How to use this addendum: Complete the assessment once before the course begins (referenced in the Prologue) and again after Chapter 13. Your score delta is the measure of what the two days delivered. The online version lives at docs
.com /forms /d /1QQJJ4eZq1kpk5lRWL4TL1nxIeogpz1SkhxgzQpPOF44. This printed version exists so you can complete it on paper, mark it up, and return to it later.
1Overview¶
The AI Readiness Gap Assessment measures your current AI maturity across five dimensions that separate analysts who occasionally use AI from analysts who operate with a synthetic workforce. There are no trick questions. The honest answer is always the most useful one.
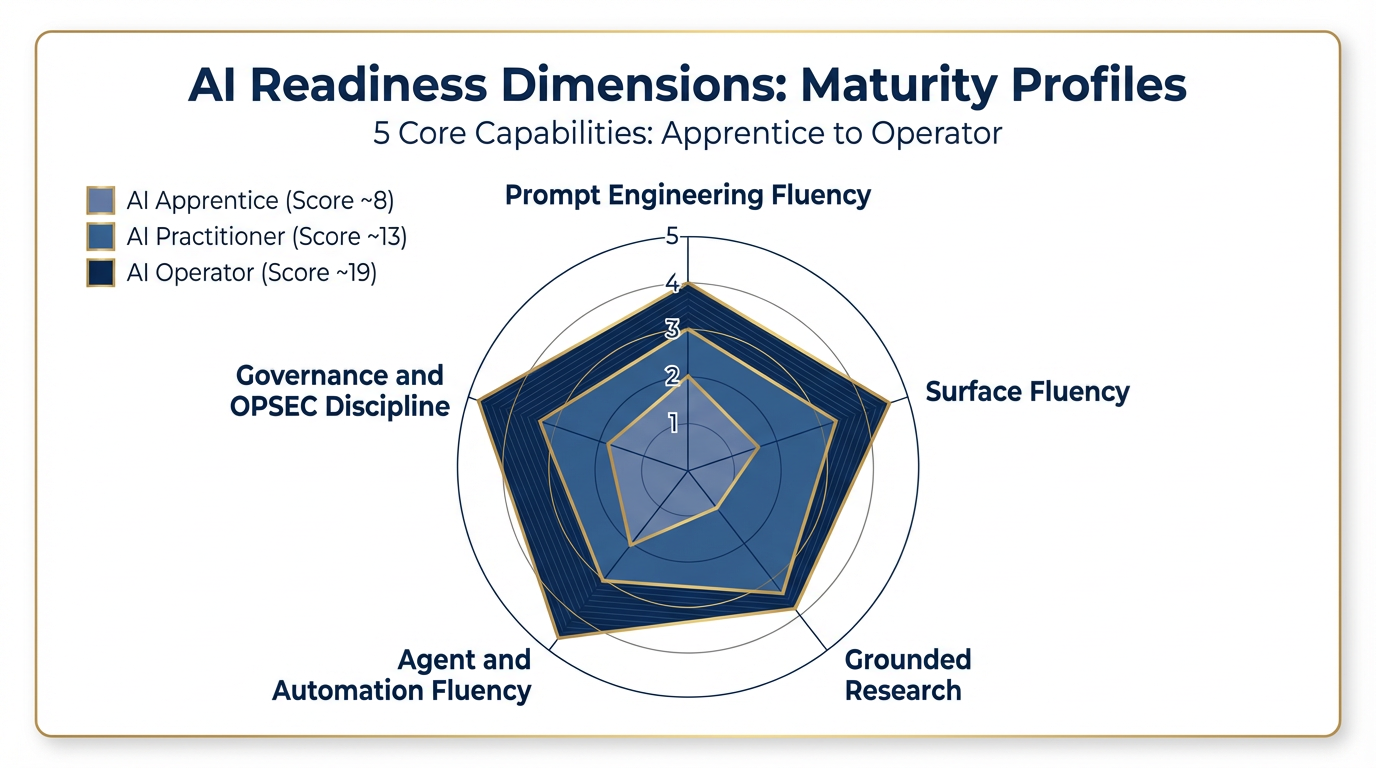
Figure 1:The five dimensions of AI readiness. Each axis represents one dimension scored 1–5. The shaded profiles show an AI Apprentice (inner polygon), AI Practitioner (middle), and AI Operator (outer polygon). Most participants start in the Apprentice–Practitioner range.
The five dimensions:
| # | Dimension | What It Measures |
|---|---|---|
| 1 | Prompt Engineering Fluency | How precisely you direct AI output |
| 2 | Surface Fluency | How deliberately you choose which tool to use |
| 3 | Grounded Research | How rigorously you verify what AI tells you |
| 4 | Agent and Automation Fluency | How much AI runs without your constant attention |
| 5 | Governance and OPSEC Discipline | How safely and accountably you operate |
Each dimension is scored 1 through 5. Total possible score: 25 points.
2The Assessment¶
For each dimension, read all five descriptions carefully. Select the one statement that best describes your current, consistent practice — not your best day, and not your aspirational state. Where you actually are.
Record your score in the boxes at the end of this addendum.
Dimension 1: Prompt Engineering Fluency¶
How you communicate with AI determines what you get back. This dimension measures the precision and intentionality of your prompts.
Score 1 — Search Engine Mode
I use AI like a search engine. I type short queries, accept the first output I get, and move on. I don’t think much about how I’m framing the request.
Score 2 — Occasional Context
I occasionally add context to my prompts — a sentence or two about what I need — but I don’t follow a consistent structure. My prompts vary widely in quality.
Score 3 — Structured Prompting
I consistently use Role/Context/Task structure (or similar). I tell the AI who it is, what the situation is, and what I need. My prompts produce reliably better output than they used to.
Score 4 — Template Systems
I write reusable prompt templates for my most common tasks and refine them based on output quality over time. I have a personal library of prompts I return to regularly.
Score 5 — Prompt Architecture
I design prompt systems with personas, constraints, output schemas, and few-shot examples. I can build prompt infrastructure that other people use, and I understand why each element affects output the way it does.
Dimension 1 Score: ___
Dimension 2: Surface Fluency¶
Different AI tools excel at different tasks. This dimension measures your ability to match the right tool to the right job.
Score 1 — Single Surface
I use one AI tool for everything — usually ChatGPT, Copilot, or whatever came pre-installed. I don’t think much about whether a different tool might be better suited for a given task.
Score 2 — Multiple Tools, No Strategy
I use two or three AI tools but don’t have a clear framework for choosing between them. My selection is more habit than deliberate decision.
Score 3 — Task-Based Selection
I consciously select surfaces based on task type. I know, for example, that document analysis calls for a different tool than code generation or image creation, and I choose accordingly.
Score 4 — Personal Decision Matrix
I have a personal decision matrix — written or mental — that I apply daily. I can quickly assess a task and route it to the optimal tool. I update my matrix when I discover a tool’s limitations.
Score 5 — Teacher and Updater
I can train others on surface selection. I track emerging tools, update my matrix as the landscape shifts, and help my team avoid the single-surface trap. I know not just which tool to use, but why.
Dimension 2 Score: ___
Dimension 3: Grounded Research¶
AI systems hallucinate. This dimension measures how rigorously you verify what AI tells you before it influences a decision or reaches a customer.
Score 1 — Full Trust
I take AI outputs at face value. If the AI says it, I assume it’s correct. I rarely verify claims independently, especially when the output sounds authoritative.
Score 2 — Selective Verification
I occasionally verify key claims — especially numbers or specific facts — but I don’t have a consistent process for doing so. I rely on judgment about what seems suspicious.
Score 3 — Grounded Analysis
I use NotebookLM, RAG tools, or direct document uploads to anchor AI analysis in source material. I know the difference between AI reasoning from its training data and AI reasoning from documents I provided.
Score 4 — Audit Trail Discipline
I consistently apply source discipline for any work that will influence a customer-facing decision. I document where information came from and flag AI contributions clearly. I could reconstruct my reasoning trail if asked.
Score 5 — Workflow Designer and Teacher
I design grounded RAG workflows and teach source verification discipline to my team. I understand the technical architecture of grounded retrieval, not just how to use it as a feature. My team’s outputs are traceable by design.
Dimension 3 Score: ___
Dimension 4: Agent and Automation Fluency¶
The highest-leverage AI practitioners aren’t just better prompt writers — they’ve offloaded entire workflows to automated systems. This dimension measures how much AI runs without your constant supervision.
Score 1 — No Automation
I have never used an AI agent or automated AI workflow. Every AI interaction I have is manual and one-shot. AI is a tool I pick up, use once, and put down.
Score 2 — Experimentation Only
I’ve experimented with agents or automated workflows — tried a demo, built something in a tutorial — but I don’t use them in production work. Nothing is running autonomously in my regular practice.
Score 3 — One Running Workflow
I have at least one automated AI workflow running in my regular practice. It might be a scheduled summary, an automated research pipeline, or a custom agent that handles a specific recurring task.
Score 4 — Personal Skill Library
I have a personal skill library — a set of reusable automated workflows — that I deploy across multiple contexts. I think about my work in terms of what I can automate and what still requires human judgment.
Score 5 — Multi-Agent Supervision
I supervise multi-agent pipelines where AI systems hand off work to each other with minimal human intervention. I maintain a team skill library and help colleagues build and adopt automated workflows. I can diagnose and improve agent behavior.
Dimension 4 Score: ___
Dimension 5: Governance and OPSEC Discipline¶
AI tools create data exposure risks, compliance obligations, and accountability questions. This dimension measures how deliberately you manage those risks in daily practice.
Score 1 — No Awareness
I don’t think about AI governance in my daily work. I use whatever tools are convenient without considering data handling, compliance, or accountability.
Score 2 — Informal Avoidance
I avoid putting obviously sensitive information into AI tools — I know that much — but I don’t have a formal process. My caution is ad hoc and inconsistent.
Score 3 — Personal OPSEC Checklist
I have a personal OPSEC checklist I apply before using AI tools on sensitive work. I know what categories of information to keep out of which tools, and I apply that discipline consistently.
Score 4 — FedRAMP Awareness and Attribution
I verify FedRAMP authorization status for AI tools before deploying them in any context involving government or regulated data. I document AI contributions to my work products and can clearly distinguish AI-generated content from human-authored content.
Score 5 — Written Governance Plan
I have a written governance plan for my AI practice — not a policy document I inherited, but one I actively maintain and own. I contribute to team-level governance conversations and help colleagues think through their AI risk posture. I treat governance as a professional responsibility, not a compliance checkbox.
Dimension 5 Score: ___
3Score Your Assessment¶
Transfer your scores to the table below. Add them for your total.
| Dimension | Pre-Course Score | Post-Course Score | Delta |
|---|---|---|---|
| 1. Prompt Engineering Fluency | __ | __ | __ |
| 2. Surface Fluency | __ | __ | __ |
| 3. Grounded Research | __ | __ | __ |
| 4. Agent and Automation Fluency | __ | __ | __ |
| 5. Governance and OPSEC Discipline | __ | __ | __ |
| Total | __ | __ | __ |
4Score Interpretation¶
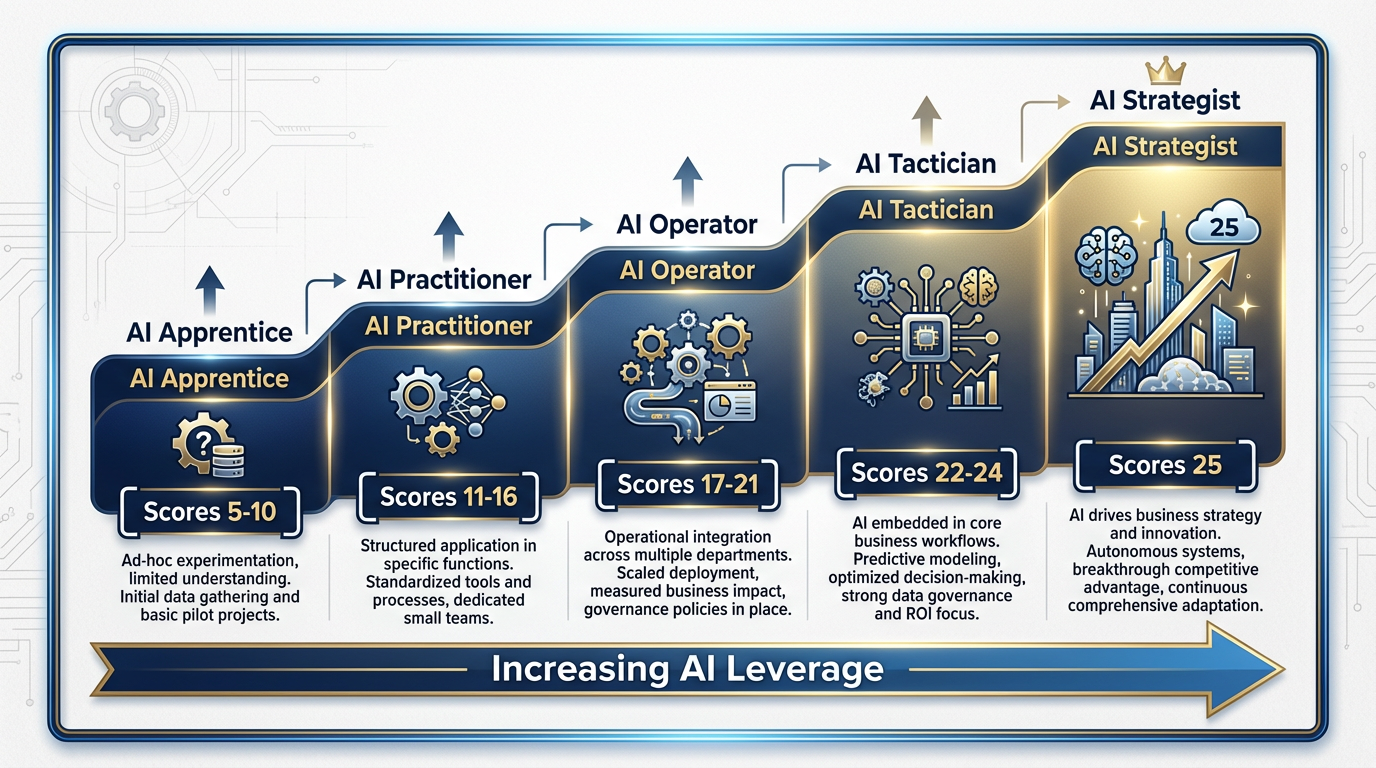
Figure 2:The five maturity levels. Most course participants arrive in the Apprentice–Practitioner range (scores 5–16) and leave in the Practitioner–Operator range (scores 11–21).
5–10 — AI Apprentice You are in the foundation stage. You use AI tools but haven’t yet developed a systematic approach to any of the five dimensions. The good news: every point of growth from here produces outsized returns. The course is designed for exactly where you are.
11–16 — AI Practitioner You are a functional daily user of AI. You’ve moved beyond search-engine mode in at least a few dimensions, but your practice is uneven. Some dimensions are stronger than others. The course will help you identify which gaps cost you the most and close them systematically.
17–21 — AI Operator You are consistent and disciplined. You’ve begun to automate and you think deliberately about tool selection and verification. Your next frontier is either governance depth (ensuring your practice is defensible) or agent leverage (building the systems that multiply your output).
22–24 — AI Tactician You are automation-capable and governance-aware. You are likely influencing how your team uses AI, whether formally or not. The course will push you toward the organizational layer — what it means to build AI capability in a team, not just in yourself.
25 — AI Strategist You are operating at the synthetic workforce level. You teach, build, and maintain systems that other people depend on. If you score 25 before the course, your value in the room is different from everyone else’s: you are a multiplier for your colleagues. Your job during the two days is to lift the people around you.
5The Pre/Post Delta¶
The delta — the difference between your pre-course and post-course scores — is the most honest measure of what the course delivered.
A typical participant moves 4–6 points across the two days.
That doesn’t mean you’ll close every gap. A two-day course cannot fully develop dimension 4 (Agent and Automation Fluency) if you’ve never built a workflow before — that skill requires practice over time. What the course can do is give you the mental models, the vocabulary, and the first concrete moves so that the 90 days after the course produce real progress.
If your delta is less than 3 points, we want to know why. That feedback makes the course better.
If your delta is more than 7 points, you started lower than you thought, or you arrived ready to absorb a large amount quickly. Either way, that’s worth noting.
6The 90-Day Target¶
The course is two days. The practice is the rest of your career. This section gives you a concrete, actionable target for each dimension based on where you are now. The goal is one level up in 90 days.
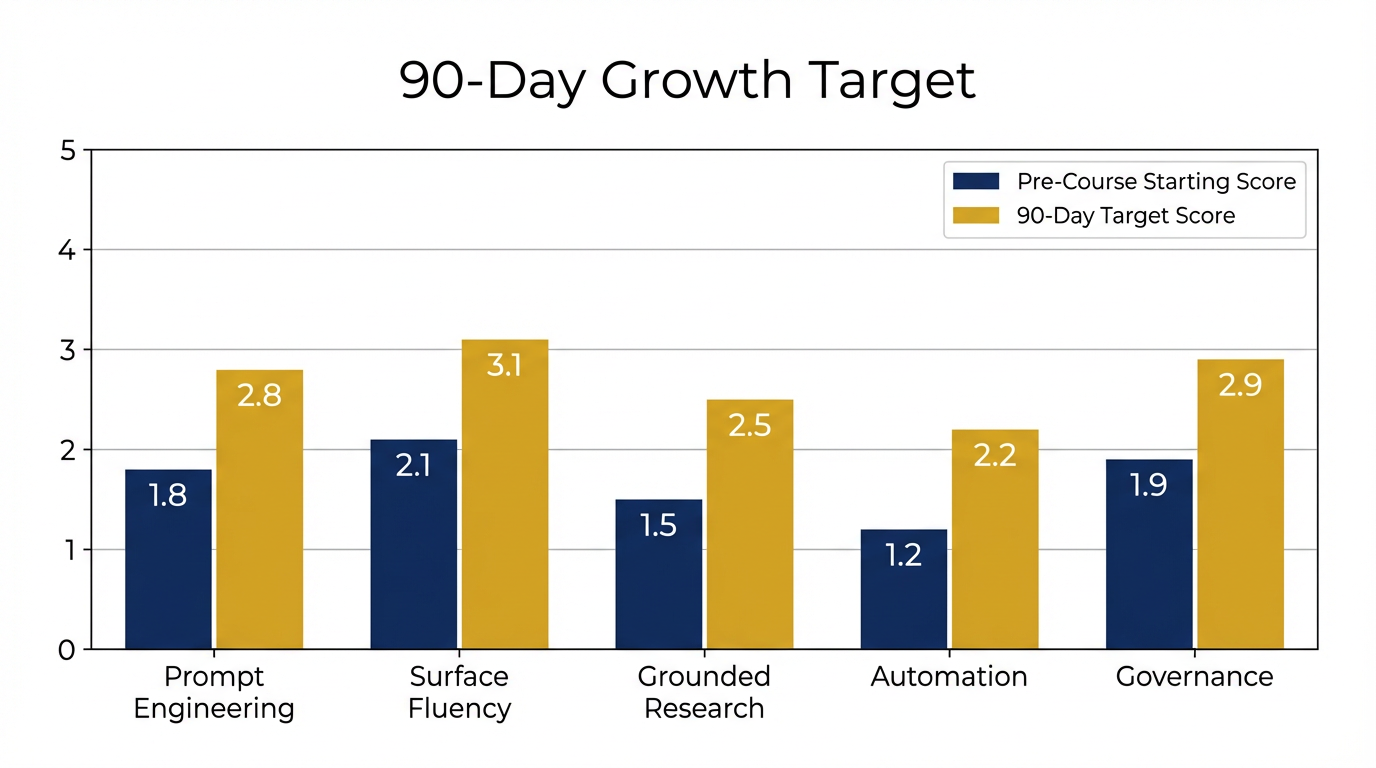
Figure 3:The 90-day growth path. The left bars represent where most participants start (pre-course); the right bars represent achievable 90-day targets with deliberate practice. No dimension requires a full re-architecture — each step up requires one or two specific habit changes.
Dimension 1: Prompt Engineering Fluency¶
If you scored 1 → Target 2: Before you submit any AI prompt, add one sentence of context: who you are, what you’re working on, what format you need. That single habit will visibly improve your outputs within a week.
If you scored 2 → Target 3: Adopt the Role/Context/Task template and use it for every non-trivial prompt for 30 days. After 30 days, it becomes automatic. Keep a note of prompts that produced unusually good results — those are the seeds of your template library.
If you scored 3 → Target 4: Pick your three most common AI tasks and write a formal template for each. Store them somewhere you’ll actually use them (a pinned note, a browser bookmark, a document). Refine each template at least once based on output quality.
If you scored 4 → Target 5: Build one prompt system — not a single prompt, but a structured sequence with a persona, output schema, and at least two examples. Use it on a real project. Then teach it to one colleague.
Dimension 2: Surface Fluency¶
If you scored 1 → Target 2: In the next 30 days, deliberately use a second AI tool for a task you’d normally handle in your default tool. Notice the difference. You don’t need a framework yet — just exposure.
If you scored 2 → Target 3: Write down five task types you handle regularly (research, writing, analysis, code, images). For each, decide which tool you’ll use and why. That list is the beginning of your decision matrix.
If you scored 3 → Target 4: Formalize your decision matrix into a simple document or table. Add a column for “when NOT to use this tool.” Review it monthly and update it when a tool surprises you.
If you scored 4 → Target 5: Run a 20-minute “surface selection” session with your team. Walk through three real tasks from recent work and explain your tool selection reasoning. The act of teaching it will sharpen your own thinking.
Dimension 3: Grounded Research¶
If you scored 1 → Target 2: For the next 30 days, verify every specific claim (number, name, date, policy) before acting on it. You don’t need a system yet — just the habit of pausing to check.
If you scored 2 → Target 3: Open a NotebookLM project and use it for your next significant research task. Upload the relevant documents and ask your questions against those documents, not against the model’s general knowledge. Notice the quality difference.
If you scored 3 → Target 4: For any AI-assisted work that will influence a real decision or go to a customer, add a “sources” section to your output and document where each key claim came from. Do this for 60 days until it’s automatic.
If you scored 4 → Target 5: Design a grounded research workflow that a colleague could follow — not just your personal habit, but a documented process with tool recommendations, verification steps, and output standards. Walk one colleague through it.
Dimension 4: Agent and Automation Fluency¶
If you scored 1 → Target 2: In the next 30 days, complete one agent or automation experiment — even a simple one. A scheduled digest, a no-code Zapier workflow, or a basic agent task in any tool that supports it. The goal is first contact, not mastery.
If you scored 2 → Target 3: Take one recurring task you currently do manually and automate it. It can be small — a weekly summary, a data pull, a report format. Get it running. Then leave it running for 30 days without touching it.
If you scored 3 → Target 4: Document your existing workflow. Then build a second one in a different domain. Two running workflows with documentation is the beginning of a personal skill library.
If you scored 4 → Target 5: Identify a workflow that involves two or more agents handing off work to each other. Design it, build a prototype, and supervise it through at least five real runs. Then document what failed and what you adjusted.
Dimension 5: Governance and OPSEC Discipline¶
If you scored 1 → Target 2: Write down three categories of information you will never put into an AI tool that doesn’t have enterprise-grade data handling. Personal identifiers, classified information, unreleased financial data — whatever applies to your role. That list is your floor.
If you scored 2 → Target 3: Build a simple OPSEC checklist — five questions you ask before using any AI tool on work that involves sensitive information. Laminate it. Put it somewhere visible. Use it.
If you scored 3 → Target 4: For every new AI tool you consider adopting, check its FedRAMP status and data retention policies before you use it. Document that check. If you produce AI-assisted work products, add a brief note indicating which portions were AI-assisted.
If you scored 4 → Target 5: Write your personal AI governance plan — not a company document, but your own. It should cover: which tools you use and why, what data you will and won’t put into each, how you attribute AI contributions, and how you stay current on policy changes. Share it with at least one colleague and invite their critique.
7Notes¶
Use this space to record your pre-course scores, post-course scores, and any observations about specific dimensions you want to prioritize.
___________________________________________________________________
___________________________________________________________________
___________________________________________________________________
___________________________________________________________________
___________________________________________________________________
Pre-Course Total: ____ / 25 → Level: ________________
Post-Course Total: ____ / 25 → Level: ________________
Delta: ____ points
My 90-Day Priority Dimension: ________________________
Addendum B of “AI for Lukos Professionals — The Wolfpack’s Edge.” Developed by Dr. Ernesto Lee and Professor Carlos Marquez, Miami Dade College, School of Business.