The Research Partner¶
“The Lessons Learned problem has always been the same: you have the answer somewhere in the corpus. The problem is finding it — and finding it fast enough to matter.”
Stop for a moment and think about what you actually do.
You collect AARs. You manage observations. You maintain lessons databases. You synthesize findings across exercises, programs, and years of operational experience. You brief senior leaders on patterns that only become visible when you hold dozens of reports in your head at once — and somehow, you do that by reading. One document at a time. In a folder on a SharePoint drive that nobody outside your team can navigate.
Now imagine something different.
Imagine you could upload every AAR from the last fiscal year — all thirty of them — and then talk to them. Not search them. Not ctrl-F your way through them. Talk to them. Ask: “What are the top three recurring themes around C2 effectiveness?” and receive an answer with six citations, each one a clickable link that lands on the exact paragraph in the exact document that supported the claim.
Imagine you could generate a twenty-five-minute podcast-style briefing from those same documents. A briefing your senior leader can listen to on the drive in. A briefing where two AI voices discuss YOUR documents — your specific programs, your specific observations, your specific language — in a natural, engaging conversation.
Imagine you could generate a mind map of conceptual clusters from a year of training evaluations. Not after reading all of them. From the upload.
That tool exists. It’s free. You have a Google account. It’s called NotebookLM.
And here’s the thing that makes this chapter different from everything that came before it: NotebookLM was not accidentally useful for Lessons Learned work. It is structurally aligned with the Lessons Learned mission. Once you understand why, you will never go back to reading documents one at a time.
Let’s build that understanding — from the ground up.
14.1 What NotebookLM Is¶

Figure 1:The NotebookLM interface. Three panels, one mission: grounded intelligence from your documents. Sources (left), Chat (center), Studio (right).
Here is the single most important thing to understand about NotebookLM before you touch it:
NotebookLM does not know anything about the world. It only knows what’s in your notebook.
That’s not a limitation. That’s the feature.
Every AI tool you’ve encountered so far — Gemini, ChatGPT, AI Studio — draws from a training corpus that includes a significant fraction of everything published on the internet before a cutoff date. That’s extraordinarily powerful for general questions. “What are best practices for after-action reviews?” — Gemini has read thousands of papers, doctrines, and articles on that topic and can synthesize them brilliantly.
But it creates a serious problem: when you ask the model about your specific programs, your specific exercises, your specific observations, it doesn’t know them. Worse, it might confidently generate something that sounds like it could be from your corpus but isn’t. That’s called hallucination — the model producing plausible-sounding but fabricated information. It’s the AI equivalent of a briefer who fills in knowledge gaps with confident-sounding speculation.
NotebookLM solves this problem with a fundamental constraint: it can only answer from the sources you provide, and it must cite every claim back to a specific passage in those sources.
If the answer isn’t in your documents, NotebookLM says so. Not confidently wrong. Just: “I don’t see that addressed in the sources provided.”
That one behavior is worth more than a hundred features.
Powered by Gemini 3.1 Pro, Grounded in Your Sources¶

Figure 2:Gemini 3.1 Pro in NotebookLM. As of February 2026, Google AI Pro and Ultra subscribers access NotebookLM powered by Gemini 3.1 Pro. Free tier users receive an earlier Gemini model. The upgrade unlocks the most capable grounded research engine available. (as of April 2026)
Under the hood, NotebookLM is powered by Google’s Gemini models. As of February 2026, Google AI Pro and Ultra subscribers access NotebookLM powered by Gemini 3.1 Pro — Google’s most capable model. Free tier users receive an earlier Gemini model. But instead of pointing Gemini at all its training knowledge, Google has built a layer that constrains the model to only the documents in your current notebook. This is called grounding — and it’s what makes NotebookLM the most trustworthy AI tool for professional document work.
The difference from public Gemini is profound:
Public Gemini: “Draw on everything you know to answer this question.” Vast knowledge. No citations. Potential for hallucination.
NotebookLM: “Draw only on these specific documents to answer this question.” Limited scope. Mandatory citations. No hallucination about your content.
For Lukos work — where accuracy is mission-critical and citations are professional requirements — this distinction is everything.
Your First NotebookLM Session: Getting Started¶
Here’s exactly how to get to the tool:
Open your browser and navigate to notebooklm
.google .com Sign in with your Google account (the same one you use for Gmail, Calendar, everything else)
You’ll see your NotebookLM dashboard — a clean page with any notebooks you’ve created
Click “Create new notebook” (or the “+” button in the upper left)
A dialog appears asking you to name your notebook — give it a meaningful name (e.g., “FY25 AAR Corpus” or “JCET Program Review”)
Your new notebook opens with three panels: Sources (left), Chat (center), Studio (right)
That’s it. You’re in.
24.2 Why This Matters to Lukos More Than Almost Anyone¶
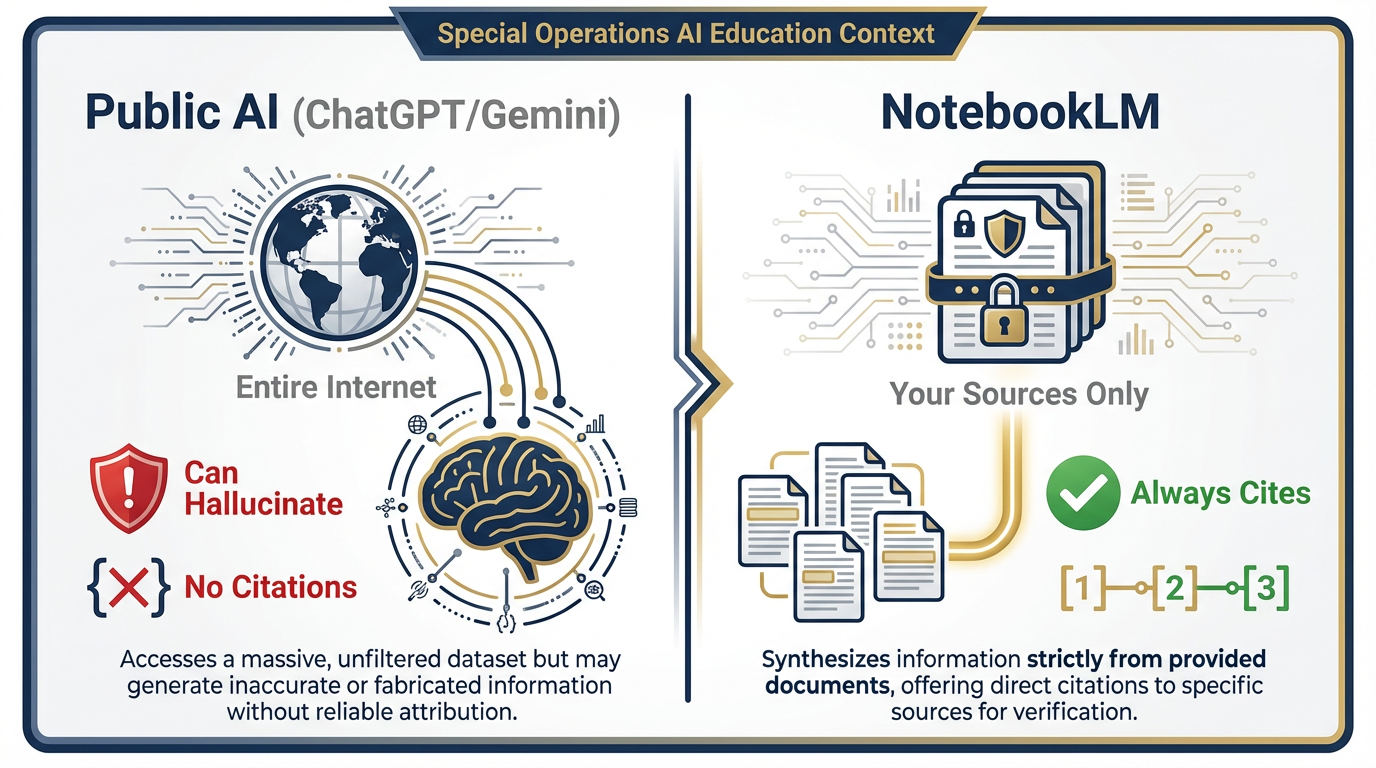
Figure 3:The fundamental difference. Public AI draws from everything and cites nothing. NotebookLM draws from your sources and cites everything. For professional Lessons Learned work, this is the only tool that counts.
Let’s have the honest conversation.
There are many AI tools in the world. Most of them are useful. Some of them are remarkable. But NotebookLM occupies a unique position for one reason: the Lessons Learned mission is structurally a document corpus problem, and NotebookLM is structurally a document corpus tool.
Think about what the Lukos Lessons Learned Program actually is.
It is a collection of after-action reviews. Observations. Lessons databases organized by program, year, and functional area. Doctrine publications. Training evaluations. Joint lessons learned reports from JLLIS. Experimentation findings from USSOCOM’s J7 enterprise. SOF Component Command assessments. After years of work, that corpus represents thousands of documents and tens of thousands of individual observations — each one a data point about what worked, what didn’t, and why.
The Lukos database contains more than 45,000 lessons learned entries.
Forty-five thousand.
Think about what it takes to actually use that corpus. Right now, an analyst sits down with a research question — “What are the persistent challenges in partner nation interoperability at the tactical level?” — and begins reading. Maybe there’s a keyword search. Maybe there’s a database query. But ultimately, the analyst is pulling reports, skimming documents, and building a picture in their head. Across thirty reports. Maybe fifty. Maybe more.
That process takes hours. Sometimes days. And when the senior leader asks a follow-up question at the morning brief, the analyst goes back through the stack again.
Now here’s the scenario where everything changes.
You take those same documents — let’s say thirty AARs from the last two fiscal years, all focused on partner nation exercises. You upload them to a NotebookLM notebook. It takes ten minutes. Then you type:
“What are the persistent challenges in partner nation interoperability at the tactical level across these AARs? Identify the top five themes and cite the specific source documents that support each theme.”
In thirty seconds, you receive a structured response: five themes, each with a description, and each with inline citations like [Source 3, p. 14] and [Source 11, p. 7]. You click Source 3. You land on the exact paragraph. The claim is accurate. The citation is precise.
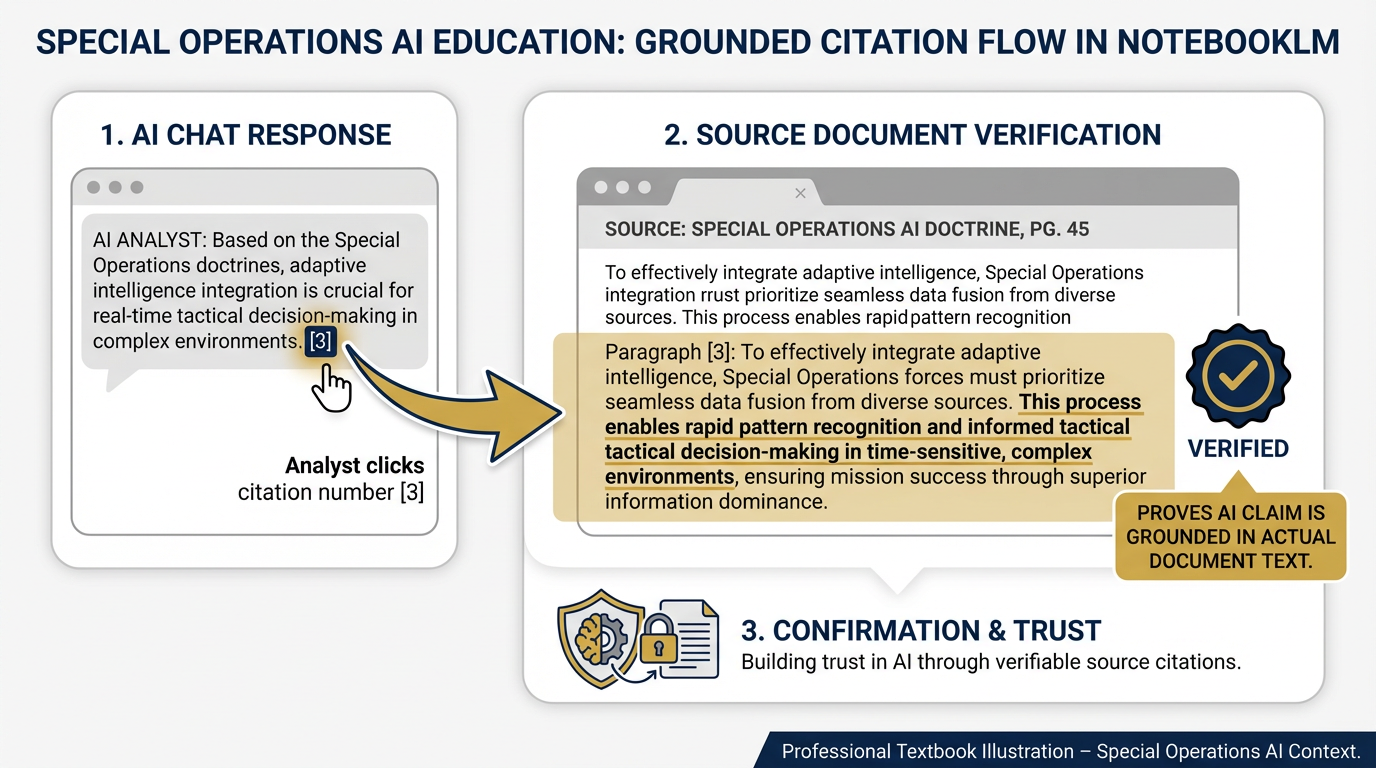
Figure 4:Citation verification in action. Every claim in NotebookLM’s Chat panel is backed by a citation. Click any citation number and NotebookLM highlights the exact supporting paragraph in your source document. This is grounded AI — no fabrication, no guesswork. (as of April 2026)
That is not science fiction. That is Tuesday morning.
The Scale Transformation¶
Here’s what changes when you operate at AI speed with a 45,000-entry corpus.
A research question that took three days now takes thirty minutes — the time to curate and upload the relevant subset, write the query, and review the output. The analyst’s job shifts from extraction to validation and judgment. The analyst stops being a document reader and starts being an intelligence officer. They’re evaluating the AI’s synthesis, adding context the AI doesn’t have, catching errors, and applying operational judgment that no model can replicate.
That is a more valuable analyst. That is a better product. That is a competitive advantage for Lukos that compounds every year the corpus grows.
And here is the emotional truth — the thing that Lessons Learned practitioners feel but rarely say out loud:
The work that goes into building a lessons learned corpus has historically been invisible. The value is theoretical. “Somewhere in here is the answer to the problem you’re about to make.” But who has time to find it? The program manager has a deliverable due Friday. The ORSA is building a model. The J7 counterpart has twelve other contractors in the queue.
NotebookLM makes that corpus queryable. The years of careful collection, coding, and maintenance suddenly have a user interface. The institutional knowledge your team has built becomes accessible at the speed of a question.
That’s the moment. That’s why this chapter comes before any other AI tool in this book that Lukos hasn’t already touched. Because this is the one.
34.3 Free vs. Google AI Pro vs. Google AI Ultra¶
NotebookLM comes in three tiers. Here’s what each means for Lukos. (Pricing and features as of April 2026; see Google AI plans for current details.)
| Feature | Free | Google AI Pro | Google AI Ultra |
|---|---|---|---|
| Gemini Model | Earlier Gemini | Gemini 3.1 Pro | Gemini 3.1 Pro |
| Notebooks | Unlimited | Unlimited | Unlimited |
| Sources per notebook | 50 | 300 | 300+ |
| Pages per source | 500 | 500 | 500 |
| Audio Overviews | 3/day | Unlimited | Unlimited |
| Studio outputs | All types | All types | All types |
| Sharing | View-only link | Collaborative editing | Collaborative editing |
| Cost | $0 | ~$20/mo | ~$250/mo |
| Data residency / DLP | Standard | Standard | Enterprise policies |
| Support | Community | Priority | Priority+ |
What Lukos Should Actually Use¶
Free tier: For exploration, familiarization, and individual professional use with non-sensitive documents. Every analyst on the team should start here. The limits (50 sources, 3 audio overviews per day) are sufficient for learning the tool and running most individual research workflows. Access at notebooklm
Google AI Pro (~$20/month): For production Lessons Learned work. The upgrade from 50 to 300 sources per notebook is the key unlock — it means you can load a full fiscal year of AARs into a single notebook rather than segmenting. You also gain Gemini 3.1 Pro as the underlying model, which delivers meaningfully better synthesis quality on complex research questions. Unlimited audio overviews matter when your team is generating briefings regularly. This is the tier for analysts whose primary job is research synthesis.
Google AI Ultra (~$250/month): For power users and teams with the highest production volume. Includes everything in Pro plus the highest usage limits and enterprise-grade support. For institutional deployment under government contract with data handling requirements, coordinate with your organization’s Google Workspace administrator and contracting officers.
The progression for a Lukos team: Everyone starts free. Production analysts move to Pro. Enterprise deployment for customer-facing work goes through the organizational conversation — not the personal subscription path.
44.4 The Three Panels — A Guided Tour¶
Open NotebookLM on any notebook and you see three panels. Each has a specific job.
Panel 1: Sources — Where Intelligence Lives¶
The Sources panel (left side) is where you upload the documents that define your research universe. Think of it as your evidence stack — the documents this NotebookLM notebook will think only about.
What NotebookLM can ingest:
PDF files (the primary format for AAR submissions and doctrine publications)
Google Docs and Google Slides (direct integration — add by URL or browse Drive)
Microsoft Word and PowerPoint files
Audio files (.mp3, .wav, .m4a — NotebookLM transcribes and indexes)
YouTube URLs (NotebookLM transcribes the video and adds it as a source)
Web URLs (NotebookLM fetches and indexes the page content at load time)
Pasted text (copy-paste any text directly as a source)
What NotebookLM cannot ingest:
Classified systems or networks (there is no clearance pathway; this tool is for unclassified work)
Live databases (it doesn’t have API connections; it works from static documents)
Password-protected files it can’t access
Real-time data (it indexes at upload time; the source doesn’t update automatically)
The operational implication: If your AARs live in a NIPR SharePoint or a classified system, you need to export them to an unclassified format before using NotebookLM. This is a deliberate process — and it should be. The classification discipline belongs with you, not the tool.
Adding sources: Click the “+” button in the Sources panel, or drag and drop files directly into the panel. Each source gets a card with its title and a brief auto-generated summary. Click any source card to view its content.
Panel 2: Chat — Grounded Intelligence on Demand¶
The Chat panel (center) is where you conduct research. Every question you ask is answered only from the sources in your notebook. Every claim is supported by an inline citation.
Here’s what a real interaction looks like:
You: Across all sources in this notebook, what are the most common factors that contributed to successful JCET execution? Please identify the top three and cite the specific documents that support each.
NotebookLM:
Based on the sources in this notebook, the three most common success factors for JCET execution are:
1. Pre-deployment coordination with host nation counterparts [1][3][7] Multiple AARs highlight that JCETs with the strongest outcomes had established relationships with host nation liaison officers at least 90 days prior to execution. Source 1 (FY24 Q2 JCET AAR — Country A) notes that “early engagement with the HN J3 allowed for realistic training objectives to be negotiated before the team arrived” [1, p. 4]. This pattern appears consistently across programs with positive training effectiveness ratings.
2. Realistic and jointly-developed training objectives [2][5][7] Sources 2 and 5 both flag JCETs where training objectives were developed unilaterally as having lower partner nation engagement scores...
You click citation [1]. NotebookLM jumps to page 4 of the FY24 Q2 JCET AAR. The exact sentence is highlighted. You read the original context. The claim holds.
That is what grounded AI looks like in practice. No speculation. No fabrication. Just the corpus, cited.
Panel 3: Studio — The Transformation Engine¶
The Studio panel (right side) is where NotebookLM becomes something different from any other AI tool on the market. This is where your document corpus gets transformed into new formats.
We’ll cover the full Studio arsenal in Section 4.5. For now: Studio is where audio overviews, mind maps, briefing docs, slide decks, and infographics live. Every output is generated from your sources — grounded, sourced, and ready for use.
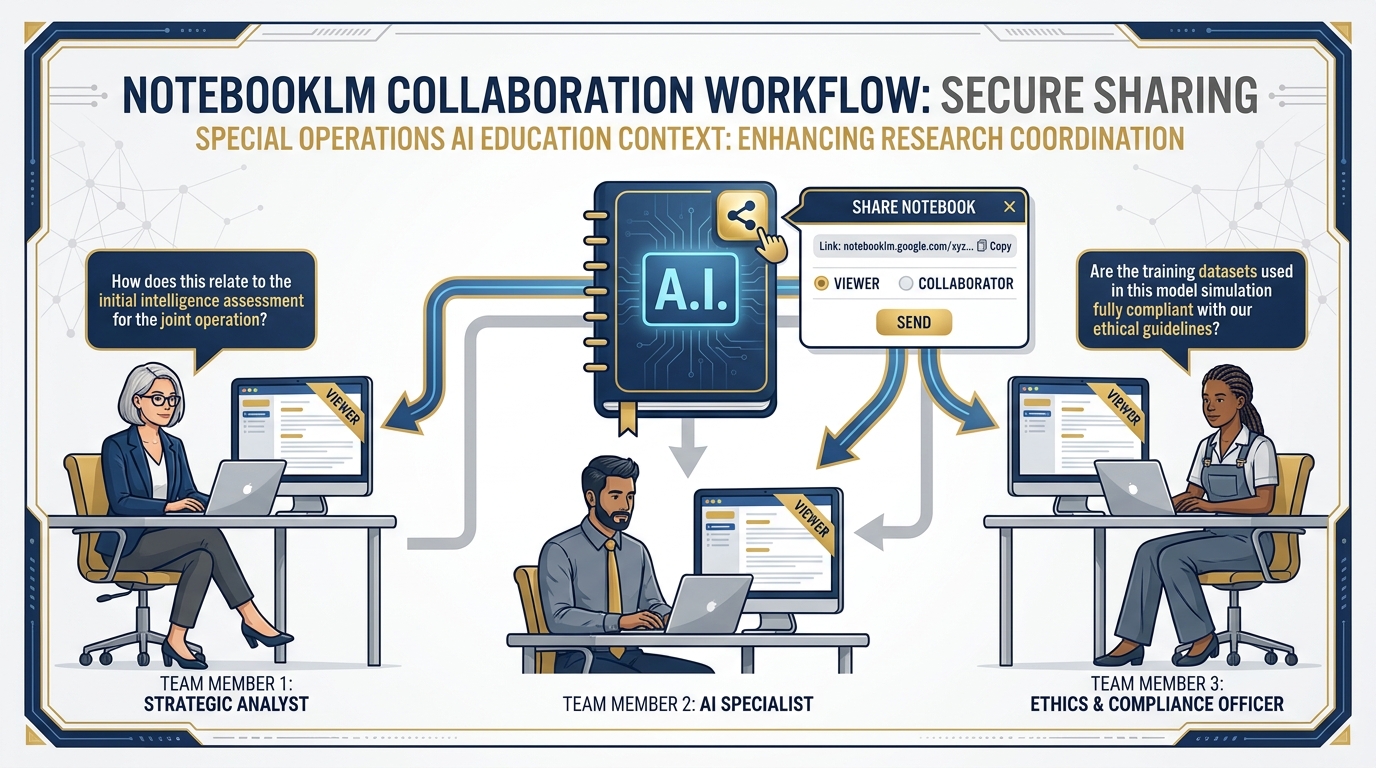
Figure 5:Collaborative research. Share any NotebookLM notebook with teammates. Viewers can ask questions in Chat without adding sources. Collaborators can add sources and contribute to the corpus. Your research assistant becomes the team’s research assistant. (as of April 2026)
54.5 Studio Outputs — The Full Arsenal¶
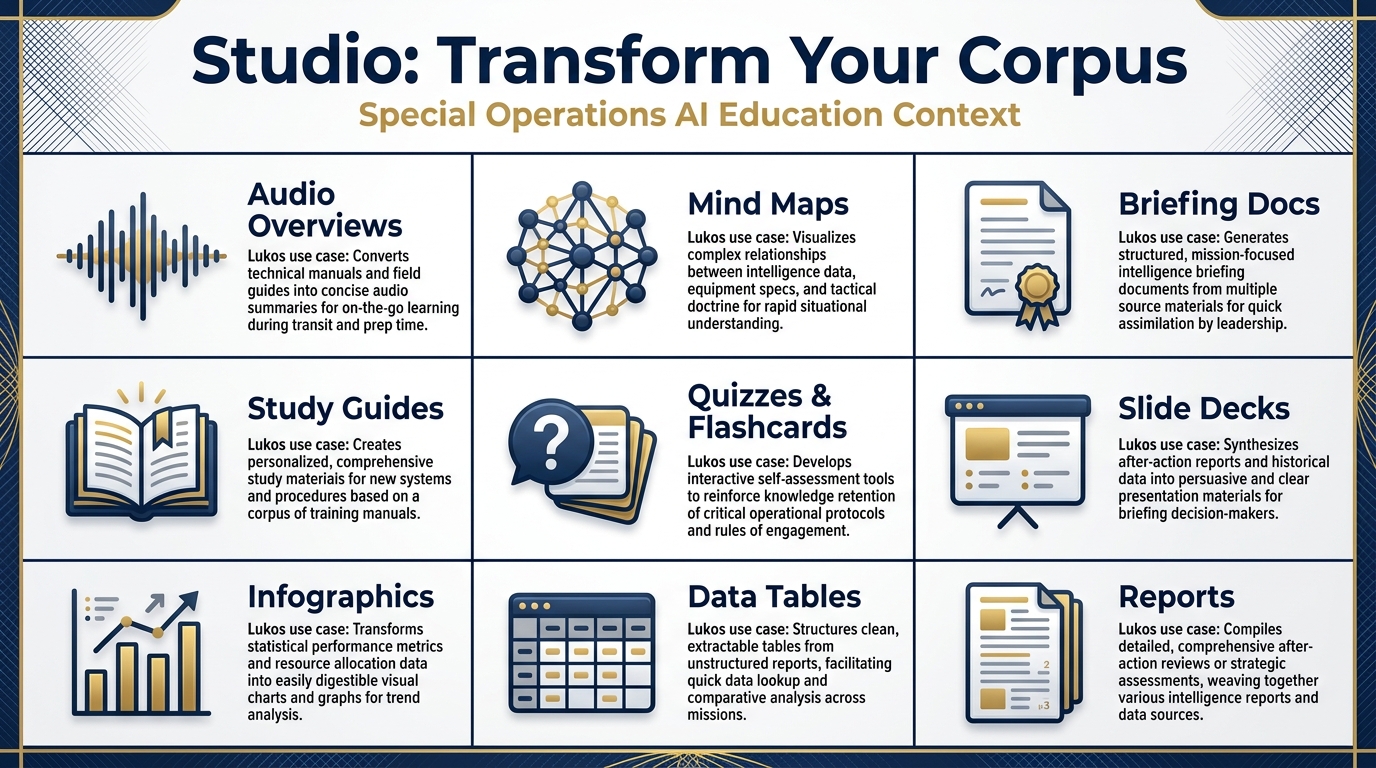
Figure 6:The Studio arsenal. Ten output types, all grounded in your sources. Each one transforms the same corpus into a different format for a different audience. (as of April 2026)
The Studio panel is genuinely extraordinary. Let’s walk through every output type — what it is, how to generate it, and the specific Lukos workflow it enables.
Audio Overviews — Your AI Podcast Crew¶
What it is: NotebookLM generates a podcast-style audio discussion of your document corpus. Two AI hosts have a natural conversation about the content of your notebook — discussing key findings, debating implications, asking each other questions, surfacing themes. It sounds like a professional podcast. Except the “topic” is your AARs.
The four modes (as of April 2026):
Brief (~5 minutes): High-level summary of the main themes. Good for a quick orientation.
Standard (10–15 minutes): Broader coverage with more depth on key findings.
Deep Dive (20–30 minutes): Full exploration of themes, including nuances, tensions, and implications. This is the flagship mode for serious research synthesis.
Critique: The two hosts actively challenge the claims in your documents — pushing back, surfacing assumptions, arguing counterpoints. This is red-teaming as a Studio output.
How to generate: In the Studio panel, click “Audio Overview”, select your mode, and click “Generate”. It takes 2–5 minutes for a Deep Dive. While it generates, go do something else.
The Lukos JCET workflow: You have ten AARs from last quarter’s JCET program. You upload all ten. You generate the Deep Dive Audio Overview. You now have a 25-minute discussion of the cross-cutting themes, the key success factors, the recurring gaps, and the notable observations — narrated in clear, professional English. You send it to your program manager. They listen on the commute in. They arrive at the morning brief already briefed.
That’s the “send the boss a podcast” pattern. We’ll cover it in depth in Section 4.8.
Mind Maps — Pattern Detection at Machine Speed¶
What it is: A visual representation of the conceptual structure of your document corpus. NotebookLM identifies the main themes, sub-themes, and relationships within your sources and renders them as an interactive visual map.
Why it’s the hidden gem: Most people find the Audio Overview first and are blown away by it. But the analysts who use NotebookLM seriously — the ones who have run it against real document sets — will tell you the Mind Map is quietly the most powerful feature in the Studio.
Here’s why. When you read thirty documents sequentially, your brain is building a mental model of the conceptual landscape. That process takes hours and produces a map that lives only in your head. The Mind Map generates that same map — from the upload. Before you’ve read a single document.
Upload a year of training evaluations. Generate the Mind Map. The clusters that appear — the themes that group together, the sub-themes that branch off, the concepts that bridge multiple clusters — represent the conceptual architecture of your corpus. You can see pattern structures that would take days of manual analysis to identify.
The Lukos use case: At the start of a new program review cycle, before any analyst reads a document, generate the Mind Map. Use it to orient the team. Assign analysts to clusters. Let the AI tell you what the terrain looks like before you start walking it.
How to generate: In the Studio panel, click “Mind Map” and then “Generate”. The result is an interactive map you can zoom, pan, and explore. Click any node to see the supporting sources.
Briefing Docs — Synthesis in One Click¶
What it is: A 1–2 page synthesized summary of the key themes, findings, and insights across your sources. Think of it as the executive summary your sources would produce if they could write one together.
The Lukos use case: You’ve just loaded a new notebook with the source documents for a program review. Before you start your analysis, generate the Briefing Doc. It gives you an oriented starting point — a map of what’s in the corpus, what the major themes are, and where the interesting tensions lie. Use it to structure your own analysis, not replace it.
How to generate: Studio panel → “Briefing Doc” → “Generate”.
Study Guides — Training-the-Trainer Made Easy¶
What it is: A structured study guide from your corpus — key concepts, important passages, suggested questions for discussion, and learning objectives.
The Lukos use case: You’re running a lessons learned training event. You’ve assembled the reading materials in a notebook. Generate the Study Guide as a facilitator’s guide. The AI has identified what’s most important across the materials and structured it for learning. You adapt and use it.
Quizzes and Flashcards — Knowledge Transfer at Scale¶
What it is: Multiple-choice quizzes and flashcard sets generated from your source documents. Each question and answer is grounded in the actual content.
The Lukos use case: New team members need to get up to speed on program history and doctrine. Build a notebook with the key reference documents. Generate the Quiz. New hires test their understanding against the actual corpus — not abstract knowledge, but the specific material that defines Lukos’s institutional knowledge base.
Slide Decks — The Outline You’ve Always Wanted¶
What it is: An outline-level slide deck generated from your sources. NotebookLM creates a structured presentation framework — slides, bullets, key points — that you then populate and refine in Google Slides.
The Lukos use case: You’ve been asked to brief the customer on program findings. You have the source documents in a notebook. Generate the Slide Deck outline. You now have a structured starting point — not a blank slide — that reflects the actual content of your corpus. Refine and add visuals. Present.
Infographics — One Image, One Brief¶
What it is: A visual summary of key themes and data from your sources, formatted as an infographic.
The Lukos use case: Leadership briefings where visuals do more work than bullets. Use the Infographic Studio output as a starting point, then refine in Slides or a design tool.
Data Tables — Structure from Chaos¶
What it is: NotebookLM extracts structured data from unstructured sources and formats it as a table. If your AARs consistently mention dates, programs, locations, or metrics — even in narrative form — the Data Table output can extract and organize them.
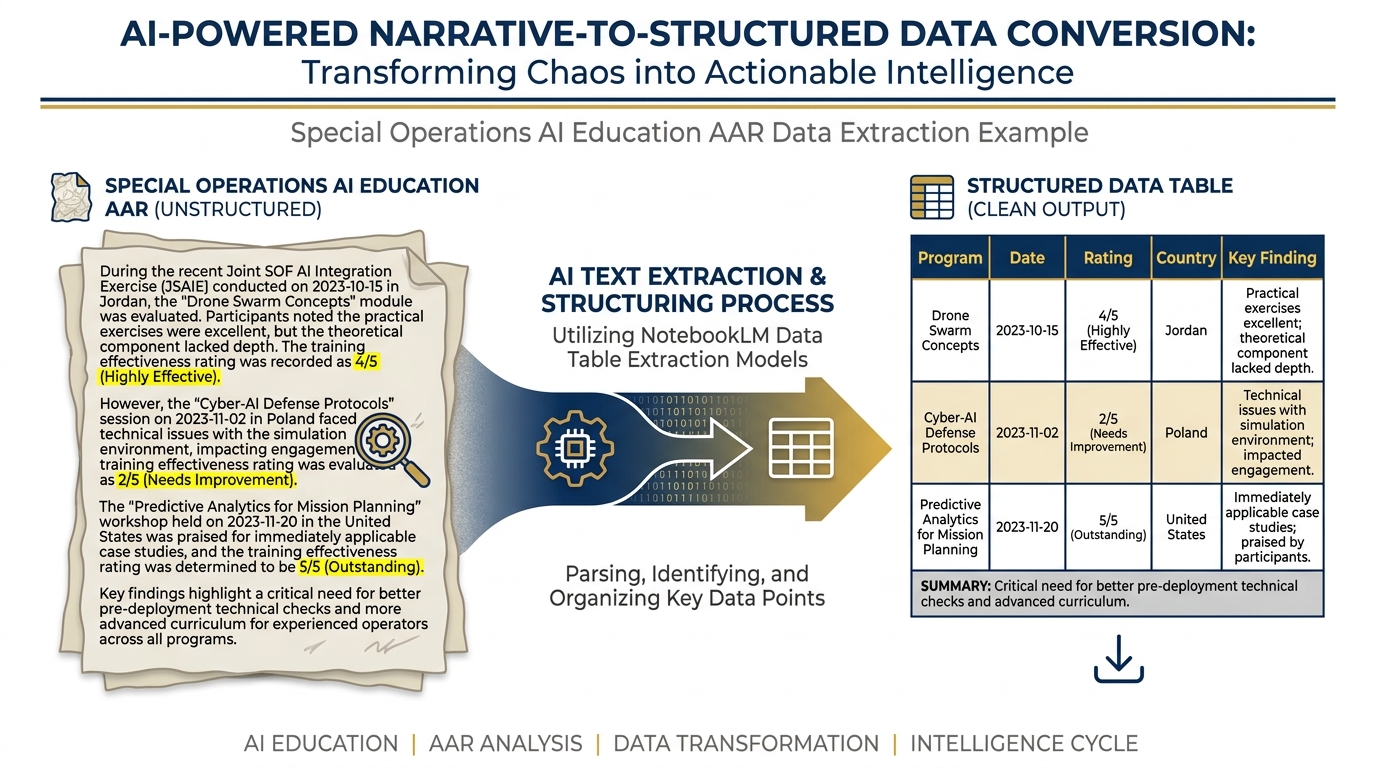
Figure 7:Data Table extraction. Narrative AARs contain structured data buried in prose — training effectiveness ratings, program names, dates, locations. NotebookLM’s Data Table output surfaces that structure. Review and verify the output; it will get you most of the way there. (as of April 2026)
The Lukos use case: You have thirty AARs, each mentioning training effectiveness ratings in narrative text. Generate a Data Table. NotebookLM attempts to extract the structured information. Review and verify the output — it won’t be perfect, but it will get you most of the way there.
Video Overviews — Visual Briefings from Your Corpus¶
What it is: Similar to Audio Overviews but with an accompanying visual presentation layer. NotebookLM generates a narrated video-style briefing from your document corpus.
The Lukos use case: When your audience needs a visual format for self-service consumption — a Video Overview can serve as an asynchronous briefing product that combines the accessibility of audio with a visual display.
Reports — Long-Form Synthesis¶
What it is: A longer-form synthesis of your document corpus — similar to the Briefing Doc but with more depth, more structure, and more analysis.
The Lukos use case: End-of-cycle program synthesis. Upload all documents for a program year. Generate the Report. Use it as a first draft of the annual synthesis document. The analyst’s job becomes validation, correction, and enhancement — not writing from scratch.
64.6 RAG: The Why Behind the Wonder¶
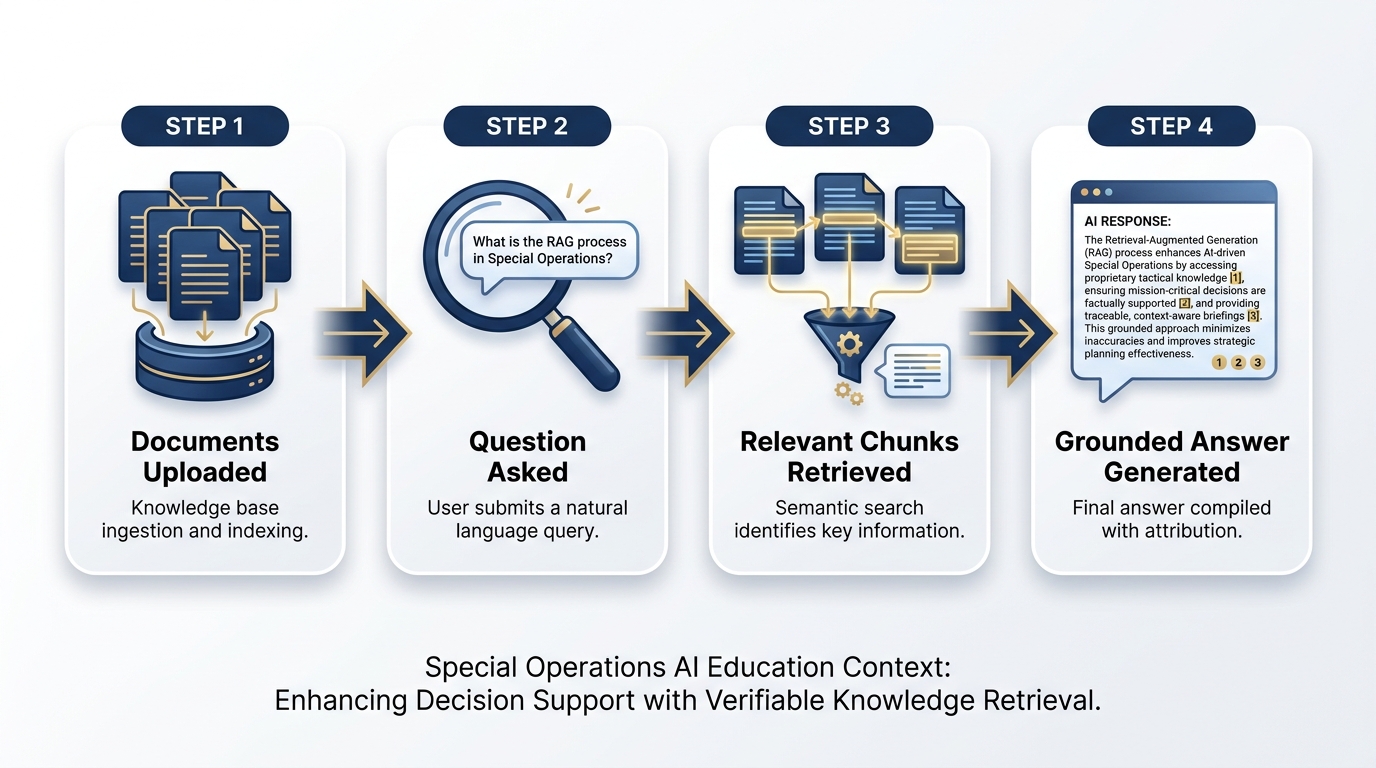
Figure 8:How RAG works. Your question retrieves relevant passages from your sources. Those passages ground the model’s answer. Every claim traces back to a specific document. That’s RAG — and it’s why NotebookLM cannot hallucinate about your documents.
Let me explain the technology behind what NotebookLM does — without making it technical.
Here is the analogy.
Imagine a brilliant analyst sits down at a desk. In front of them is a stack of thirty AARs. You ask: “What are the recurring gaps in C2 coordination?” The analyst does not stare out the window and make up an answer from general knowledge. They read through the stack, marking relevant passages with sticky notes, and when they answer, they hand you the answer plus the sticky notes. You can verify every claim.
Now imagine this analyst can read all thirty documents in milliseconds. Can simultaneously compare passages across all sources. Can spot thematic patterns that would take a human a week to see. And will always cite — never once will they say something that isn’t on a sticky note.
That is RAG. That is NotebookLM.
RAG stands for Retrieval-Augmented Generation. Here’s what actually happens when you ask NotebookLM a question:
Indexing: When you upload your sources, NotebookLM breaks them into chunks and creates a searchable index — think of it as reading all the documents and creating a card catalog at superhuman speed.
Retrieval: When you ask a question, the system first retrieves the most relevant chunks from your source documents — the passages most likely to contain the answer.
Grounded Generation: The AI model (Gemini, under the hood) then generates an answer using only those retrieved passages as its reference material. The citations you see are the passages it retrieved.
Because the model is constrained to retrieved passages from your sources, it cannot fabricate information. If the information isn’t in the retrieved passages, the model has nothing to generate from. It says: “I don’t see this addressed in the provided sources.”
The Lessons Learned Structural Insight¶
Here is the insight that should make every Lessons Learned practitioner sit up straighter:
The Lessons Learned mission is, structurally, a RAG problem.
What does a Lessons Learned program do? It collects observations from operations and exercises. It codes and organizes them. It stores them in a corpus. And when a new question arises — “What do we know about this type of challenge?” — someone queries that corpus and synthesizes an answer.
That is retrieval-augmented generation. It’s what you’ve been doing by hand for twenty years. NotebookLM is the same mission, running at machine speed.
74.7 The Limits of RAG — What NotebookLM Cannot Do¶
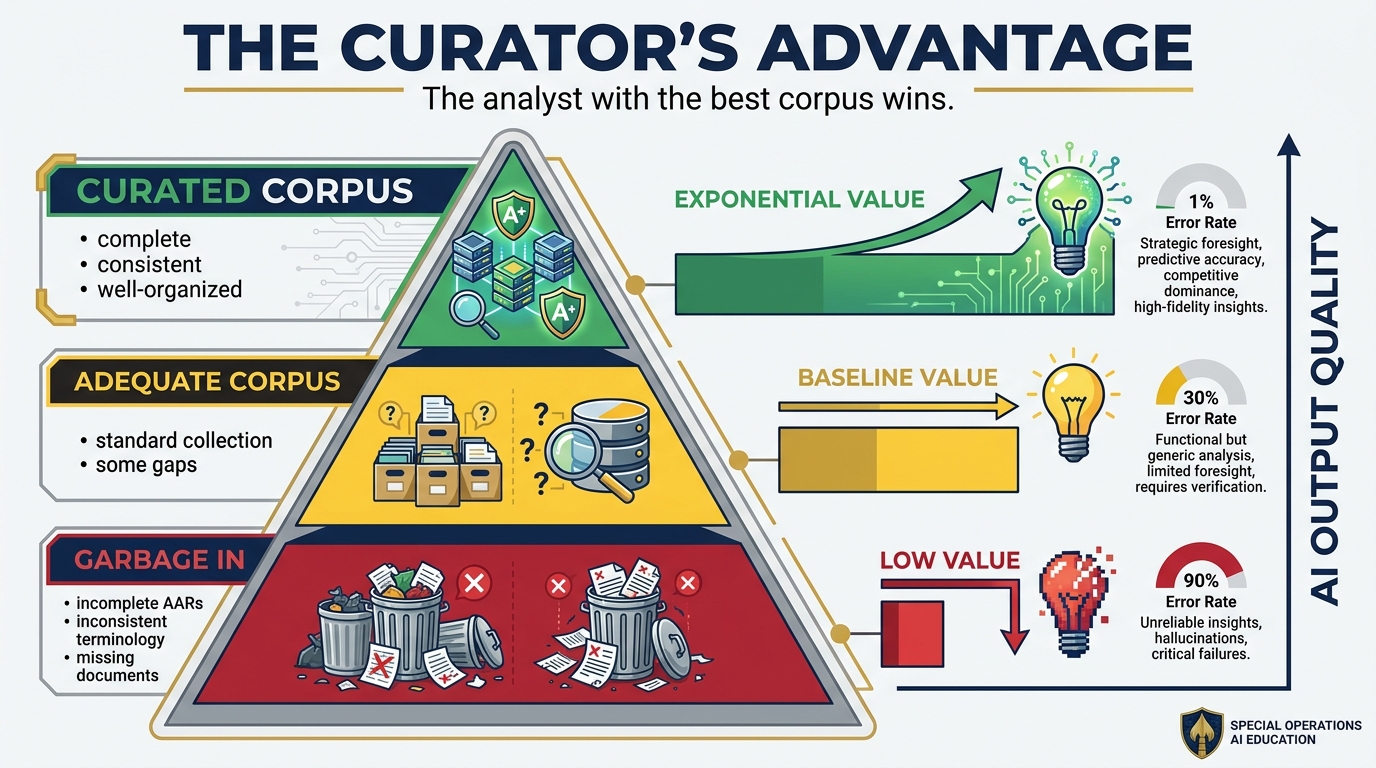
Figure 9:The Curator’s Advantage. AI output quality scales with corpus quality — not linearly, but exponentially. The analyst who maintains a clean, complete, well-organized document corpus gets dramatically more value from NotebookLM than one who uploads whatever is at hand. Source discipline is a competitive advantage.
Understanding the limits of any tool is how you use it well. Here is what NotebookLM cannot do — and what that means strategically for Lukos.
Garbage In, Garbage Out — At AI Speed¶
NotebookLM is only as smart as its sources. If your AARs are poorly written, use inconsistent terminology, or omit key information, NotebookLM will faithfully synthesize those limitations at scale. Bad sources produce bad answers.
More importantly: missing sources produce missing answers. If the twelve most insightful AARs from the last two years aren’t in the notebook, the analysis will miss twelve data points. The model cannot tell you about documents it doesn’t have.
This is a familiar problem in the Lessons Learned world. The challenge has always been collection completeness — getting every significant event reported, coded, and into the database. AI doesn’t change that problem. It amplifies it. A well-curated corpus becomes dramatically more valuable. A poorly curated corpus produces confident-sounding but incomplete analysis.
The Strategic Implication¶
This is perhaps the most important strategic insight in this chapter:
In an AI-assisted Lessons Learned environment, corpus curation is a competitive differentiator.
The analyst who spends time maintaining a clean, well-organized, complete document corpus will get exponentially more value from NotebookLM than the analyst who uploads whatever they can find quickly. The organization that has maintained rigorous collection discipline for years has a corpus that becomes a strategic asset when you put an AI research layer on top of it.
The Lukos competitive advantage is not using NotebookLM. Every contractor with a Google account can use NotebookLM. The advantage is having a better-curated corpus than anyone else — and then using NotebookLM to query it.
Other Limits to Know¶
No live data: Sources are indexed at upload time. If you add a URL, NotebookLM fetches it once and doesn’t update. For rapidly evolving topics, you need to re-add updated sources.
No mid-session source updates: If you upload a new source while a session is active, ask NotebookLM to re-orient to the new source before querying across the full notebook.
No classified access: NotebookLM is an unclassified cloud tool. Classification discipline belongs with you. Export to unclassified before uploading.
50-source limit on free tier: For large corpora, you need Google AI Pro. See Section 4.3.
Source quality matters: Scanned PDFs with poor OCR quality produce lower-fidelity indexing. Where possible, use text-searchable PDFs.
84.8 The Audio Overview as a Force Multiplier¶
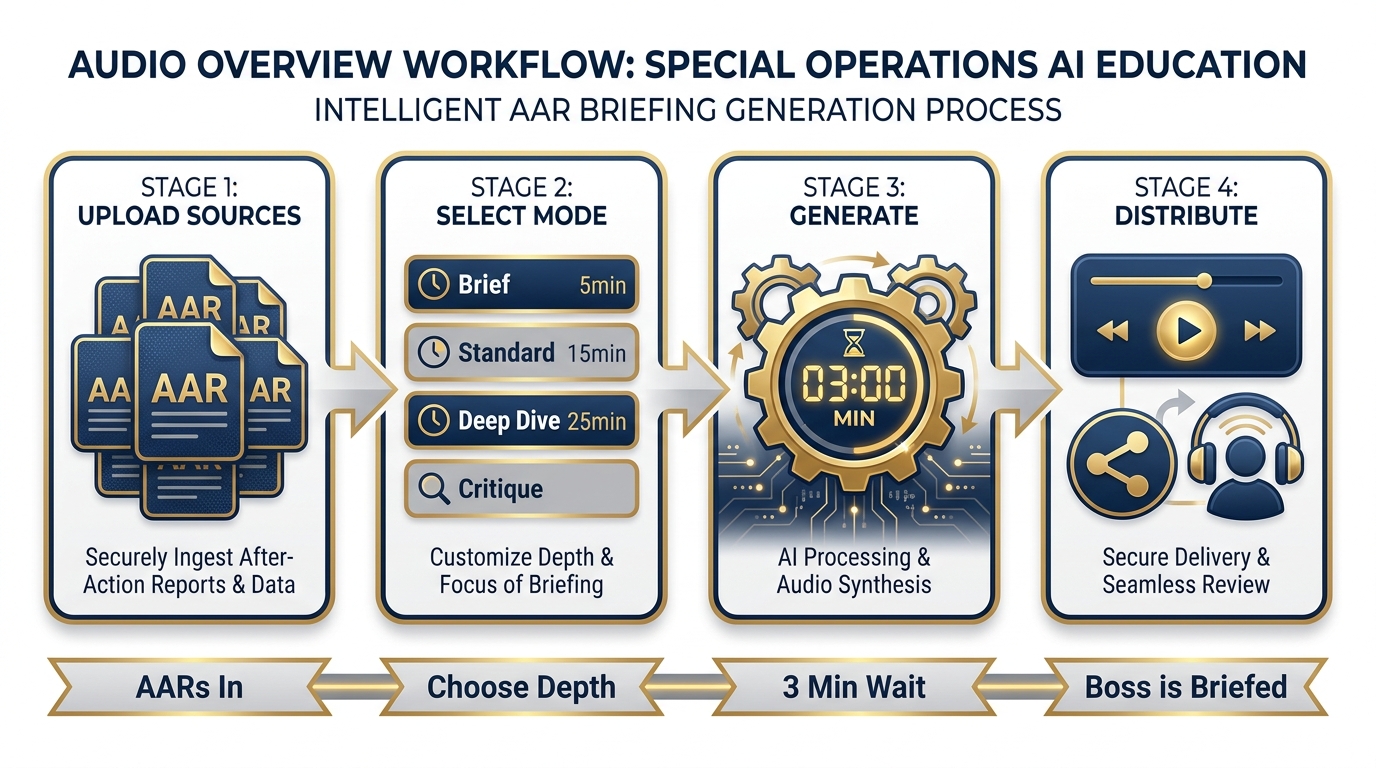
Figure 10:The Audio Overview workflow. Upload your sources, select your mode, generate, and distribute. The Deep Dive transforms a document corpus into a 25-minute briefing your senior leader can listen to on the commute in. Critique mode provides free red-teaming for any analytical product.
Of all the Studio outputs, Audio Overviews deserve their own section. Not because they’re technically the most sophisticated — the RAG architecture is — but because they change the distribution pattern for intelligence products. And that changes everything.
The 17-Minute Commute Briefing¶
Here’s the problem that Audio Overviews solve.
You’ve done excellent analysis. You have a synthesis document that captures the key findings from the last quarter’s JCET program — thirty pages of carefully structured, cited analysis. Your senior leader needs to understand the main themes before the working group next week.
They will not read thirty pages. Not because they’re not dedicated — they’re incredibly dedicated. But they’re managing twelve active programs, fielding calls from J7 counterparts, and preparing for their own briefings. They will skim it in the car or not get to it at all.
Now consider this alternative: you send them a seventeen-minute Deep Dive Audio Overview. They plug in their earbuds on the drive in. Two professional-sounding voices discuss the key findings from YOUR analysis — your specific programs, your specific data, your specific language — in a natural, engaging conversation. By the time they walk into the building, they’re briefed.
That is a fundamentally different distribution pattern for intelligence products. And it is available in three clicks.
The “Send the Boss a Podcast” Workflow¶
Here is the exact process:
Step 1: Build your NotebookLM notebook with the source documents for the briefing topic. For a program review, this might be: the quarterly AARs, relevant doctrine references, your own analysis document, and any previous briefing materials.
Step 2: In the Studio panel, click “Audio Overview”, select “Deep Dive”, and click “Generate”. It will take 3–5 minutes. Go review the sources or draft your agenda for the working group.
Step 3: When the Audio Overview is ready, click the “Share” button on the audio player. NotebookLM generates a shareable link. Send that link to your senior leader with a single line of context: “15-minute briefing on Q2 JCET findings — covers the main themes and the top three action items.”
Step 4: They click the link. They press play. They’re briefed.
Step 5 (optional but powerful): Also share the notebook itself. Now they can ask follow-up questions in the Chat panel — grounded, cited answers from the same sources the audio was generated from. The briefing has a built-in research capability attached to it.
Critique Mode — Free Red-Teaming for Any Document¶
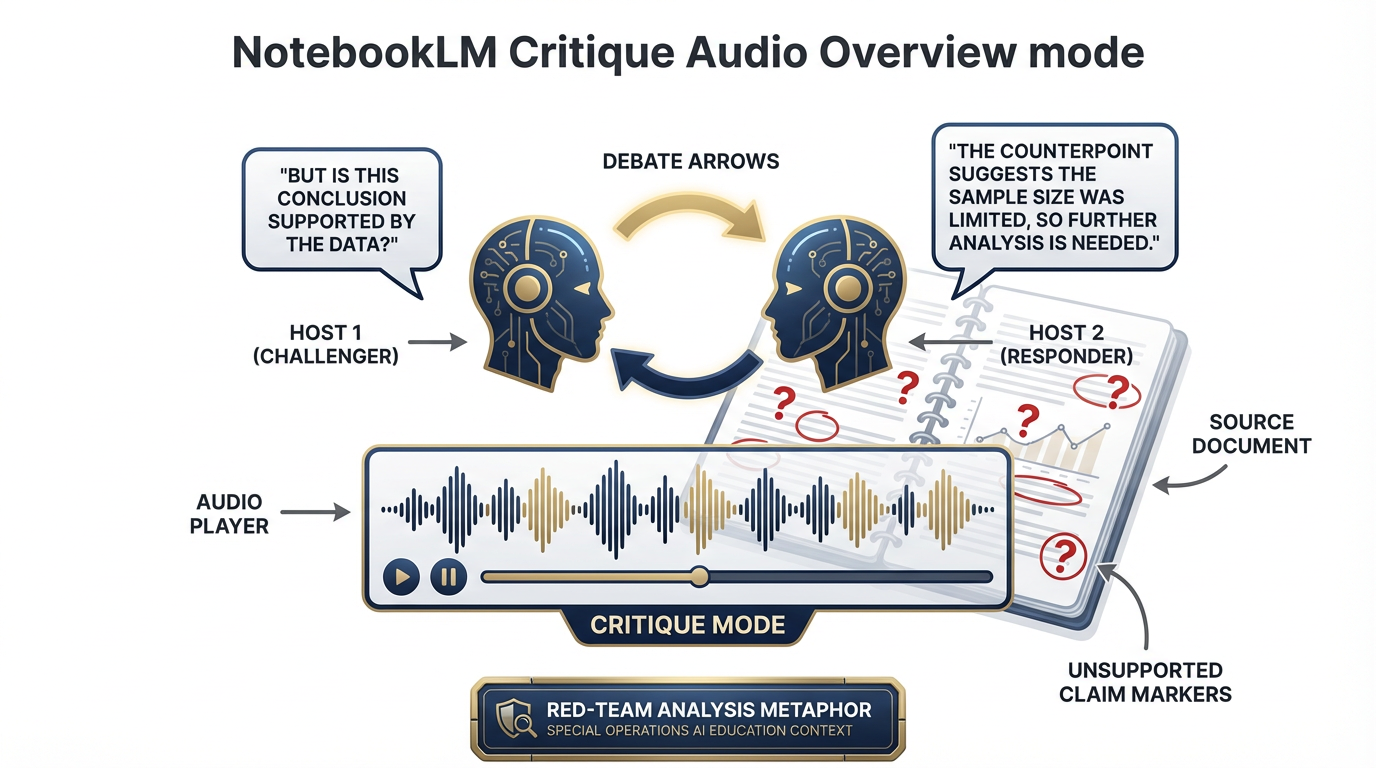
Figure 11:Critique Mode: free red-teaming. Select Critique when generating an Audio Overview and the two AI hosts actively challenge the claims in your document — surfacing unsupported assertions, alternative interpretations, and logical gaps. Run Critique on any draft deliverable before it goes to the customer. (as of April 2026)
Here is a feature that almost nobody discovers on their own, and it is worth the price of admission alone.
Generate a Critique Audio Overview from your own analysis document.
What happens: the two AI hosts read your document — your conclusions, your recommendations, your synthesis — and then actively challenge it. They identify unsupported claims. They surface alternative interpretations. They ask the questions a skeptical reviewer would ask. They push back on the logic.
This is a free red-team for any analytical product.
Before you send a significant deliverable to the customer, put it in a NotebookLM notebook and generate a Critique Overview. Listen for the objections. If the AI can identify a weak claim or a logical gap, so can your program manager, your J7 counterpart, or your contracting officer. Fix the gaps before the brief.
This workflow transforms the quality control process. Instead of hoping a colleague has time to red-team your document, you get a structured critique in five minutes.
Accessibility: The Overlooked Dividend¶
Audio Overviews have value beyond the briefing pattern. Consider:
Analysts with reading difficulties can engage with large document corpora through listening rather than reading. The same analysis, the same intelligence product — without the reading burden.
Senior leaders who learn aurally — there are many of them — get better retention from a well-produced audio discussion than from a thirty-page report.
Foreign partner engagements where English is a second language: an audio discussion of key findings, at a natural speaking pace, is more accessible than dense written English.
Long transit environments: Analysts and program managers who spend hours on aircraft or in vehicles can convert that time into professional development or mission preparation.
Audio Overviews are not a convenience feature. They are an accessibility and distribution force multiplier.
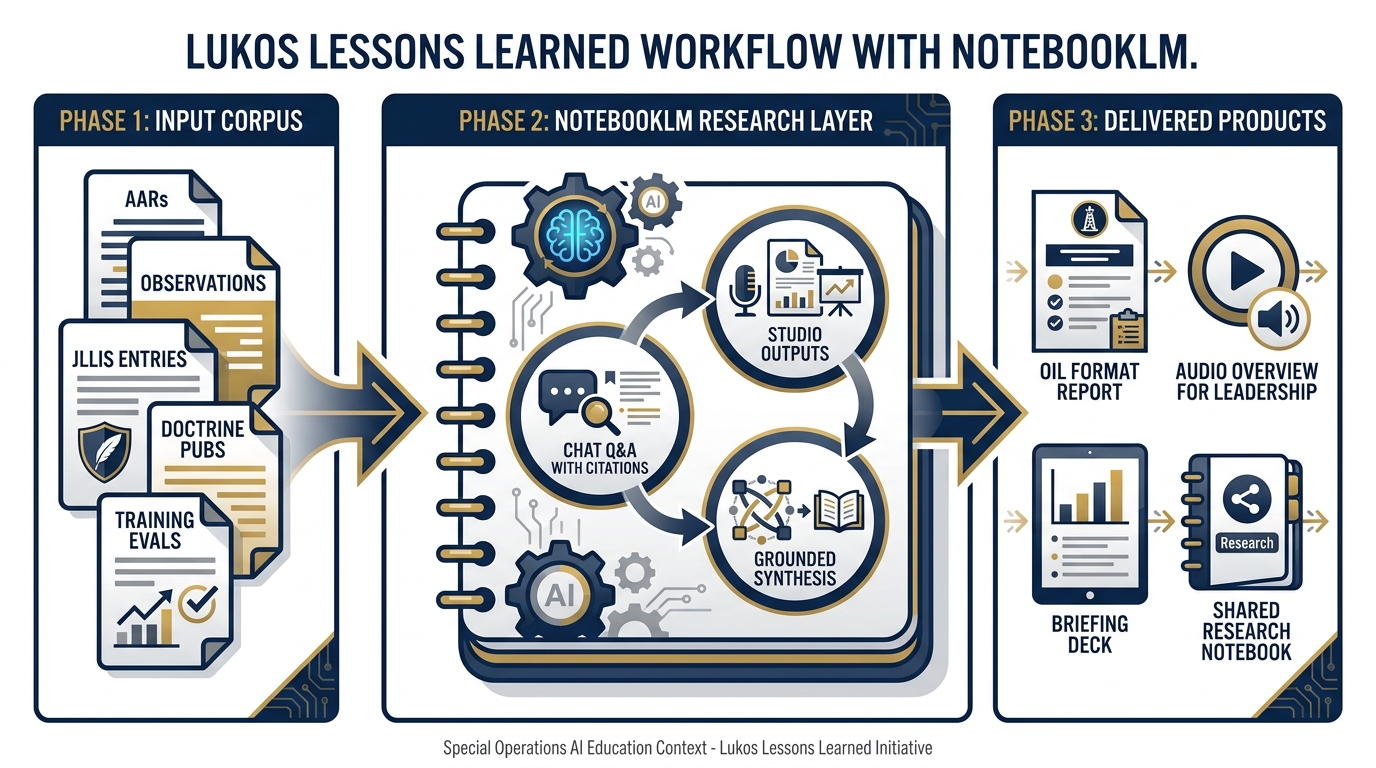
Figure 12:The full Lukos LL workflow. From raw AARs to OIL-formatted outputs — NotebookLM sits between the corpus and the product, multiplying the analyst’s reach without replacing their judgment.
94.9 Putting It All Together: The NotebookLM-Powered Research Workflow¶
Before the hands-on labs, let’s see the full workflow as a single operational picture.
The Setup Phase (once per project):
Identify the research question or deliverable
Curate the relevant document corpus — AARs, doctrine, previous analysis, relevant references
Create a named NotebookLM notebook for the project
Upload all sources (10–20 minutes for a typical program review set)
Generate the Mind Map to orient to the corpus structure
The Analysis Phase (recurring):
Use the Chat panel to ask research questions — specific, targeted queries
Validate citations — click every cited claim and confirm it holds
Ask follow-up questions to drill into emerging themes
Generate the Briefing Doc for an integrated synthesis view
The Production Phase (per deliverable):
Generate the Audio Overview (Deep Dive or Standard depending on audience)
Generate the Slide Deck outline for presentations
Generate the Report for written deliverables
Run Critique mode on the draft deliverable before distribution
Share the notebook link with stakeholders for self-service follow-up queries
The Distribution Phase:
Send the Audio Overview link to leadership for pre-brief orientation
Distribute the written deliverable with citations intact
Provide the shared notebook as a living reference for program stakeholders
This is what a NotebookLM-powered research practice looks like. The analyst is still doing the judgment work — validating, contextualizing, deciding what matters. The AI is handling the extraction, retrieval, synthesis, and formatting that previously consumed 80% of the timeline.
104.10 Hands-On Labs¶
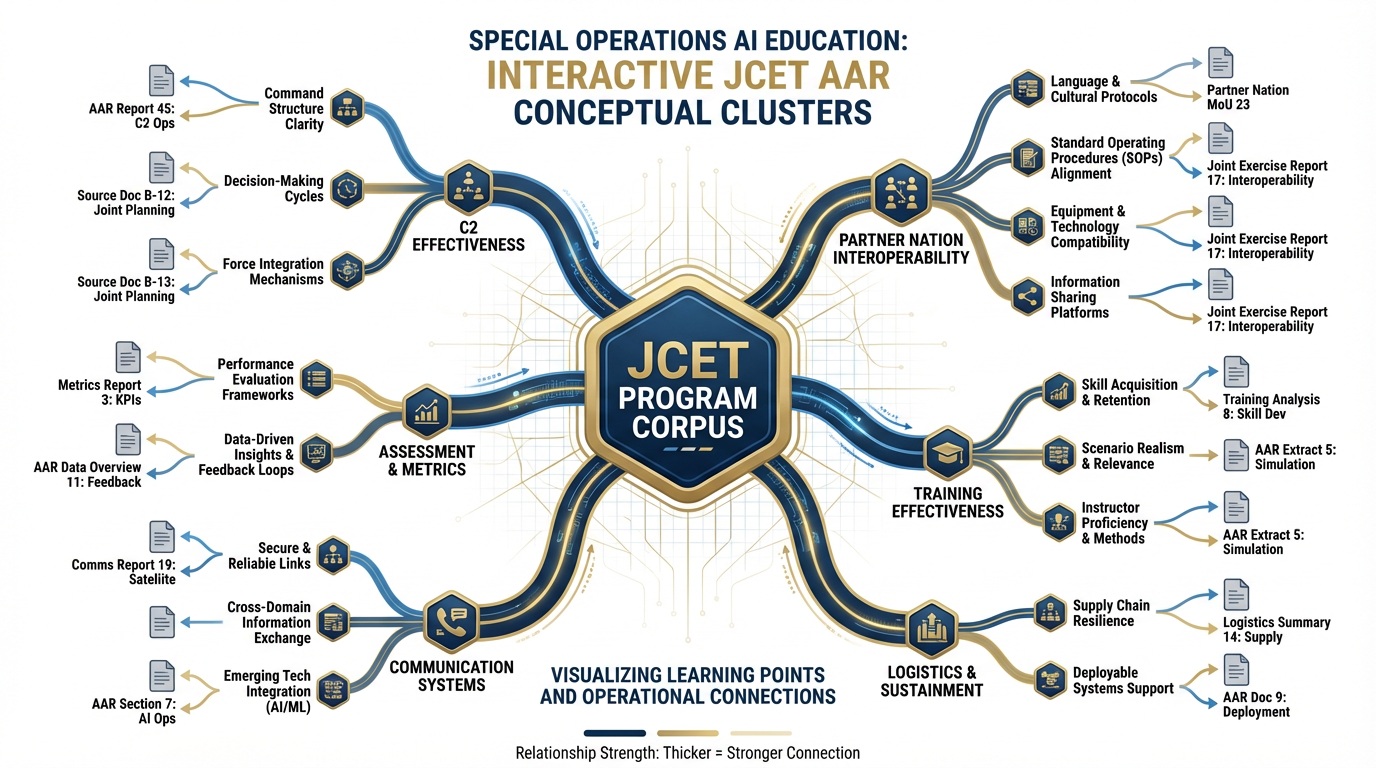
Figure 13:The mind map in action. Conceptual clusters from an AAR corpus — visible at a glance, before reading a single document. Each node is clickable and links back to source material.
By this point in the course, you’ve worked with Gemini in Chapter 2 and explored AI Studio in Chapter 3. This chapter marks a shift: you’re no longer just prompting a general AI. You’re building a grounded research system from your own documents. These labs are designed to produce outputs you’ll actually use after today.
Group Lab: The Lukos Training Notebook¶
Work through all three tiers as a group. A facilitator drives; everyone follows along on their own device.
Tier 1 — The On-Ramp (5 min)¶
Objective: Experience a cited answer for the first time.
Step 1: Open notebooklm
Step 2: Click “Create new notebook”. Name it “Lukos Training — Chapter 4”.
Step 3: In the Sources panel, click “+” → “Website”. Enter this URL exactly:
https://www.jcs.mil/Portals/36/Documents/Doctrine/pubs/jp3_0.pdf(This is Joint Publication 3-0: Joint Operations — a publicly available doctrine publication from the Joint Chiefs of Staff.)
Wait 30–60 seconds for the source to be ingested and indexed. You’ll see a source card appear in the Sources panel when it’s ready.
Step 4: In the Chat panel, type exactly:
What does JP 3-0 say about the role of joint intelligence in shaping the operational environment? Provide specific citations.Step 5: Read the response. Identify the inline citation (it will appear as a blue number like [1] or as a source reference). Click the citation.
Step 6: You are now looking at the exact passage from JP 3-0 that supported the claim. Read the paragraph. Confirm the AI’s characterization is accurate.
✅ Success looks like: A Chat response with at least one inline citation marker (blue number or source reference). You click it. NotebookLM highlights the exact passage in the source document. The AI’s claim matches what the document says.
Tier 2 — The Core Rep (15 min)¶
Objective: Build a multi-source notebook and generate a Briefing Doc.
Step 1: With your “Lukos Training — Chapter 4” notebook still open, add three more sources. In the Sources panel, click “+” for each:
Source 2 — Website:
https://www.jcs.mil/Portals/36/Documents/Doctrine/pubs/jp3_20.pdf(JP 3-20: Security Cooperation)
Source 3 — Website:
https://www.jcs.mil/Portals/36/Documents/Doctrine/pubs/jp3_05.pdf(JP 3-05: Special Operations)
Source 4 — Pasted text: Click “+” → “Copied text”. Paste the following text block and title it “Lukos LL Context”:
Lukos LLC provides Lessons Learned support to USSOCOM and its component
commands. Core services include: after-action review facilitation, lessons
learned collection and coding, JLLIS database management, training support,
and analytical products for program offices and J-code directorates.
The Lukos corpus includes over 45,000 individual lesson observations
spanning exercises, operations, and institutional programs.Wait for all four sources to be indexed (you’ll see all four source cards in the Sources panel).
Step 2: Ask these five questions in sequence in the Chat panel. Copy each one exactly:
Question 1:
What does JP 3-05 say about the purpose and conduct of Joint Combined Exchange Training (JCET)?Question 2:
How does JP 3-20 define security cooperation, and what does it identify as key success factors?Question 3:
What connections can you draw between the joint intelligence concepts in JP 3-0 and the security cooperation framework in JP 3-20?Question 4:
Based on all sources, what are the top three challenges in building partner nation capability that these doctrine publications identify?Question 5:
Given the Lukos context and the doctrine in this notebook, what research questions should a Lessons Learned analyst prioritize when evaluating a JCET program?Notice how Questions 3 and 4 synthesize across multiple sources — the answer draws from all four documents simultaneously.
Step 3: Go to the Studio panel. Click “Briefing Doc” → “Generate”. Wait 30–60 seconds.
Step 4: Read the Briefing Doc. It is a 1–2 page synthesis of all four sources. Identify at least one insight in the Briefing Doc that didn’t come up in your Chat questions.
✅ Success looks like: A generated Briefing Doc in the Studio panel that synthesizes all four sources with citations. At least one of the Chat responses cites multiple sources in the same answer.
Tier 3 — The Wow Moment (25 min)¶
Objective: Generate the Audio Overview and Mind Map. Experience what “talking to your documents” sounds like.
Step 1: In the Studio panel, click “Audio Overview” → select “Deep Dive” → click “Generate”.
Step 2: While the Audio Overview generates (this takes 2–4 minutes), click “Mind Map” → “Generate”. Let both process simultaneously.
Step 3: When the Mind Map finishes first: explore it. You should see a central node representing the notebook’s core topic, with branches showing conceptual clusters from across your four sources. Click three nodes and read what sources they connect to.
Step 4: When the Audio Overview finishes: press play. Listen to the first three minutes.
This is the moment.
Two AI voices are discussing the doctrine documents you added — joint intelligence, security cooperation, special operations — in a natural, back-and-forth conversation. They mention specific concepts from the specific documents you uploaded. They make connections. They ask each other clarifying questions. This is a podcast episode about YOUR research notebook.
Let that land. This is content you generated from your own document corpus in under ten minutes.
Step 5: Pause the audio. Turn to the person next to you and describe one thing you heard in those three minutes that you would not have thought to include in a traditional briefing summary.
Step 6: Return to the Mind Map. Identify three conceptual clusters that you did not consciously note when you were adding the sources. Write them down. These are the patterns the AI detected that you would have needed to read carefully to find manually.
✅ Success looks like: A playable Audio Overview with two distinct AI voices discussing your specific document content. A Mind Map with at least five distinct node clusters. Three conceptual clusters identified that weren’t obvious before the Mind Map.
Individual Lab: Your Personal Analyst’s Desk Reference¶
Complete these tiers on your own, using documents from your own work or the provided public sources. You are building a notebook you’ll actually use after today.
Tier 1 — Your First Grounded Question (5 min)¶
Step 1: Go to notebooklm
Step 2: Add one source:
If you have a work document you can add (an AAR, a training plan, a program description, any unclassified document): upload it as a PDF or paste the text
If not: use this URL:
https://www.jcs.mil/Portals/36/Documents/Doctrine/pubs/jp3_05.pdf
Step 3: Ask one question about the document. Make it specific to something you’d actually want to know. Example for JP 3-05:
What does this document say about the role of Civil Affairs in special operations? Provide citations.Step 4: Click the citation in the response. Land on the source paragraph.
✅ Success looks like: A cited answer. A clicked citation. A source paragraph confirmed. You’ve just done what analysts used to do manually in minutes instead of hours.
Tier 2 — Building Your Desk Reference (15 min)¶
Step 1: Add five more sources to your notebook. Use any combination of:
Your own work documents (training plans, program references, SOPs)
Public doctrine: JP 3-0, JP 3-05, JP 3-20 (URLs from the Group Lab above)
Any public web page you regularly reference for your work
Step 2: Ask three questions that span multiple documents:
Cross-document question 1:
What common themes appear across all the sources in this notebook related to [your specific topic area]?Cross-document question 2:
Which source provides the most detailed guidance on [specific subtopic]? Summarize that guidance with citations.Cross-document question 3:
What gaps exist in the sources in this notebook — what important questions are NOT addressed by any of these documents?Note how the third question tests the limits of the notebook — NotebookLM should identify what’s not there.
Step 3: Review the citations in all three responses. Click at least three citations and verify them against the source text.
Tier 3 — The Shareable Research Assistant (25 min)¶
Step 1: In the Studio panel of your personal notebook, click “Study Guide” → “Generate”.
Step 2: Read the generated Study Guide. It will contain: key concepts from your corpus, important passages, suggested discussion questions, and organized learning objectives. This is the AI’s view of what’s most important to understand from your document set.
Step 3: Consider: does this match your own understanding of the priorities in this corpus? Where does the AI’s prioritization differ from yours? Note any discrepancies — they’re worth examining.
Step 4: Now share your notebook. Click the “Share” icon in the upper right. Set the permission to “Viewer” (they can chat but not add sources). Copy the link.
Step 5: Send the link to one colleague — a teammate, a peer from another program, or the person next to you. Ask them to open the link and ask one question in the Chat panel about your notebook’s content.
Step 6: Watch them receive a cited answer — grounded in your documents, not in general internet knowledge.
✅ Success looks like: A generated Study Guide that reflects the actual priorities in your document corpus. A shareable link that gives a colleague access to a research assistant built on your documents. You walk away with a notebook you will actually use.
11Chapter Summary: The Research Partner¶
NotebookLM is not a general-purpose AI. It is a specialized research partner for exactly the kind of work Lukos does.
The fundamental insight of this chapter:
Grounding beats hallucination. NotebookLM’s constraint to your sources is a feature, not a limitation. In professional Lessons Learned work, a cited answer you can verify beats a confident answer you cannot.
The Lessons Learned corpus is an asset. Years of AAR collection, coding, and maintenance produced a document corpus. NotebookLM gives that corpus a research interface. The work that seemed only theoretically valuable is now immediately queryable.
Audio Overviews change the distribution model. Senior leaders who won’t read thirty pages will listen to a seventeen-minute podcast. The same intelligence product, a fundamentally different delivery mechanism. Four modes: Brief, Standard, Deep Dive, and Critique.
Corpus curation is a competitive differentiator. The analyst with the better-organized document set gets exponentially more value from AI tools. Source discipline is not just good practice — it’s a strategic advantage.
RAG is the technology behind all of this. Your question retrieves relevant passages from your sources. Those passages ground the answer. The citations you see are the evidence trail. This is why NotebookLM cannot hallucinate about your documents.
Gemini 3.1 Pro is available for Google AI Pro and Ultra subscribers. Free tier users get an earlier Gemini model. The upgrade delivers meaningfully better synthesis on complex multi-document research. (as of April 2026)
The mission-critical question as you leave this chapter is not “how do I use NotebookLM?” You know that now. The question is: what should go in my first production notebook?
Start there. Pick the document set that represents a real research question you’re currently trying to answer. Upload it. Ask the questions you would normally have to read the entire corpus to answer.
The research partner is ready when you are.
NotebookLM is available at no cost with any Google account. Google AI Pro and Ultra plans unlock Gemini 3.1 Pro, 300 sources per notebook, and unlimited Audio Overviews. Enterprise deployment requires coordination with your organization’s Google Workspace administrator. Features described as of April 2026.