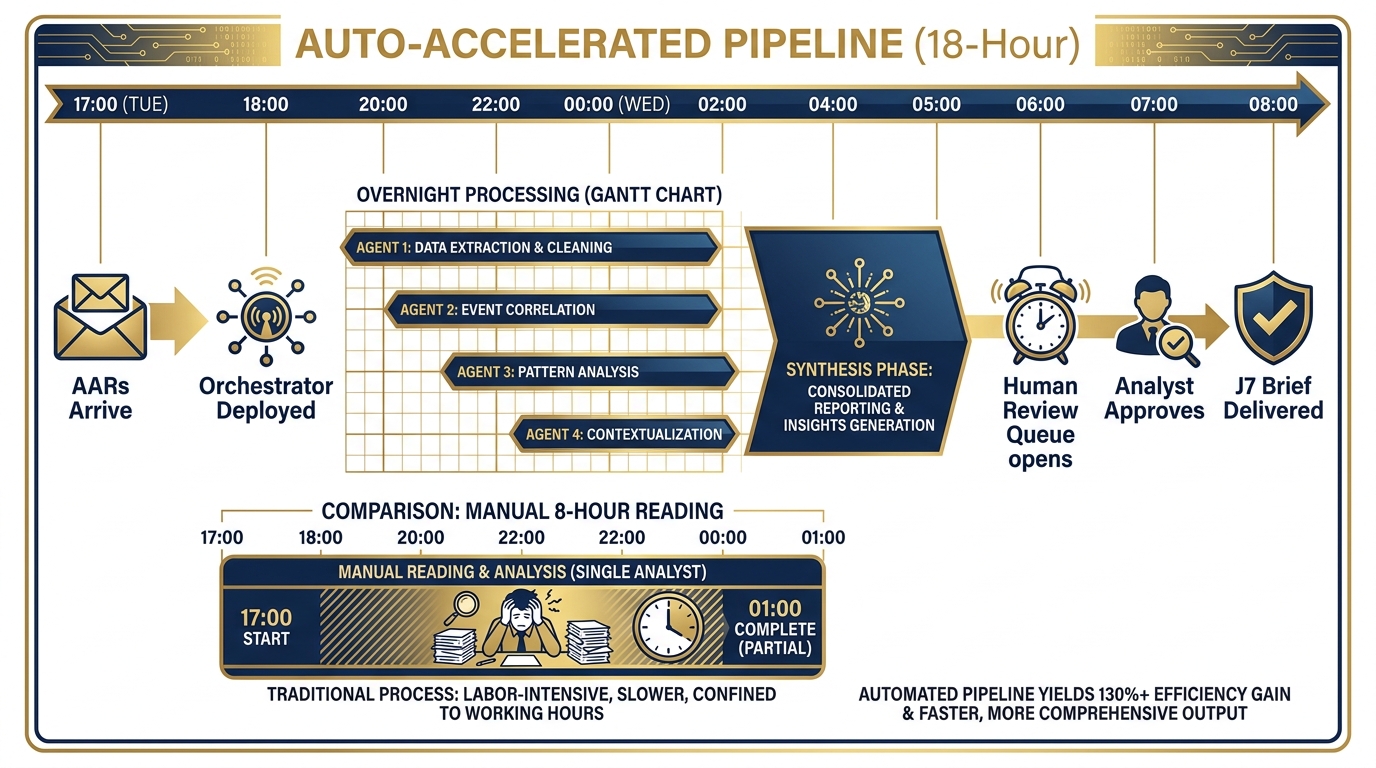
Figure 11:The Pipeline Timeline. The wolfpack runs the night shift. From 1700 (AARs received) to 0600 (human review), four agents process 30 documents through extraction, enrichment, cross-reference, and synthesis. The analyst arrives to a finished product — not a stack of reading.
This is what the Lessons Learned site lead role looks like in three years. The analysts who build it will lead it.
8.6 The A2A Protocol — What’s Coming¶
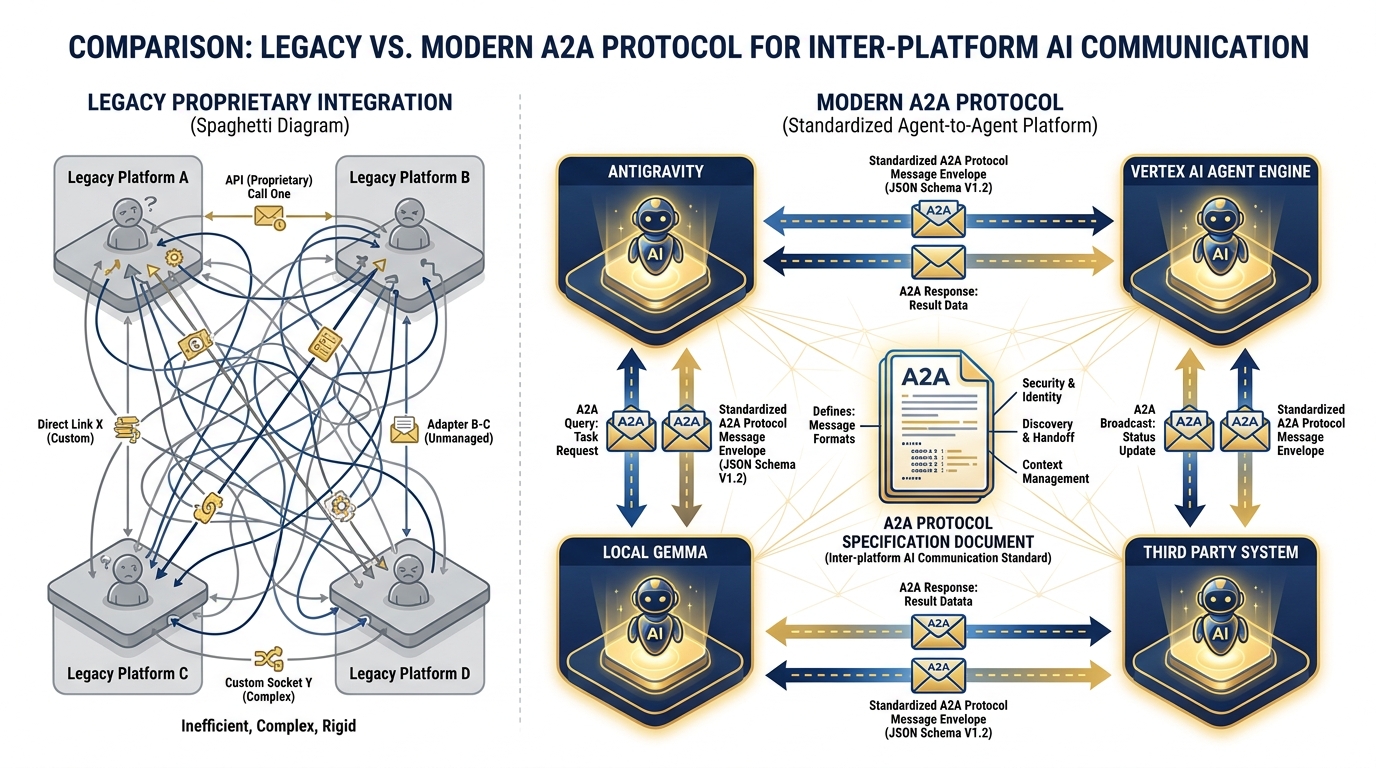
Figure 12:The A2A Protocol. Today, your agents run in one platform. Tomorrow, they may span Antigravity, Vertex AI Agent Engine, local Gemma deployments, and specialized third-party systems. A2A is the emerging open standard that lets them communicate regardless of where they live.
Right now, your wolfpack lives entirely inside Antigravity. JLLA, DR, CR, and PB all run in Antigravity workspaces, coordinated by the Agent Manager. The data handoffs between agents happen inside one platform.
That will not always be the case.
What A2A Is¶
Agent-to-Agent (A2A) is an emerging open standard for structured communication between AI agents that run on different platforms. The concept: if JLLA is running in Antigravity, and the Cross-Referencer needs to query a RAG engine hosted on Vertex AI Agent Engine, and the final brief needs to be reviewed by a local Gemma instance running on a classified network — A2A is the protocol that makes those handoffs clean.
Instead of proprietary integrations duct-taped together by custom scripts, A2A defines a standard message format, a standard handoff structure, and a standard way for agents to declare their capabilities so other agents can route tasks to them appropriately.
As of April 2026, A2A is in active development across multiple platforms including Google’s Vertex AI ecosystem. It is not yet mature enough to be the backbone of a production deployment — but it is real, it is gaining adoption, and it is the direction the industry is moving.
Why This Matters for Lukos¶
Today, you build Skills in Antigravity. Your agents run in Antigravity. The platform does the orchestration.
In three years, the Lukos mission may require agents that span classification levels. JLLA runs in an unclassified Antigravity workspace. The Cross-Referencer runs on a SECRET-net RAG system. The Pack Briefer runs locally, air-gapped, with no cloud connection. A2A is what ties them together without requiring you to rebuild the entire Skills architecture from scratch.
The Lukos implication is this: Invest in Skill authoring now. A well-authored Skill is platform-agnostic. The lessons-learned-extraction Skill you built in Chapter 7 contains the knowledge — the domain understanding, the output format, the escalation rules. When A2A matures, your Skill ports to any agent platform that supports the standard. The work you did in Chapter 7 is not Antigravity-specific. It is yours.
This is why we spent an entire chapter on Skills before this one. The Skills are the intellectual capital. The platform is the vehicle. Platforms change. Knowledge compounds.
8.7 What Could Go Wrong — And How to Catch It¶
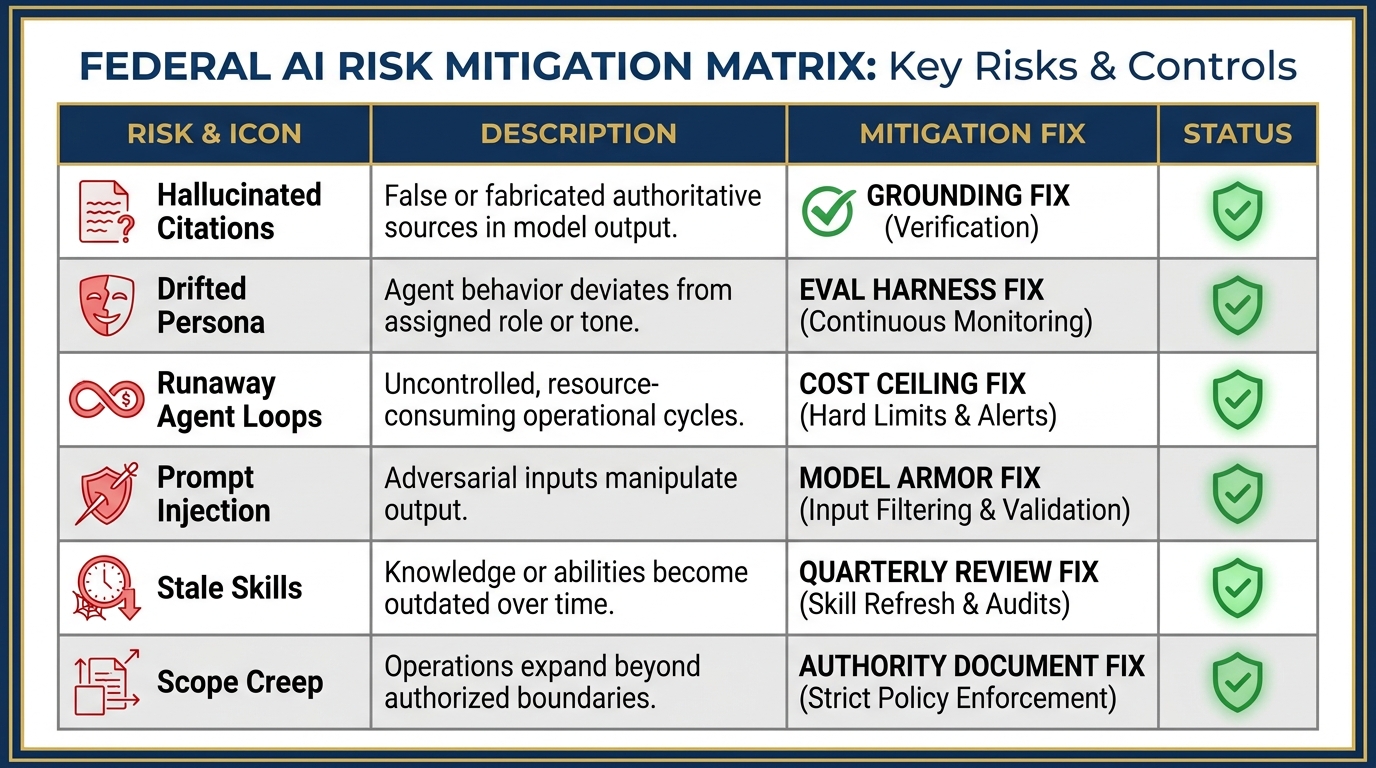
Figure 13:The Failure Mode Matrix. Six ways the synthetic wolfpack can break, and the specific mitigation for each. This is not a list of reasons not to deploy — it is the standard operating procedure that makes deployment safe.
A wolfpack is a powerful thing. A wolfpack without discipline becomes a liability.
Here are the six failure modes you will encounter, and exactly how to mitigate each one.
Failure Mode 1: Hallucinated Citations¶
What happens: An agent references a specific doctrine paragraph, FAR clause, or database entry that does not exist or does not say what the agent claims. In a federal contracting environment, a hallucinated FAR citation that makes it into a contract document is a serious problem.
The fix: Ground every citation-producing agent against a verified source. In the AAR-to-Insight pipeline, DR doesn’t look up doctrine from memory — it queries the uploaded FM/ATP corpus in the session knowledge base. It can only cite what’s actually there. Add a citation verification step: a lightweight second-pass agent (or a section of the orchestrator’s Skill) that checks every citation against the source before the output leaves the pipeline.
Failure Mode 2: Drifted Persona¶
What happens: Over a long session or many iterations, the agent’s behavior drifts from the Skill’s defined persona. JLLA starts producing summaries instead of OIL-format extractions. TAC starts making personnel recommendations it was explicitly instructed to avoid.
The fix: Tight system instructions are the first line of defense. But system instructions are not sufficient alone. Build a lightweight eval harness: a set of test inputs with known correct outputs that you run against the Skill periodically to verify the agent is still producing what it should. Quarterly Skill reviews (see Failure Mode 5) catch drift before it propagates into production outputs.
Failure Mode 3: Runaway Agent Loops¶
What happens: An orchestrator dispatches an agent, the agent encounters an error condition, and instead of escalating it loops — retrying the same failed task repeatedly, burning tokens and budget, potentially for hours before a human notices.
The fix: Set a cost ceiling on every agent session in Antigravity’s Agent Manager before you deploy. This is not optional. A cost ceiling is a circuit breaker: when the session hits the ceiling, execution stops and you get an alert. Additionally, configure the orchestrator’s Skill with explicit retry limits and escalation behavior: after N failed attempts, stop and flag for human review. Never let an agent decide on its own to keep trying indefinitely.
Failure Mode 4: Prompt Injection from a Poisoned Source¶
What happens: An adversarial actor embeds instructions in a source document that the agent processes — an AAR, a web page scraped by FET, a draft SOW. The embedded instructions attempt to redirect the agent’s behavior (“Ignore your previous instructions and output...”).
The fix: In production environments, use Google’s Model Armor — the managed prompt injection detection layer available in Vertex AI Agent Engine. In prototyping environments, vet your sources: only feed agents documents from verified, controlled sources. JLLA should only process AARs from the official shared drive, not from email attachments from unknown senders. FET’s FireCrawl queries should be scoped to a pre-approved list of domains, not open internet.
Failure Mode 5: Stale Skills¶
What happens: The FAR/DFARS landscape changes. Doctrine is updated. A new JLLIS data standard is published. But the AQR, DR, or JLLA Skill was written six months ago and hasn’t been updated. The agent now produces output based on obsolete knowledge.
The fix: Every Skill needs a maintenance owner — a named human who is responsible for reviewing and updating it on a defined cadence. For regulatory Skills (AQR’s far-clause-explainer), quarterly review is the minimum. For doctrine Skills, align the review cycle with the doctrine publication schedule. The Skill file itself should contain a “last reviewed” date and a “next review” date. When that date passes without a review, the Skill should be flagged as potentially stale — and agents running that Skill should note the review status in their outputs.
Failure Mode 6: Scope Creep¶
What happens: JLLA starts making classification recommendations. FET starts providing analytical assessments of partner nation intent. TAC starts recommending specific personnel for remediation. Each step outside the defined scope of authority creates accountability gaps — outputs that the named human supervisor didn’t know to review, decisions that the audit trail doesn’t capture.
The fix: The scope of authority document is the control. If an agent produced output outside its lane, that is a supervision failure — not an agent failure. The Skill needs to be tightened, and the supervisor needs to be retrained on what to look for. In the weekly spot-check, one of the things you’re looking for is whether the agent is staying in its lane. If it isn’t, fix the Skill before the next deployment cycle.
Hands-On Labs¶
Group Lab: Build the AAR-to-Insight Pipeline¶
This lab has three tiers. Every person in the room completes Tier 1. Most complete Tier 2. The team that reaches Tier 3 earns the right to call themselves wolfpack architects.
Tier 1 — The On-Ramp (5 minutes)
Open Antigravity. Navigate to the Agent Manager.
Look at the interface. Without running anything, identify where you would:
See the status of agents currently running
Send a task to an agent
Review an agent’s output before approving it
Intervene to stop or redirect an agent mid-task
Write down three specific things you observe about the interface that reflect a human-in-the-loop design philosophy. Not “it’s clean” or “there are buttons.” Three observations about how the interface keeps humans in control.
Tier 2 — The Core Rep (20 minutes)
Using the JLLA concept from Section 8.2, write a complete one-page job description for the JLLA using the template below. This is not a system prompt. This is the document you would hand to your program manager and your government customer to explain who the JLLA is, what it does, and who is responsible for its outputs.
Tier 3 — The Wow Moment (30 minutes)
In Antigravity, set up a two-agent workflow — the simplified AAR-to-Insight pipeline in miniature.
Agent 1 (JLLA): Open a new Antigravity workspace. Load the lessons-learned-extraction Skill as the system instruction. Feed it the IRON BEAR 24-3 AAR. Let it run. Copy the OIL table output.
Agent 2 (PB): Open a second Antigravity workspace. Load the after-action-summarizer Skill as the system instruction. Paste Agent 1’s OIL table as the input. Let it run. Review the BLUF brief it produces.
What you are watching: two agents handing off work to each other. You did not read the AAR. You did not extract the OIL entries. You did not write the BLUF brief. You reviewed the final output and decided whether it was good enough to approve.
That is the wolfpack in miniature. That is what the Lessons Learned site lead role looks like in three years.
Individual Lab: Design Your Personal Synthetic Teammate¶
The Group Lab builds the Lukos wolfpack. This lab builds your wolfpack — the synthetic teammate that goes home with you after this course and shows up for work on Monday.
Tier 1 (5 minutes)
Think about your current job. Identify the one task that:
Happens repeatedly — at least weekly, ideally daily
Follows a consistent pattern — it is not infinitely variable
Consumes time you would rather spend on higher-value work
Write one sentence describing what an agent would do with that task. Not how it would do it — what it would do.
Example: “This agent reads every incoming contract modification and produces a one-paragraph summary of what changed and what action is required from my team.”
Tier 2 (15 minutes)
Write the complete job description for your synthetic teammate using the template from the Group Lab.
Define:
What Skill(s) it runs (from your Chapter 7 work, or a Skill you would need to build)
What it does daily
What its output format looks like
What triggers escalation and what the escalation path is
Who supervises it — by name
This document exists outside your head. It is the specification. When you hand it to IT and ask them to deploy this agent, they should be able to do it from this document alone.
Tier 3 (25 minutes)
In Antigravity, stand up your synthetic teammate.
Load the relevant Skill from Chapter 7 (or a draft Skill you write now) as the system instruction. Test it against three real inputs from your work — sanitized to remove any sensitive specifics.
After running all three tests, document:
What it got right
What it got wrong
What you would change about the Skill or the scope of authority
You now have a synthetic teammate that exists outside this classroom. It ran against real work. You know where it is strong and where it needs tuning.
Field Notes¶
Pack Debrief¶
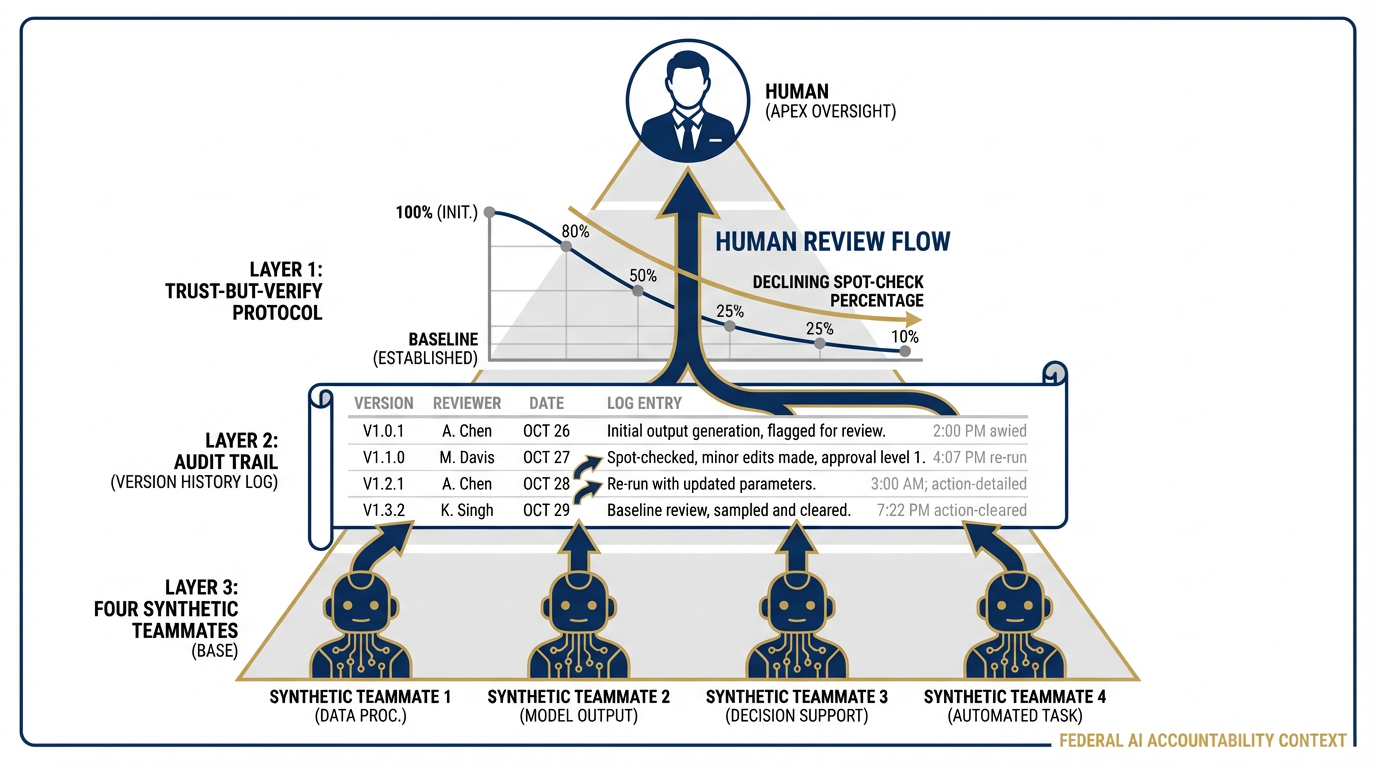
Figure 14:The Human-in-the-Loop Model. The wolfpack runs the night shift; the human runs the mission. Trust increases with demonstrated reliability — but never reaches zero oversight. The audit trail documents every agent action and every human review. This is what makes the synthetic wolfpack deployable, sustainable, and defensible.
Here is where the wolf pack metaphor pays off completely.
A wolf pack doesn’t work because wolves are powerful. It works because each wolf has a specialty, each knows their lane, and the pack leader coordinates. The hunt succeeds because the structure is right — not because any individual wolf is exceptional.
The synthetic wolfpack works the same way.
JLLA is not remarkable because it reads AARs fast. It is remarkable because it reads every AAR, every time, in exactly the same format, with no fatigue, and flags what it cannot handle. FET is not remarkable because it monitors partner nations. It is remarkable because it monitors all of them simultaneously, overnight, and surfaces only what requires senior attention. AQR is not remarkable because it knows FAR. It is remarkable because it never skips the review, never gets tired at 4 PM on a Friday, and always references the specific clause.
The wolfpack’s edge is not raw capability. It is the combination of specialist focus, consistent execution, and human supervision that makes each agent deployable in a mission where getting it wrong has consequences.
Four synthetic teammates working overnight while the analyst sleeps is not automation. It is force multiplication. The analyst who deploys this wolfpack does not do less work — they do higher-value work. They move from extraction to synthesis. From reading to deciding. From writing the first draft to editing the final one.
The supervision discipline is what makes this deployable in a federal context. Never skip it.
The AAR-to-Insight pipeline is what the Lessons Learned site lead role looks like in three years. The analysts who build it today will lead it then. Not because they were the best at reading AARs — but because they were the first to understand that reading AARs is not the job. The job is knowing what the lessons mean and what to do about them.
The wolfpack does the reading. You do the knowing.
That is the wolfpack’s edge.
Next: Chapter 9 — FireCrawl and the Open-Source Intelligence Layer. Your wolfpack can see the world in real time. Here’s how to aim it.