Chapter 6: AI Ethics, Bias & Digital Responsibility
Navigating Deepfakes, Algorithmic Bias, and the Quest for Trustworthy AI
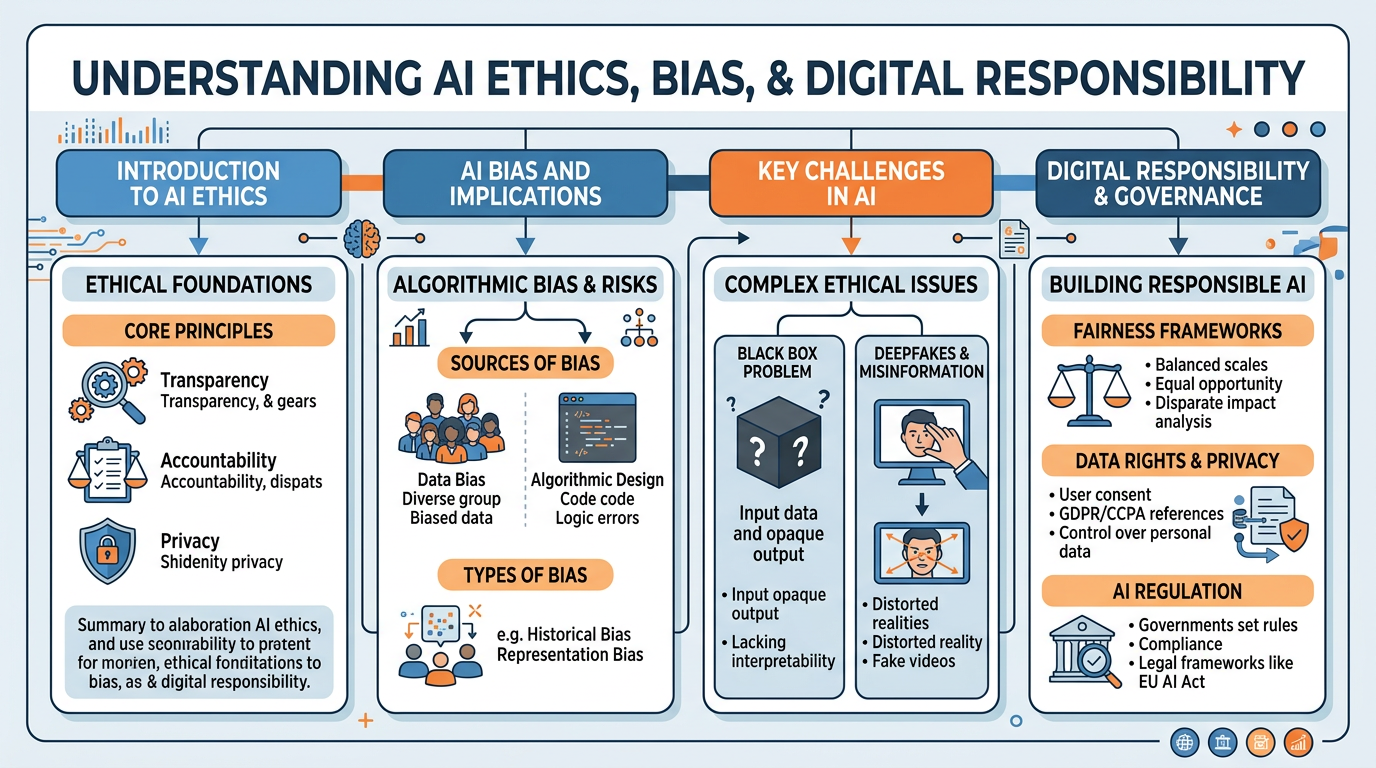
Figure 1:An illustrated overview of the critical ethical challenges in artificial intelligence — from deepfakes and algorithmic bias to data rights, regulation, and the pursuit of trustworthy AI.
“Learn to do right; seek justice. Defend the oppressed. Take up the cause of the fatherless; plead the case of the widow.”
Isaiah 1:17 (NIV)
On March 16, 2022, a video appeared on social media showing Ukrainian President Volodymyr Zelensky apparently telling his soldiers to surrender to Russian forces. The video was convincing — Zelensky’s face, his voice, his mannerisms — all seemed authentic. But the video was a deepfake: a synthetic media artifact generated by artificial intelligence to deceive. Within hours, fact-checkers identified telltale signs of manipulation, and the video was debunked. But in those hours, it was shared millions of times, and its potential to demoralize Ukrainian forces and mislead global audiences was very real.
This incident illustrates the central challenge of this chapter: artificial intelligence is not merely a neutral tool. It is a technology that amplifies human choices — both good and evil. The same AI that can diagnose cancer and translate languages can also create convincing lies, perpetuate discrimination at scale, and make life-altering decisions in ways that no one can explain or challenge.
For business students at a Christian university, this chapter is perhaps the most important in the entire course. The technologies we have studied — machine learning, natural language processing, computer vision — are powerful. But power without ethical guidance is dangerous. As Spider-Man’s Uncle Ben memorably stated, “With great power comes great responsibility.” Or, as Jesus himself taught in Luke 12:48, “From everyone who has been given much, much will be demanded.”
This chapter equips you with the frameworks, case studies, and biblical principles necessary to be not just competent AI professionals, but responsible ones — leaders who insist that AI serves human flourishing rather than undermining it.
1Deepfakes and Synthetic Media¶
1.1What Are Deepfakes?¶
Deepfake technology has advanced with alarming speed. What began as a novelty on internet forums in 2017 has evolved into a sophisticated capability that can:
Swap faces in video, placing one person’s face onto another’s body with seamless precision
Clone voices from just a few seconds of audio, generating speech in anyone’s voice saying anything
Generate entirely synthetic people who have never existed — complete with realistic faces, expressions, and mannerisms
Manipulate existing footage by altering facial expressions, lip movements, or body language to change what a person appears to say or do
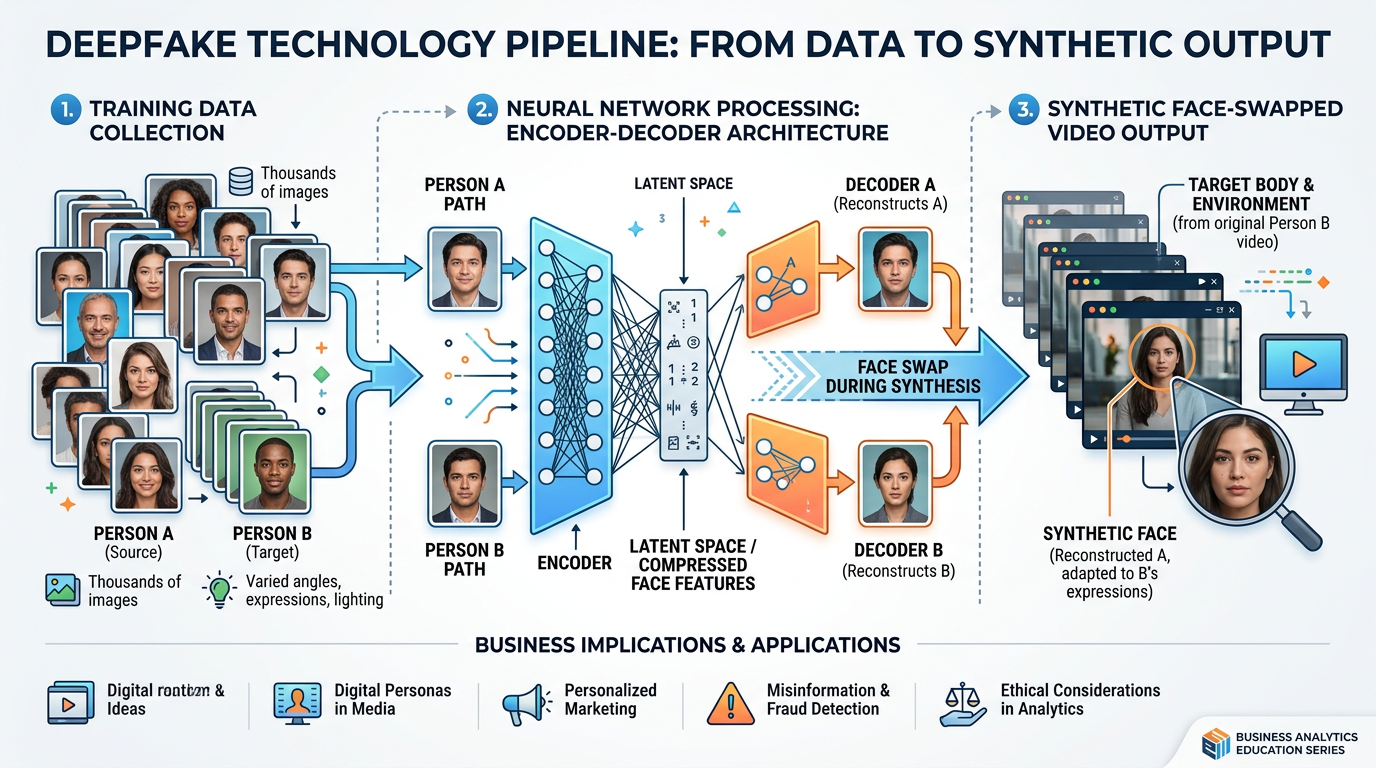
Figure 2:The deepfake creation pipeline: AI models learn facial features, expressions, and voice patterns from training data, then generate synthetic media that is increasingly difficult to distinguish from reality.
1.2The Scale of the Deepfake Threat¶
The numbers are staggering and accelerating:
Table 1:Deepfake Statistics
| Metric | 2019 | 2023 | Trend |
|---|---|---|---|
| Deepfake videos detected online | 14,678 | 500,000+ | 34x increase |
| Time to create a convincing deepfake | Hours | Minutes | Democratized |
| Cost to create | $1,000+ (specialized) | Free (open-source tools) | Commoditized |
| Detection accuracy (best tools) | 95% | 65-80% | Declining as fakes improve |
| Deepfake fraud losses (business) | $50M | $600M+ | Exponential growth |
1.3Categories of Deepfake Harm¶
Deepfakes of political leaders making false statements can influence elections, incite violence, and undermine democratic processes. The Zelensky deepfake is one of many examples. During election cycles, deepfake robocalls, fabricated endorsements, and manipulated debate footage pose serious threats to informed democratic participation.
Deepfake voice cloning enables CEO fraud — criminals impersonate executives to authorize fraudulent transfers. Deepfake video calls create false meetings. Synthetic identities enable loan fraud and identity theft at scale. Losses are measured in billions globally.
Non-consensual deepfake pornography accounts for over 90% of all deepfake content online, disproportionately targeting women. Deepfake harassment, impersonation, and reputation destruction cause devastating personal harm with limited legal recourse in many jurisdictions.
Deepfakes blur the line between reality and fiction, creating an “information apocalypse” where any video, audio, or image can be questioned. Paradoxically, the existence of deepfake technology allows real evidence to be dismissed as “probably fake” — a phenomenon called the “liar’s dividend.”
1.4Detecting and Combating Deepfakes¶
The battle between deepfake creation and detection is an ongoing arms race. Current detection approaches include:
2Fake News, Misinformation, and AI¶
2.1The AI Misinformation Ecosystem¶
AI has supercharged the creation and distribution of false information. Understanding the vocabulary is essential:
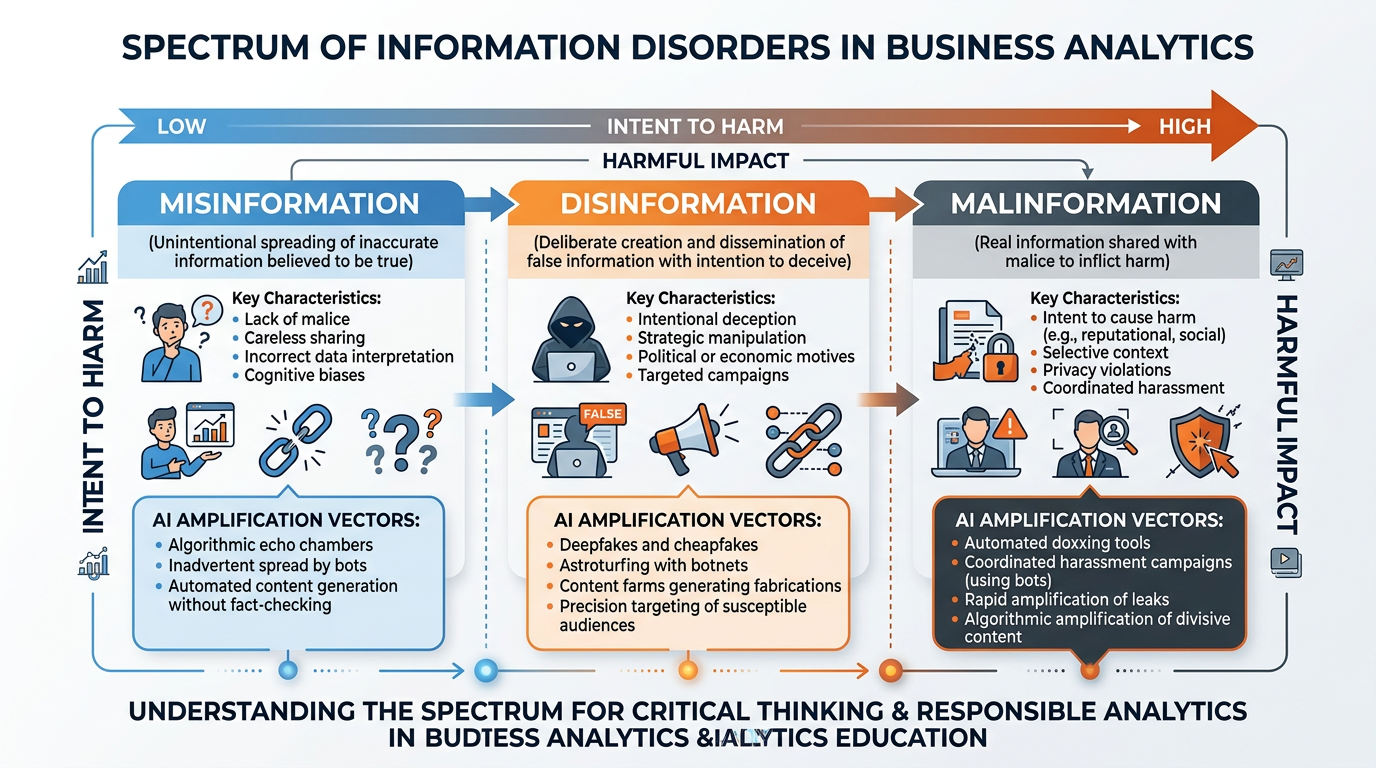
Figure 3:The information disorder spectrum: from unintentional misinformation through deliberate disinformation to weaponized malinformation — and how AI amplifies each category.
Definition: False information shared without the intent to deceive. The person sharing it believes it to be true.
AI amplification: LLMs can generate confident-sounding but factually incorrect statements (hallucinations). Users who trust AI outputs may unknowingly spread misinformation. Automated content creation allows misinformation to be produced at scale.
Example: A student uses ChatGPT to research a topic and includes AI-hallucinated statistics in a paper. Other students cite the paper, spreading the false data further.
Definition: False information deliberately created and shared with the intent to deceive, manipulate, or cause harm.
AI amplification: AI can generate thousands of unique disinformation articles, social media posts, and comments in minutes. Deepfakes create convincing false evidence. AI-powered bot networks amplify disinformation through fake engagement. Translation AI enables cross-border disinformation campaigns.
Example: A state-sponsored operation uses GPT-4 to generate thousands of unique social media posts promoting conspiracy theories, each written in a different style to avoid detection.
Definition: Genuine information shared with the intent to cause harm — such as leaking private data, taking true statements out of context, or weaponizing real footage.
AI amplification: AI can identify and target individuals’ vulnerabilities. Automated systems can weaponize real data (medical records, financial information) at scale. AI-powered doxing tools can aggregate and expose personal information.
Example: A competitor uses AI to analyze a CEO’s public speeches, identify potentially controversial quotes, strip them of context, and distribute them as attack content.
2.2AI-Generated Fake News at Scale¶
The ability of LLMs to generate human-quality text at speed and scale has created a new threat: AI-generated fake news that is nearly impossible to distinguish from human-written journalism.
Case Study: The Fake News Factory
In 2023, investigative journalists uncovered a network of over 600 websites publishing entirely AI-generated news content. These sites, operating across multiple countries and languages, generated thousands of articles daily on topics ranging from politics to health to finance. The articles were designed to attract search engine traffic and generate advertising revenue, but their content was fabricated — mixing real events with invented details, fake quotes, and AI-hallucinated statistics.
The operation required fewer than 10 human operators, who used AI to generate content, create fake author profiles (complete with AI-generated headshot photos), and manage the website network. The total cost was estimated at under $10,000 per month, while generating millions of page views and significant advertising revenue.
Business implications:
Brands whose ads appeared on these fake sites faced reputational damage
Legitimate news organizations lost advertising revenue to fake competitors
Decision-makers who relied on these articles made choices based on false information
SEO and content marketing strategies were disrupted by AI-generated spam
2.3The Epistemological Crisis¶
Perhaps the deepest threat posed by AI-generated content is not any specific piece of misinformation, but the erosion of our collective ability to determine what is true. When any text, image, audio, or video can be fabricated at low cost, how do we know what to believe?
3The Black Box Problem¶
3.1When AI Can’t Explain Itself¶
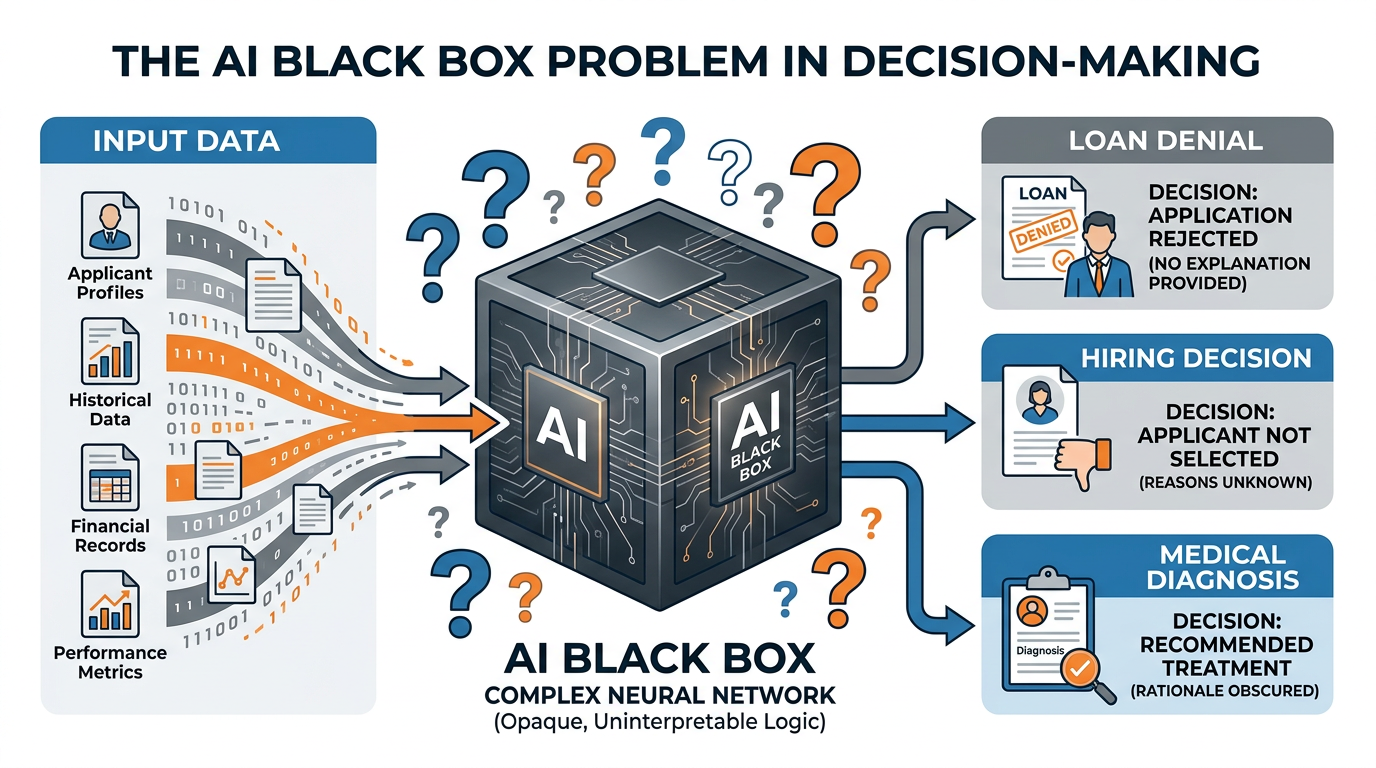
Figure 4:The black box problem: data goes in, decisions come out, but the reasoning process inside the AI model is opaque to human understanding — creating accountability challenges in high-stakes applications.
Consider these scenarios where the black box problem creates serious business and ethical challenges:
A bank’s AI system denies your mortgage application. When you ask why, the bank can only say “the algorithm determined you were high-risk.” The model considered hundreds of variables and their interactions — but no one can point to the specific reason. Was it your zip code? Your shopping habits? Your name?
The COMPAS algorithm, used in U.S. courts to predict recidivism risk, scores defendants on a scale that influences sentencing decisions. A ProPublica investigation found it was significantly biased against Black defendants. Yet the algorithm’s reasoning was opaque — judges relied on scores they couldn’t interrogate or challenge.
An AI system recommends against treating a patient — but the physician cannot understand why. Should the doctor follow the AI’s recommendation? What if the patient dies because treatment was withheld based on an unexplainable algorithmic assessment?
An AI hiring tool screens out 60% of applicants before a human ever sees their resume. Which factors drove the rejection? If the model learned that candidates from certain universities or with certain names are statistically less likely to succeed, it may be discriminating — but no one can tell.
3.2Explainable AI (XAI): Opening the Black Box¶
The field of Explainable AI (XAI) is working to address the black box problem by developing techniques that make AI decision-making more transparent and interpretable.
Key XAI approaches include:
Local Interpretable Model-Agnostic Explanations (LIME) explains individual predictions by creating a simplified, interpretable model around each specific decision. For a loan denial, LIME might reveal: “The three factors that most influenced this decision were: debt-to-income ratio (40% impact), length of credit history (30%), and number of recent credit inquiries (20%).”
SHapley Additive exPlanations (SHAP) uses game theory to determine the contribution of each input feature to a specific prediction. SHAP values can show exactly how much each factor pushed the prediction toward or away from a particular outcome.
For transformer models (like LLMs), attention maps show which parts of the input the model focused on most heavily when generating its output. This helps understand what the model considered most important, even if we can’t fully understand how it weighed those factors.
These explain decisions by describing what would need to change for a different outcome: “Your loan was denied. If your debt-to-income ratio were 5% lower OR your credit history were 2 years longer, the decision would have been approved.” This is often the most intuitive explanation for affected individuals.
4Algorithmic Bias: When AI Discriminates¶
4.1Understanding AI Bias¶
Algorithmic bias is not a bug to be fixed — it is a fundamental challenge inherent in using historical data to make future decisions. If the past was unfair, models trained on the past will perpetuate that unfairness unless deliberately designed to counteract it.
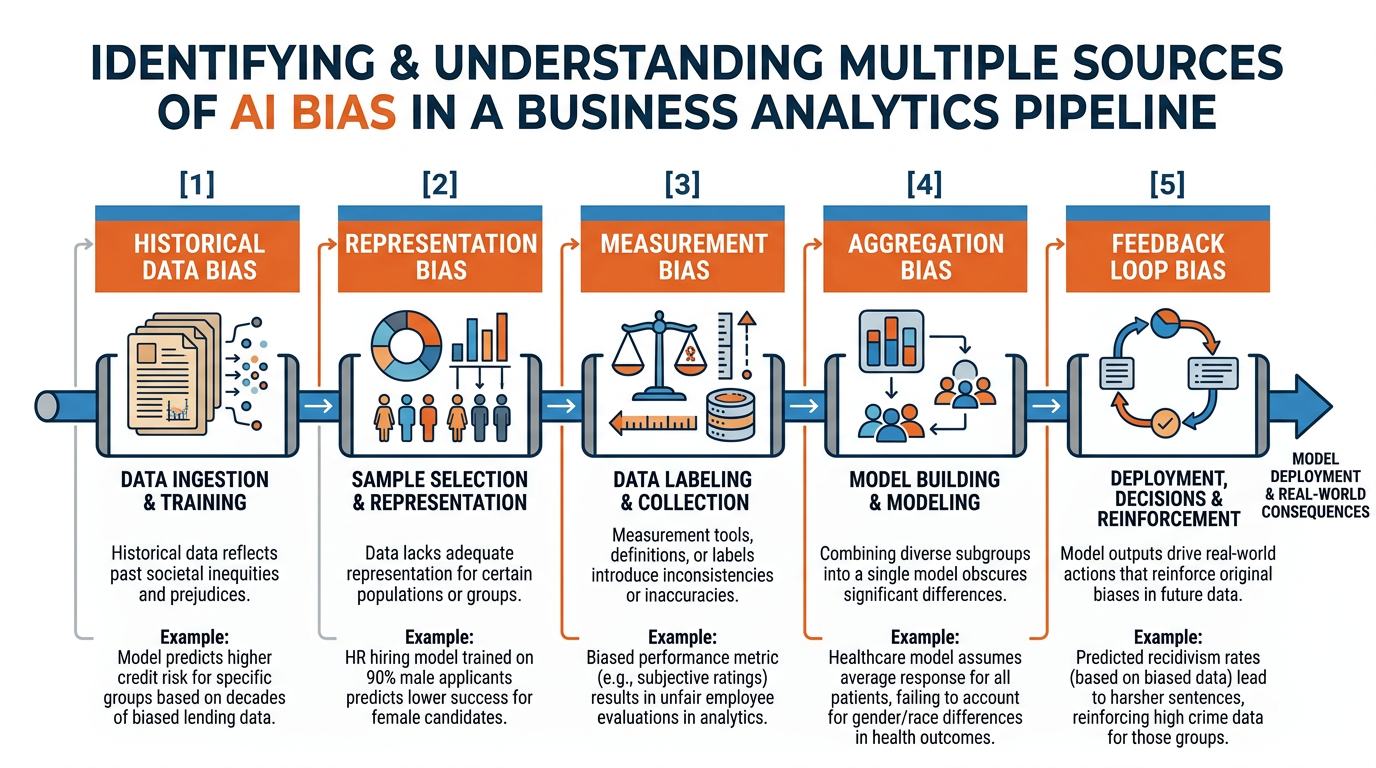
Figure 5:The multiple sources of algorithmic bias: unfairness can enter AI systems at every stage of the pipeline — from biased training data to flawed model design to discriminatory deployment contexts to self-reinforcing feedback loops.
4.2Sources of AI Bias¶
Historical Data Bias: AI models learn from historical data that reflects centuries of societal inequity. A hiring model trained on a company’s past decisions will learn whatever biases existed in those decisions — even if no one intended them.
Representation Bias: When training data does not adequately represent all populations. Facial recognition systems trained primarily on light-skinned faces perform dramatically worse on darker-skinned faces — not because the algorithm is inherently racist, but because the training data was not representative.
Measurement Bias: When the data used as a proxy for what we actually want to measure is flawed. Using arrest records as a proxy for crime rates introduces bias because arrest patterns reflect policing patterns — not just criminal behavior.
Aggregation Bias: When a single model is applied across different populations without accounting for their differences. A medical AI trained primarily on data from one demographic group may produce incorrect diagnoses for others.
Feedback Loop Bias: When an AI system’s outputs influence the future data it is trained on, creating a self-reinforcing cycle. Predictive policing algorithms that direct more patrols to certain neighborhoods generate more arrests in those neighborhoods, which “confirms” the algorithm’s predictions and intensifies targeting.
4.3Landmark Cases of AI Bias¶
Case Study: Amazon’s AI Recruiting Tool
In 2018, Reuters revealed that Amazon had quietly scrapped an AI recruiting tool after discovering it was systematically biased against women. The tool was trained on 10 years of hiring data — which reflected the tech industry’s male-dominated workforce. The model learned to penalize resumes containing the word “women’s” (as in “women’s chess club captain”) and to downgrade graduates of all-women’s colleges.
Key lessons:
The AI was not programmed to discriminate — it learned discrimination from biased data
Even after Amazon attempted to de-bias the model, it found other proxies for gender
The bias was not immediately obvious and was only discovered through internal audit
Amazon ultimately abandoned the tool entirely rather than risk discriminatory outcomes
Case Study: COMPAS and Criminal Justice
The Correctional Offender Management Profiling for Alternative Sanctions (COMPAS) tool scores defendants on their risk of reoffending. ProPublica’s 2016 investigation found that Black defendants were almost twice as likely as white defendants to be falsely flagged as high-risk (false positive rate: 44.9% vs. 23.5%), while white defendants were more likely to be incorrectly rated as low-risk.
Key lessons:
The algorithm did not use race as an input — but used proxies that correlated with race
Different definitions of “fairness” are mathematically incompatible — you cannot simultaneously equalize false positive rates across groups AND maintain equal predictive accuracy
Defendants often could not challenge their COMPAS scores because the algorithm was proprietary
This case sparked the entire field of algorithmic fairness research
Case Study: Healthcare Algorithm Racial Bias
A 2019 study published in Science revealed that a widely used healthcare algorithm — deployed on over 200 million patients — systematically discriminated against Black patients. The algorithm used healthcare spending as a proxy for healthcare needs. But because Black patients historically had less access to healthcare (and therefore lower spending), the algorithm concluded they were healthier than equivalently sick white patients. As a result, Black patients had to be significantly sicker than white patients to be flagged for additional care.
Key lessons:
The choice of proxy variable (spending instead of actual health) introduced systemic bias
The bias affected over 200 million patients before it was discovered
Fixing the bias required rethinking the fundamental measurement approach
Even well-intentioned algorithm design can produce discriminatory outcomes
4.4The Christian Imperative for Algorithmic Justice¶
5Fairness, Transparency, and Accountability¶
5.1Defining Fairness in AI¶
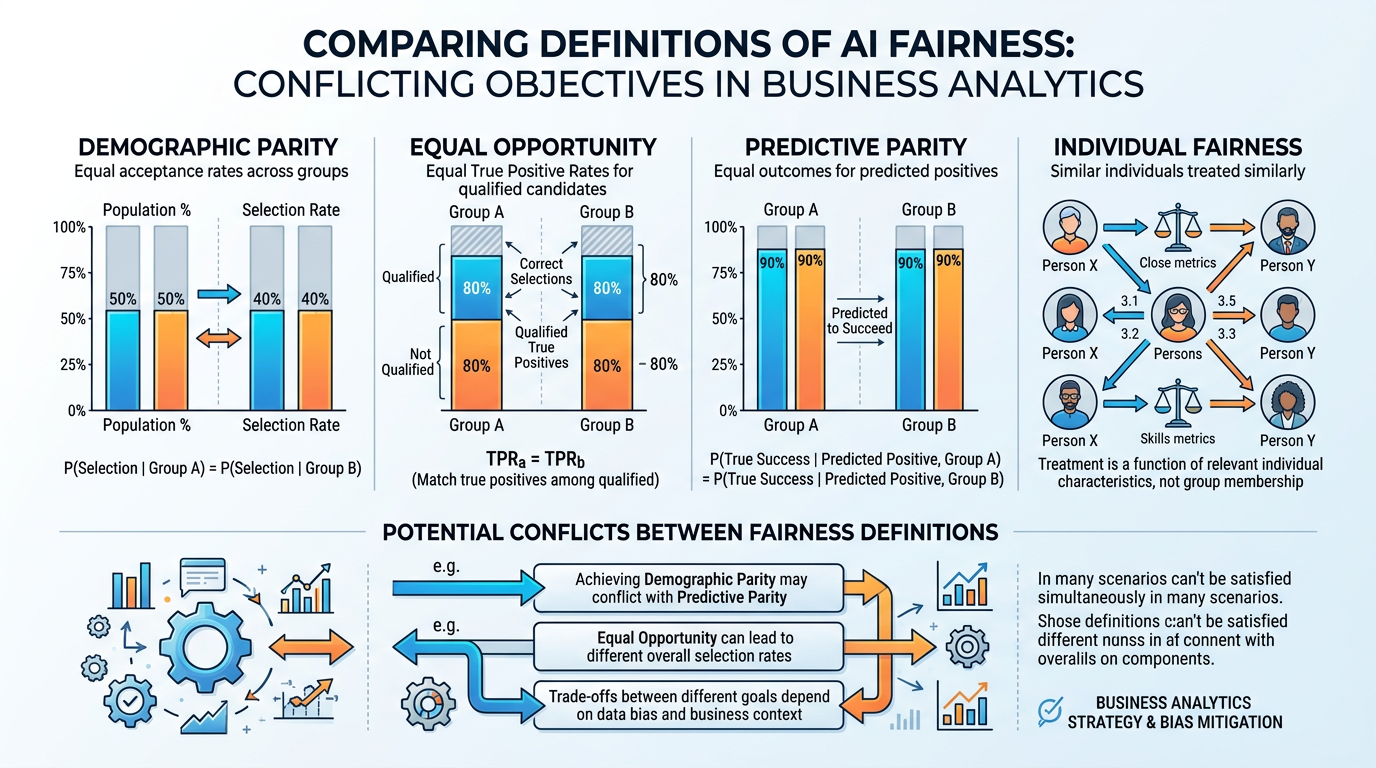
Figure 6:Four competing definitions of fairness in AI: each captures an important aspect of equity, but achieving all simultaneously is mathematically impossible — requiring ethical judgment about which fairness criteria to prioritize.
Fairness in AI is not a single concept — it encompasses multiple mathematical definitions that can conflict with each other. Understanding these definitions is essential for business leaders who must make decisions about which fairness criteria to prioritize.
Definition: An AI system achieves demographic parity when it produces equal rates of positive outcomes across all demographic groups.
Example: A hiring AI achieves demographic parity if it selects 30% of male applicants AND 30% of female applicants for interviews.
Limitation: Ignores base rates. If 40% of Group A applicants are qualified and 20% of Group B applicants are qualified (due to differing experience levels), demographic parity forces the model to either over-select from Group B or under-select from Group A.
Definition: Among people who should receive a positive outcome (the truly qualified), the AI should select them at equal rates across groups.
Example: A medical diagnostic AI has equal opportunity if it correctly identifies disease at the same rate for all racial groups — even if the overall prediction rate differs.
Limitation: Requires knowing the “ground truth” (who is truly qualified), which is often itself contested or unknown.
Definition: Among people who receive a positive prediction, the prediction should be equally accurate across groups.
Example: If a recidivism model flags someone as “high risk,” the probability that they actually reoffend should be the same regardless of their demographic group.
Limitation: Achieving predictive parity while also achieving equal false positive rates is mathematically impossible when base rates differ between groups (the Chouldechova impossibility theorem).
Definition: Similar individuals should receive similar predictions, regardless of group membership.
Example: Two loan applicants with identical financial profiles should receive the same lending decision, even if they are different races or genders.
Limitation: Defining “similar” is subjective and requires determining which features are relevant — which often reintroduces the very assumptions the fairness criterion is meant to avoid.
5.2Transparency: The Foundation of Trust¶
Transparency in AI means different things to different stakeholders:
Table 2:Levels of AI Transparency
| Level | Audience | What They Need | Example |
|---|---|---|---|
| Technical | Data scientists, auditors | Full model documentation, training data provenance, performance metrics | Model cards, datasheets |
| Organizational | Business leaders, compliance | Clear policies on AI use, governance structures, risk assessments | AI governance framework |
| User-Facing | Customers, applicants | Notice that AI is being used, right to explanation, appeal process | “This decision was assisted by AI” |
| Societal | Public, regulators, press | Impact assessments, bias audits, aggregate outcomes reporting | Annual AI transparency report |
5.3Accountability: Who Is Responsible When AI Goes Wrong?¶
The accountability question in AI is one of the most vexing challenges in the field. When an AI system causes harm — denying a qualified applicant a loan, misdiagnosing a patient, enabling a fraudulent transaction — who bears responsibility?
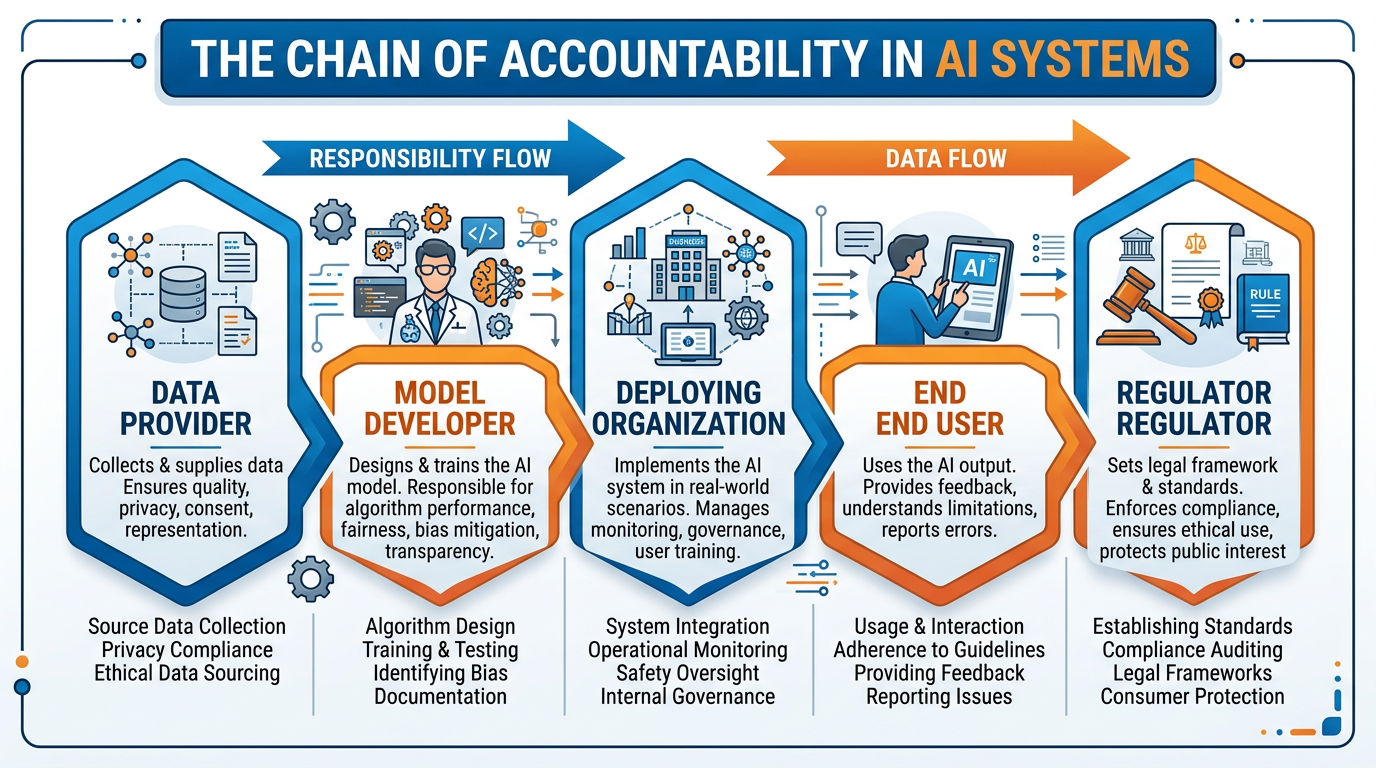
Figure 7:The AI accountability chain: responsibility for AI outcomes is distributed across multiple actors — data providers, model developers, deploying organizations, regulators, and end users — creating complex questions about who bears ultimate responsibility when harm occurs.
The company or team that built the AI model. They chose the training data, designed the architecture, and defined the objectives. But they may not control how the model is deployed or what decisions it informs.
The organization that deploys the AI in a specific context — a bank using it for lending, a hospital using it for diagnosis. They chose to use this particular tool for this particular purpose. But they may not understand the model’s limitations.
The individual who interacts with the AI output and makes the final decision (if a human is in the loop). They may rely on the AI’s recommendation without fully understanding its basis or limitations.
Government agencies that set the rules governing AI use. They must balance innovation with protection, often moving slower than technology advances.
6Data Rights in the Age of AI¶
6.1Your Data, Their Profit¶
AI systems require enormous quantities of data — and much of that data comes from individuals who may not realize how their personal information is being used. The data rights landscape involves several key tensions:
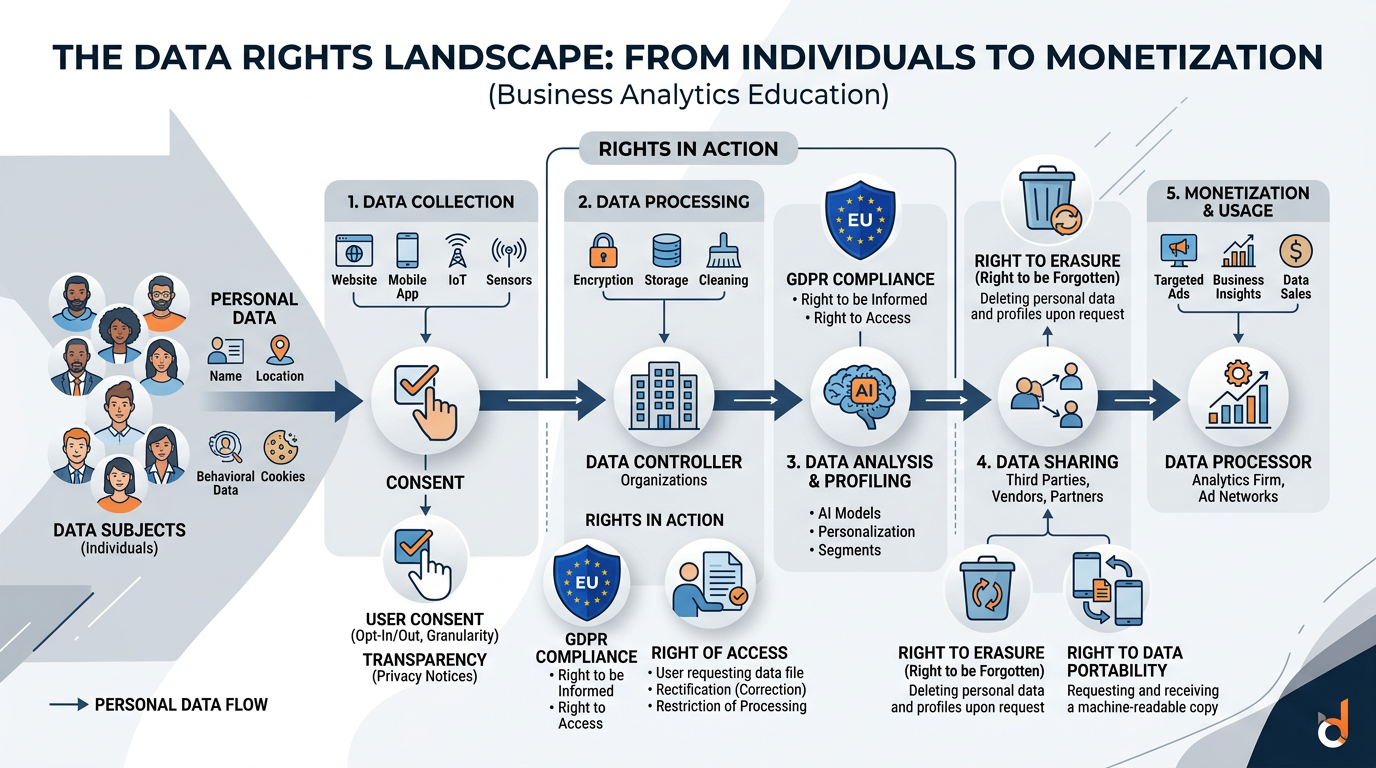
Figure 8:The data rights landscape: from the moment personal data is collected, it enters a complex ecosystem of processing, analysis, sharing, and monetization — raising fundamental questions about consent, ownership, and individual rights.
Key Data Rights Concepts:
Informed Consent: Do individuals truly understand and agree to how their data will be used? Most privacy policies are thousands of words long and written in legal language. “Consent” obtained under these conditions is questionable at best.
Data Minimization: Organizations should collect only the data they actually need, not everything they can get. Yet the AI imperative to “collect more data” directly conflicts with this principle.
Purpose Limitation: Data collected for one purpose should not be used for another without additional consent. But AI models trained on data collected for purpose A are often repurposed for purposes B, C, and D.
Right to Deletion: Individuals should be able to request deletion of their personal data. But once data has been used to train an AI model, the model “remembers” patterns from that data — making true deletion extremely difficult.
Data Portability: Individuals should be able to take their data from one service to another. This right empowers consumers but creates technical challenges for AI systems built on proprietary data ecosystems.
6.2The Surveillance Economy¶
The business model underpinning many of today’s largest tech companies — what scholar Shoshana Zuboff calls “surveillance capitalism” — involves the systematic extraction of behavioral data from individuals for the purpose of prediction and manipulation. AI is the engine that makes this business model possible.
The Data Extraction Pipeline
Collection: Every click, search, location, purchase, conversation, and biometric reading is captured
Aggregation: Data from multiple sources is combined to build comprehensive individual profiles
Analysis: AI models analyze these profiles to predict behavior, preferences, vulnerabilities, and susceptibilities
Monetization: Predictions are sold to advertisers, insurers, employers, political campaigns, and others willing to pay for insights into human behavior
Manipulation: Predictive models are used to shape behavior — nudging purchases, influencing votes, or exploiting psychological vulnerabilities
The individual whose data drives this pipeline receives “free” services but pays with their privacy, autonomy, and susceptibility to manipulation.
7AI Regulation: The Global Landscape¶
7.1The EU AI Act: Leading the World¶
The European Union’s AI Act, which entered into force in August 2024, is the world’s first comprehensive legal framework for artificial intelligence. It establishes a risk-based approach to AI governance:

Figure 9:The EU AI Act risk pyramid: AI systems are classified into four risk tiers, with regulatory requirements increasing at each level — from minimal transparency requirements to outright prohibition.
7.2US vs. EU Regulatory Approaches¶
Approach: Comprehensive, preemptive regulation
Single law (AI Act) covering all AI applications
Risk-based classification with mandatory requirements
Heavy penalties: up to €35 million or 7% of global revenue
Focus on protecting fundamental rights
Applies to any AI system used in the EU, regardless of where the developer is based
Approach: Sectoral, voluntary, industry-led
No single comprehensive AI law at the federal level
Executive Orders set guidelines but lack enforcement
Sector-specific regulations (FDA for medical AI, FTC for consumer protection)
Heavy reliance on industry self-regulation
State-level patchwork (Colorado AI Act, California proposals)
Focus on maintaining innovation leadership
Approach: Centralized, state-directed
Regulations targeting specific AI applications (deepfakes, recommendation algorithms, generative AI)
Mandatory algorithm registration with government
Content aligned with “core socialist values”
State access to AI training data and model weights
Rapid regulatory cycles — faster than EU or US
Table 3:Global AI Regulation Comparison
| Dimension | EU | USA | China |
|---|---|---|---|
| Comprehensive law | ✅ AI Act | ❌ Sectoral only | Partial (app-specific) |
| Risk classification | ✅ Four tiers | ❌ Informal | Partial |
| Facial recognition limits | ✅ Strict | Minimal | ❌ State use promoted |
| Right to explanation | ✅ GDPR + AI Act | Limited | ❌ |
| Penalties | Up to 7% global revenue | Varies by sector | Varies; includes criminal |
| Innovation focus | Moderate | High | High (state-directed) |
| Effective date | 2024-2027 (phased) | Ongoing | Ongoing |
7.3Implications for Business¶
8Building Ethical AI: A Framework for Action¶
8.1The FATE Framework¶
Researchers and practitioners have converged on four pillars of ethical AI, collectively known as the FATE framework:
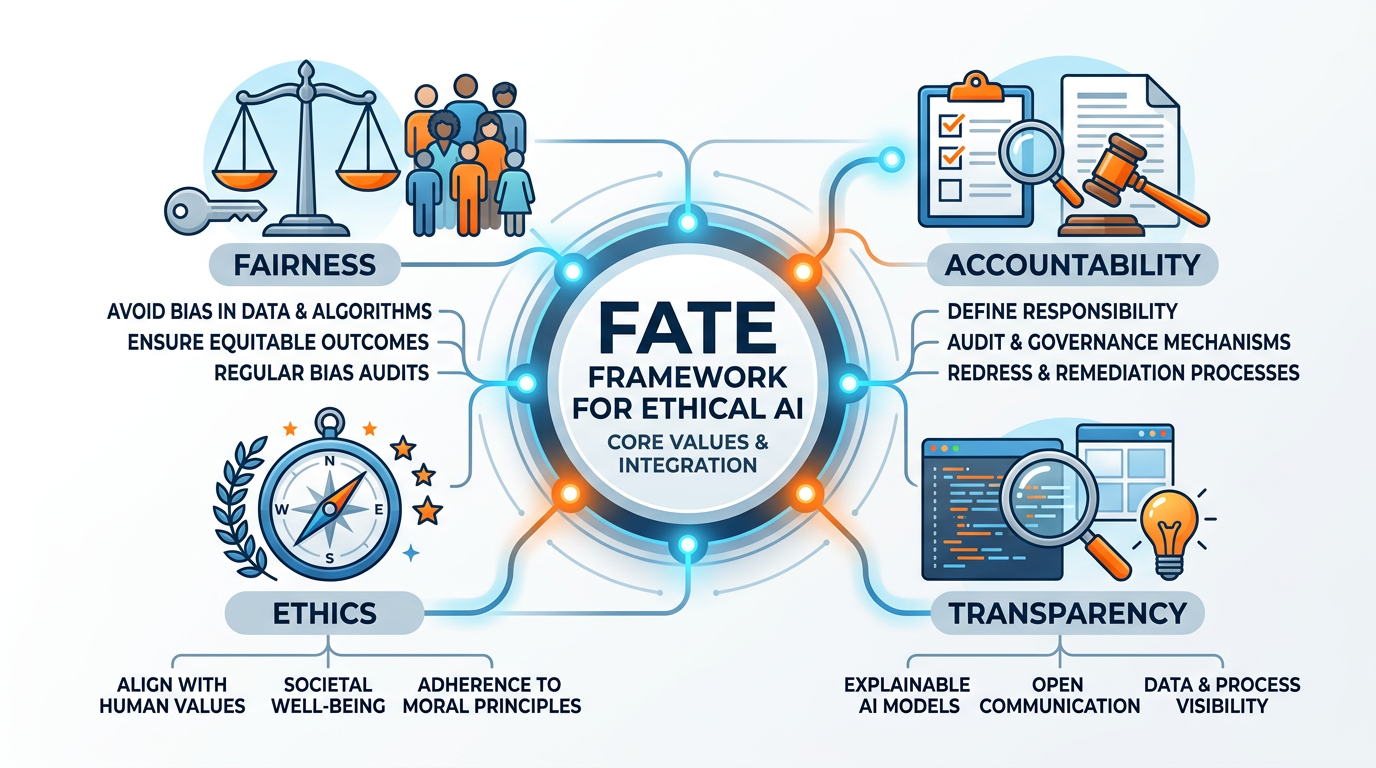
Figure 10:The FATE framework for ethical AI: four interconnected pillars that together form the foundation for responsible AI development and deployment in business contexts.
Audit AI systems for bias before and after deployment
Test performance across demographic groups
Establish fairness metrics appropriate to the context
Include diverse perspectives in AI design teams
Provide recourse for unfair outcomes
Designate responsible individuals for each AI system
Document decision-making processes and rationale
Conduct regular impact assessments
Establish incident response procedures
Maintain audit trails for AI decisions
Disclose when AI is being used in decisions
Provide meaningful explanations of AI-driven outcomes
Publish model cards and system documentation
Share performance metrics and known limitations
Enable external auditing
Align AI deployment with organizational values
Conduct ethical review before launching AI systems
Consider impacts on vulnerable populations
Respect privacy and data rights
Engage stakeholders in AI governance
8.2Practical Steps for Responsible AI Deployment¶
Diverse teams: Ensure AI development teams include diverse perspectives — gender, race, age, discipline, and faith background. Homogeneous teams are more likely to create biased systems because they share blind spots.
Bias audits: Before deploying any AI system that affects people’s lives, conduct rigorous testing for bias across all relevant demographic dimensions. Use established frameworks like IBM’s AI Fairness 360 or Google’s What-If Tool.
Impact assessments: Evaluate the potential harms of an AI system before deployment, not after. Who could be harmed? How severely? What safeguards exist? This is analogous to environmental impact assessments for construction projects.
Human oversight: Maintain meaningful human oversight of AI decisions, particularly in high-stakes contexts. “Human in the loop” should mean genuine review authority, not rubber-stamping algorithmic recommendations.
Continuous monitoring: Bias can emerge over time as data distributions shift. Implement ongoing monitoring of AI system performance across demographic groups and establish triggers for investigation and correction.
Stakeholder engagement: Involve affected communities in AI governance decisions. People who will be impacted by AI systems should have a voice in how those systems are designed, deployed, and evaluated.
9Module 6 Activities¶
9.1Discussion: Who Is Responsible When AI Goes Wrong?¶
9.2Written Analysis: AI Bias Audit Report¶
9.3Reflection: Truth, Deception, and AI¶
9.4Hands-On Activity 1: AI Ethics Scenario Analysis with Gemini¶
9.5Hands-On Activity 2: Building an AI Ethics Resource Library with NotebookLM¶
10Chapter Summary¶
AI ethics, bias, and digital responsibility represent the most critical challenges facing business leaders in the age of artificial intelligence. In this chapter, we explored:
How deepfakes are created and their escalating threat
The information disorder spectrum: misinformation, disinformation, malinformation
AI-generated fake news at scale
The epistemological crisis: when seeing is no longer believing
Why complex AI models cannot explain their decisions
The real-world consequences in lending, hiring, healthcare, and justice
Explainable AI (XAI) approaches: LIME, SHAP, attention, counterfactuals
The business and regulatory necessity of AI transparency
Sources of bias: historical data, representation, measurement, aggregation, feedback loops
Landmark cases: Amazon hiring, COMPAS, healthcare racial bias
Multiple definitions of fairness and their mathematical incompatibility
The Christian imperative for algorithmic justice
The EU AI Act’s risk-based approach
US vs. EU vs. China regulatory comparison
Data rights in the age of AI
The FATE framework for ethical AI deployment
11Key Terms¶
Deepfake Synthetic media created by AI to convincingly depict events, statements, or appearances that never actually occurred.
Misinformation False information shared without the intent to deceive — the person sharing it believes it to be true.
Disinformation False information deliberately created and shared with the intent to deceive, manipulate, or cause harm.
Malinformation Genuine information shared with the intent to cause harm, such as leaked private data or decontextualized true statements.
Black Box Problem The inability to understand or explain how complex AI systems arrive at their decisions due to the opacity of deep learning models.
Explainable AI (XAI) Methods and techniques that make AI decision processes understandable to humans while maintaining high performance.
Algorithmic Bias Systematically unfair outcomes produced by AI systems that privilege certain groups while disadvantaging others.
Demographic Parity A fairness criterion requiring equal rates of positive outcomes across all demographic groups.
Equal Opportunity A fairness criterion requiring equal true positive rates across demographic groups.
Predictive Parity A fairness criterion requiring equal precision (positive predictive value) across demographic groups.
FATE Framework An ethical AI framework built on four pillars: Fairness, Accountability, Transparency, and Ethics.
Content Credentials (C2PA) A standard for digitally signing media at the point of creation, recording provenance and modification history.
Surveillance Capitalism An economic system built on the extraction and monetization of personal behavioral data for prediction and influence.
EU AI Act The European Union’s comprehensive legal framework for artificial intelligence, establishing a risk-based approach to AI governance.
Liar’s Dividend The phenomenon where the existence of deepfake technology allows people to dismiss genuine evidence as fabricated.
LIME Local Interpretable Model-Agnostic Explanations — a technique that explains individual AI predictions using simplified local models.
SHAP SHapley Additive exPlanations — a game-theory-based method for determining the contribution of each feature to an AI prediction.